













零成本突破多模態大模型瓶頸!多所美國頂尖高校華人團隊,聯合推出自增強技術CSR
多模態大模型展現出了多種多樣的能力,這些能力都通過SFT和預訓練從龐大的訓練數據集中學習。
但是模態之間的簡單對齊可能會使得模型存在幻覺,細粒度圖像感知能力差等各種問題。
已有的多模態大模型對齊方案一般采用DPO,POVID等偏好優化方法,或是蒸餾 GPT-4等昂貴閉源模型的方式來提升模型能力。
這些方法大多需要外源模型數據,這些數據構造存在很多問題,一是需要昂貴的價格,二是缺乏質量和多樣性的保證。
再者說,這真的適合需要提升模型本身的分布偏好嗎?
在Calibrated Self-Rewarding Vision Language Models文中,通過模型自身輸出概率證明了,外來模型構造的偏好數據可能不適合用于模型的偏好學習,相較于模型自身的response,外源模型所構造的數據模型自己說出的概率很小,簡單來說對于偏好數據中的負樣本模型并不會犯一樣的錯誤,對于偏好數據中的正樣本模型也不會講出那么好的response。
這種偏好數據用于偏好學習可能會引入模型自身分布的偏差導致其他錯誤,同時因為模型自身說同樣話的概率低,用這樣的數據來偏好學習增強模型收益很小。

同時傳統純文本大模型領域的Self-rewarding范式存在一定缺陷。

在此前self rewarding提供reward的模型是模型自身,當模型自身無法準確分辨偏好、所具有的知識不夠強大的時候,它所提供的反饋可能不夠精準或者沒用導致所更新的模型的分布無法向著目標分布更新。
為了解決上述問題,來自UNC ,芝加哥大學,UMD和羅格斯大學的研究團隊提出了Calibrated Self-Rewarding(CSR),多模態大模型的自我增強因為會存在一個真實圖像的參照,這會使得self-rewarding的過程更加可靠。

論文地址: https://arxiv.org/pdf/2405.14622
項目地址:https://github.com/YiyangZhou/CSR
項目頁面:https://dongjie-cheng.github.io/CSR.html
整個Calibrated Self-Rewarding(CSR)框架如下:
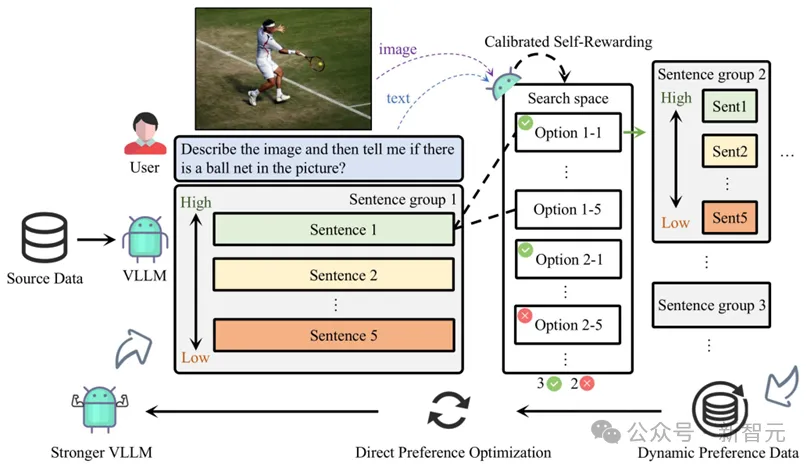
1. 通過模型本身在beam search過程中的輸出構造偏好數據對,過程中的獎勵來自于校準的自我獎勵:LVLM對于每句話的自我生成概率 + 結合視覺約束獎勵,用于獎勵校準。
2. 基于每一輪構造的偏好數據在線通過DPO迭代學習。
實驗
CSR相較于數據驅動的偏好學習對齊方法和模型自我反饋的方法均有較大提升。
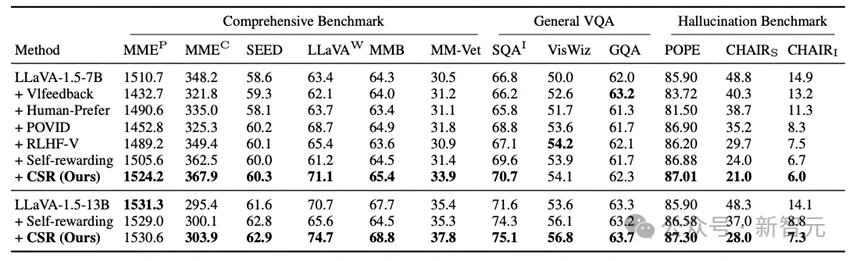
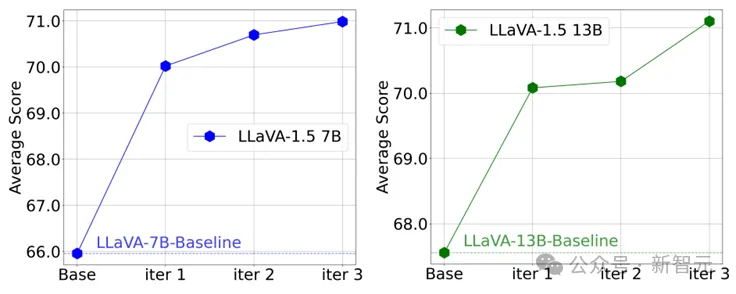
更值得注意的是,在CSR多輪在線迭代過程中,模型能逐步提升自我能力!可以看到在多個輪次中以LLaVA-1.5為例,模型在多個benchmark上的均分逐步提升。
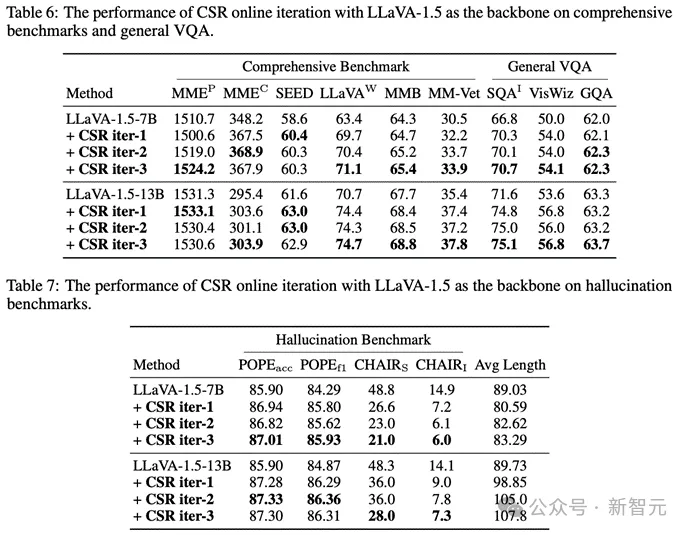
同時也可以看到特別是幻覺,在多輪迭代中是逐步減少的:
同時CSR也適用于其他模型,例如Vila:

那么在Calibrated Self-Rewarding(CSR)的過程中究竟發生了什么呢?通過可視化經過CSR迭代前后模型自身的正樣本和負樣本輸出可以發現,經過多輪CSR學習后,模型自身說出的回復會有更高的分數:這代表模型的response更加符合圖像信息;同時負樣本和正樣本的gap更小:這說明模型所輸出的負樣本傾向于正樣本,模型的誤差和性能下界提升。

通過可視化attention可以看到,CSR能使得LVLM更加偏重于視覺模型,同時能緩解文本attention中存在的上下文依賴問題。




























