基于 Python 和 HuggingFace Transformers 的目標檢測
YOLO!如果你對機器學習感興趣,這個術語一定不陌生。確實,You Only Look Once已經成為過去幾年中目標檢測的默認方法之一。受到卷積神經網絡取得的進展推動,許多版本的目標檢測方法已經被創建。然而,近年來,一個競爭對手出現在了視野中——那就是在計算機視覺中使用基于Transformer的模型。更具體地說,是使用Transformer進行目標檢測。
在今天的教程中,你將了解到這種類型的Transformer模型。你還將學會使用Python、一個默認的Transformer模型和HuggingFace Transformers庫創建自己的目標檢測流程。本文將按照下列步驟講解:
- 了解目標檢測可以用來做什么
- 了解當Transformer用于目標檢測時它們是如何工作的
- 已經使用Python和HuggingFace Transformers實現了基于Transformer模型的(圖像)目標檢測流程

什么是目標檢測?
環顧四周,很可能你會看到很多東西——可能是一臺電腦顯示器、一個鍵盤和鼠標,或者當你在移動瀏覽器中瀏覽時,是一部智能手機。這些都是物體,是特定類別的實例。例如,在下面的圖像中,我們看到一個人類類別的實例。我們還看到了許多瓶子類別的實例。雖然類別是藍圖,但物體是真實存在的,具有許多獨特的特征,同時因為共享的特征而屬于類別的成員。
在圖片和視頻中,我們看到了許多這樣的物體。例如,當你拍攝交通視頻時,很可能會看到許多行人、汽車、自行車等實例。知道它們在圖像中存在是非常有益的。為什么呢?因為你可以計數它們,舉一個例子。這可以讓你對社區的擁擠程度有所了解。另一個例子是在繁忙地區檢測到一個停車位,讓你可以停車。
目標檢測和Transformer
傳統上,目標檢測是通過卷積神經網絡來實現的。通常,它們的架構是專門針對目標檢測設計的,因為它們將圖像作為輸入并輸出圖像的邊界框。如果你熟悉神經網絡,你就知道卷積網絡在學習圖像中的重要特征方面非常有用,并且它們是空間不變的——換句話說,學習對象在圖像中的位置或大小是無關緊要的。如果網絡能夠看到對象的特征,并將其與特定類別關聯起來,那么它就能識別出來。例如,許多不同的貓都可以被識別為貓類的實例。
然而,最近,在深度學習領域,特別是自然語言處理領域,Transformer架構引起了人們的極大關注。Transformer通過將輸入編碼為高維狀態,然后將其解碼回所需的輸出來工作。通過聰明地使用自注意力的概念,Transformer不僅可以學習檢測特定模式,還可以學習將這些模式與其他模式關聯起來。在上面的貓的例子中,舉一個例子,Transformer可以學習將貓與其特征點(例如沙發)關聯起來。
如果Transformer可以用于圖像分類,那么將它們用于目標檢測只是更進一步的一步。Carion等人(2020年)已經表明,事實上可以使用基于Transformer的架構來實現這一點。在他們的工作《使用Transformer進行端到端目標檢測》中,他們介紹了檢測Transformer或DeTr,我們將在今天創建我們的目標檢測流程中使用它。
它的工作原理如下,并且甚至沒有完全放棄CNN:
- 使用卷積神經網絡從輸入圖像中提取重要特征。這些特征像語言Transformer中一樣進行位置編碼,以幫助神經網絡學習這些特征在圖像中的位置。
- 將輸入展平,并使用transformer編碼器和注意力將其編碼為中間狀態。
- 變換器解碼器的輸入是這個狀態和在訓練過程中獲得的一組學習的對象查詢。你可以想象它們是在問:“這里是否有一個對象,因為我以前在許多情況下看到過?”,這將通過使用中間狀態來回答。
- 事實上,解碼器的輸出是通過多個預測頭進行的一組預測:每個查詢一個。由于DeTr中查詢的數量默認設置為100,因此它一次只能預測100個對象,除非你對其進行不同的配置。

Transformer架構
HuggingFace Transformers及其目標檢測流程
現在你已經了解了DeTr的工作原理,是時候使用它來創建一個真實的目標檢測流程了!我們將使用HuggingFace Transformers來實現這個目標,這是為了使NLP和計算機視覺Transformer的工作變得簡單而構建的。事實上,使用它非常簡單,因為使用它只需要加載ObjectDetectionPipeline——它默認加載了一個使用ResNet-50骨干訓練的DeTr Transformer以生成圖像特征。
