













目標(biāo)檢測中的 Anchor 詳解
直觀上,我們?nèi)绾晤A(yù)測圖像中的邊界框?第一個(gè)最明顯的技術(shù)是滑動(dòng)窗口。我們定義一個(gè)任意大小的窗口,并在圖像中“滑動(dòng)”它。在每一步中,我們分類窗口是否包含我們感興趣的對(duì)象。這就是我們所想的,對(duì)吧?那么,錨框?qū)⑹撬摹吧疃葘W(xué)習(xí)”版本。它更快,也更精確。
我們不只是滑動(dòng)一個(gè)窗口,而是同時(shí)滑動(dòng)一組不同大小和形狀的窗口。有些是小的用于小物體,有些是大的用于大物體,有些是高而瘦的用于人,有些是短而寬的用于公交車。

這些預(yù)定義的“窗口”就是錨框。它們就像你放在圖像上的一堆模板。我們不需要到處搜索;我們只需檢查每個(gè)模板(錨框)是否適合(或接近適合)一個(gè)物體。然后,我們的模型學(xué)會(huì)調(diào)整這些模板(錨框)以完美匹配它找到的物體。
一、定義
錨框是預(yù)定義的各種大小和寬高比的邊界框,作為目標(biāo)檢測的參考點(diǎn)。模型不是從頭開始預(yù)測框,而是調(diào)整這些錨框以更好地適應(yīng)實(shí)際物體,從而提高檢測的準(zhǔn)確性和效率。
1. 錨框與邊界框
首先,我們?nèi)∫粋€(gè)錨框,并系統(tǒng)地將其放置在整個(gè)圖像上,類似于滑動(dòng)窗口方法。

然而,注意到這些錨框中沒有一個(gè)完美匹配圖像中的實(shí)際物體。由于我們只使用一種形狀和大小的錨框,它無法捕捉到不同尺寸和寬高比的物體。因此,僅靠這種方法不足以進(jìn)行準(zhǔn)確的目標(biāo)檢測。
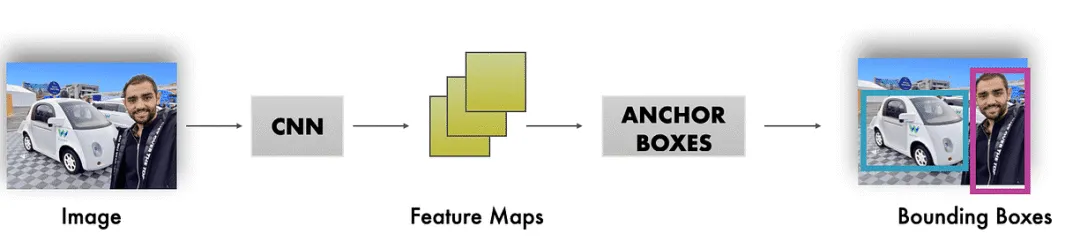
架構(gòu)看起來更像這樣;錨框應(yīng)用于特征圖,然后它們被細(xì)化為邊界框
2. 關(guān)于錨框
- 錨框應(yīng)用于特征圖,而不是直接應(yīng)用于圖像。
- 錨框幫助生成邊界框,但它們本身不是最終的邊界框。
二、什么是特征圖?
特征圖是由卷積神經(jīng)網(wǎng)絡(luò)(CNN)創(chuàng)建的圖像的處理版本。它們?cè)诓煌?xì)節(jié)層次上捕捉重要模式,如邊緣、紋理和物體形狀。錨框不是放置在原始圖像上,而是放置在特征圖上,使模型能夠更有效地進(jìn)行預(yù)測。
三、為什么錨框應(yīng)用于特征圖而不是圖像?
1. 計(jì)算效率
將錨框直接應(yīng)用于圖像意味著在每個(gè)可能的位置放置數(shù)千甚至數(shù)百萬個(gè)錨框,導(dǎo)致巨大的計(jì)算成本。
相反,特征圖比原始圖像小得多,因?yàn)榫矸e層在下采樣圖像的同時(shí)保留了重要信息。
示例:
- 假設(shè)我們有一個(gè)512×512的圖像。在每個(gè)像素上放置錨框意味著評(píng)估262,144個(gè)位置(512×512)。
- 如果特征圖下采樣到32×32,我們現(xiàn)在只需要評(píng)估1,024個(gè)位置,使計(jì)算速度提高256倍。
2. 更豐富的特征表示
特征圖包含由CNN提取的高級(jí)信息,如邊緣、紋理和物體部分,這有助于更準(zhǔn)確地檢測物體。
如果我們將錨框直接放置在原始圖像上,它們將僅依賴于像素強(qiáng)度,這缺乏目標(biāo)檢測所需的更深層次理解。
3. 尺度不變性(有效檢測小和大物體)
目標(biāo)檢測中的一個(gè)巨大挑戰(zhàn)是物體有不同的尺寸。有些物體可能小而遠(yuǎn),而有些物體可能大而近。如果我們將錨框直接放置在圖像上,它們將具有相同的尺度,使得檢測不同尺寸的物體變得困難。如果我們將錨框直接放置在圖像上,它們將具有固定的大小,并且不會(huì)調(diào)整以適應(yīng)不同物體的大小。
示例:
想象我們正在嘗試檢測圖像中的汽車:
- 遠(yuǎn)處的小汽車可能是30×30像素。
- 靠近攝像頭的大汽車可能是300×300像素。
如果我們只使用一個(gè)固定大小的錨框(例如100×100像素),它將無法正確匹配小汽車和大汽車:
- 100×100的框?qū)τ谛∑噥碚f太大,可能包括背景。
- 100×100的框?qū)τ诖笃噥碚f太小,無法覆蓋整個(gè)物體。
當(dāng)圖像通過CNN時(shí),它會(huì)在不同層次創(chuàng)建多個(gè)特征圖:
- 早期層捕捉小細(xì)節(jié)(例如邊緣、角落)。
- 深層捕捉更大的模式(例如物體的形狀)。
通過在特征圖上放置錨框,模型可以自動(dòng)調(diào)整以檢測:
- 使用精細(xì)特征圖(早期層)檢測小物體
- 使用抽象特征圖(深層)檢測大物體
(1) 早期層 — 檢測小物體
- CNN的早期層捕捉精細(xì)細(xì)節(jié),如邊緣、紋理和小模式。
- 這些層保留了更多的空間信息(即圖像的精細(xì)細(xì)節(jié))。
- 因此,它們擅長檢測小物體。
- 小錨框放置在這些層上以檢測圖像中的小物體。
示例:
想象我們正在檢測圖像中的汽車。遠(yuǎn)處的小汽車可能只有30×30像素。
- CNN的早期層仍然具有高分辨率,這意味著像這樣的小汽車仍然可以被檢測到。
- 在這一層使用一個(gè)小錨框(例如16×16像素)以匹配物體大小。
(2) 深層 — 檢測大物體
- 隨著圖像深入CNN,特征圖變得更小,但它們代表更復(fù)雜的特征(如物體的整體形狀而不是精細(xì)細(xì)節(jié))。
- 由于這些層看到更大的模式,它們更擅長檢測大物體。
- 較大的錨框放置在這些深層以檢測大物體。
示例:
前景中的大汽車可能是300×300像素。
- CNN的深層將有一個(gè)較小的特征圖,代表大尺度模式。
- 在這一層使用一個(gè)大錨框(例如128×128或256×256像素)以檢測較大的物體。
(3) 多尺度錨框 — 覆蓋所有尺寸
我們不在特征圖的不同層上只使用一種大小的錨框,而是應(yīng)用多種大小的錨框。這樣,我們可以在同一圖像中檢測小物體和大物體。
多尺度錨框示例:
在CNN的不同層,我們可能放置以下大小的錨框:
- 16×16像素用于小物體
- 32×32像素用于中等大小的物體
- 128×128像素用于大物體
(4) 兩階段檢測器中的更快區(qū)域提議
在像Faster R-CNN這樣的模型中,區(qū)域提議網(wǎng)絡(luò)(RPN)僅在特征圖上應(yīng)用錨框,生成較少但高質(zhì)量的對(duì)象提議。
這減少了在后續(xù)階段需要進(jìn)一步細(xì)化的區(qū)域數(shù)量,提高了速度和效率。
示例:
不是在原始圖像中評(píng)估100,000個(gè)可能區(qū)域,RPN可能會(huì)從特征圖生成2,000個(gè)高置信度的提議,從而加速檢測流程。
四、錨框是如何生成的?
雖然錨框應(yīng)用于特征圖,但我們?nèi)匀恍枰獩Q定它們的形狀、大小和寬高比。關(guān)鍵問題包括:
- 所有錨框都應(yīng)該是垂直矩形,還是應(yīng)該有一些是正方形?
- 最小和最大的錨框大小應(yīng)該是什么?
- 我們?nèi)绾未_保檢測到小而遠(yuǎn)的物體和大而近的物體?
為了捕捉不同尺度和形狀的物體,我們使用一組多樣化的錨框。這些框需要仔細(xì)選擇以與數(shù)據(jù)集中常見的物體對(duì)齊。
五、如何選擇錨框?
選擇錨框涉及手動(dòng)設(shè)計(jì)和數(shù)據(jù)驅(qū)動(dòng)優(yōu)化的結(jié)合:
手動(dòng)選擇:
- 基于數(shù)據(jù)集中物體的先驗(yàn)知識(shí),我們定義一些常見的錨框形狀和大小。
- 例如,如果檢測行人,我們可能會(huì)使用高而窄的框。如果檢測汽車,我們可能會(huì)使用更寬的框。
使用K-Means聚類:
- 我們不是手動(dòng)選擇所有錨框,而是可以使用K-Means等聚類算法分析數(shù)據(jù)集。
- 該算法將相似形狀和大小的物體分組,幫助我們找到最常見的邊界