ObjectDetectionPipeline可以很容易地初始化為一個pipeline實例...換句話說,通過pipeline("object-detection")的方式,我們將在下面的示例中看到這一點。當你沒有提供其他輸入時,這就是根據GitHub(n.d.)初始化管道的方式:
"object-detection": {
"impl": ObjectDetectionPipeline,
"tf": (),
"pt": (AutoModelForObjectDetection,) if is_torch_available() else (),
"default": {"model": {"pt": "facebook/detr-resnet-50"}},
"type": "image",
},毫不奇怪,使用了一個ObjectDetectionPipeline實例,它專門用于目標檢測。在HuggingFace Transformers的PyTorch版本中,用于此目的的是AutoModelForObjectDetection。正如你所了解的,Facebook/detr-resnet-50模型是默認用于獲取圖像特征的:
DEtection TRansformer(DETR)模型在COCO 2017目標檢測(118張帶標注圖像)上進行了端到端訓練。它是由Carrion等人在論文《使用Transformer進行端到端目標檢測》中介紹的。
HuggingFace (n.d.)
COCO數據集(上下文中的常見對象)是用于目標檢測模型的標準數據集之一,并且已用于訓練此模型。不用擔心,你顯然也可以訓練自己基于DeTr的模型!要使用ObjectDetectionPipeline,安裝包含PyTorch圖像模型的timm包是很重要的。確保在尚未安裝時運行以下命令:
pip install timm使用Python實現簡單的目標檢測流程
現在讓我們來看看如何使用Python實現簡單的目標檢測解決方案。回想一下,我們使用的是HuggingFace Transformers,如果你還沒有安裝它,請運行:
pip install transformers我們還假設PyTorch,這是當今領先的深度學習庫之一,已經安裝。回想一下上面介紹的ObjectDetectionPipeline將在調用pipeline("object-detection")時在底層加載,它沒有TensorFlow的實例,因此PyTorch是必需的。這是我們將要運行創建的目標檢測流程的圖像,稍后在本文中將會用到。我們從導入開始:
from transformers import pipeline
from PIL import Image, ImageDraw, ImageFont顯然,我們使用了transformers,以及它的pipeline表示。然后,我們還使用了PIL,一個用于加載、可視化和操作圖像的Python庫。具體來說,我們使用第一個導入——Image用于加載圖像,ImageDraw用于繪制邊界框和標簽,后者還需要ImageFont。說到這兩者,接下來是加載字體(我們選擇Arial)并初始化上面介紹的目標檢測管道。
# Load font
font = ImageFont.truetype("arial.ttf", 40)
# Initialize the object detection pipeline
object_detector = pipeline("object-detection")然后,我們創建一個名為draw_bounding_box的函數,該函數將用于繪制邊界框。它接受圖像(im)、類別概率、邊界框的坐標、該定義將要用于的邊界框列表中的邊界框索引以及該列表的長度作為輸入。
在函數中,我們將依次執行下面步驟:
- 首先,在圖像上繪制實際的邊界框,表示為具有紅色的rounded_rectangle bbox,并且半徑較小,以確保邊緣平滑。
- 其次,在邊界框的上方略微繪制文本標簽。
- 最后,返回中間結果,這樣我們就可以在其上繼續繪制下一個邊界框和標簽。
# Draw bounding box definition
def draw_bounding_box(im, score, label, xmin, ymin, xmax, ymax, index, num_boxes):
""" Draw a bounding box. """
print(f"Drawing bounding box {index} of {num_boxes}...")
# Draw the actual bounding box
im_with_rectangle = ImageDraw.Draw(im)
im_with_rectangle.rounded_rectangle((xmin, ymin, xmax, ymax), outline = "red", width = 5, radius = 10)
# Draw the label
im_with_rectangle.text((xmin+35, ymin-25), label, fill="white", stroke_fill = "red", font = font)
# Return the intermediate result
return im剩下的是核心部分——使用管道,然后根據其結果繪制邊界框。以下是我們步驟:
- 首先,圖像——我們將其稱為street.jpg,并且它位于與Python腳本相同的目錄中——將被打開并存儲在im PIL對象中。我們只需將其提供給初始化的object_detector——這就足夠讓模型返回邊界框了!Transformers庫會處理其余部分。
- 然后,我們將數據分配給一些變量,并遍歷每個結果,繪制邊界框。
- 最后,我們將圖像保存到street_bboxes.jpg中。
# Open the image
with Image.open("street.jpg") as im:
# Perform object detection
bounding_boxes = object_detector(im)
# Iteration elements
num_boxes = len(bounding_boxes)
index = 0
# Draw bounding box for each result
for bounding_box in bounding_boxes:
# Get actual box
box = bounding_box["box"]
# Draw the bounding box
im = draw_bounding_box(im, bounding_box["score"], bounding_box["label"],\
box["xmin"], box["ymin"], box["xmax"], box["ymax"], index, num_boxes)
# Increase index by one
index += 1
# Save image
im.save("street_bboxes.jpg")
# Done
print("Done!")使用不同的模型/使用自己的模型進行目標檢測
如果你創建了自己的模型,或者想要使用不同的模型,那么很容易使用它來代替基于ResNet-50的DeTr Transformer。這將需要你添加以下導入:
from transformers import DetrFeatureExtractor, DetrForObjectDetection然后,你可以初始化特征提取器和模型,并使用它們初始化object_detector,而不是默認的一個。例如,如果你想將ResNet-101用作你的骨干,那么你可以這樣做:
# Initialize another model and feature extractor
feature_extractor = DetrFeatureExtractor.from_pretrained('facebook/detr-resnet-101')
model = DetrForObjectDetection.from_pretrained('facebook/detr-resnet-101')
# Initialize the object detection pipeline
object_detector = pipeline("object-detection", model = model, feature_extractor = feature_extractor)結果
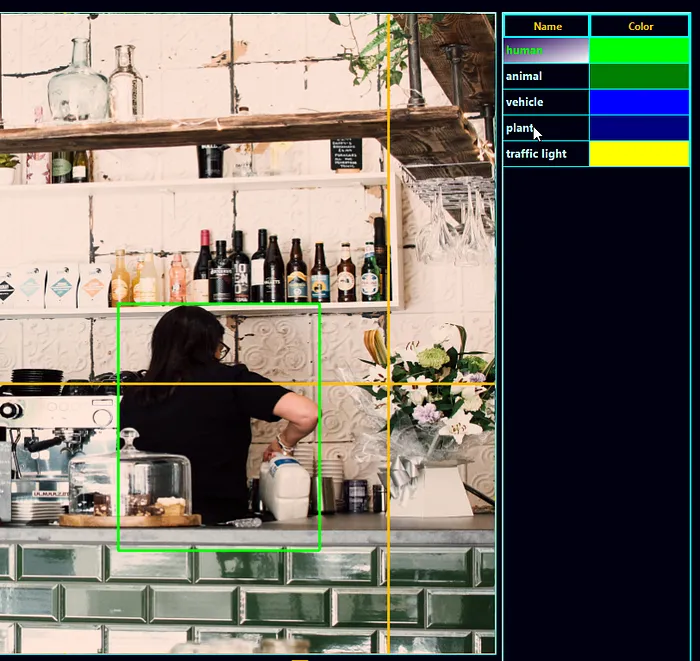
以下是我們在輸入圖像上運行目標檢測流程后得到的結果:

當放大時: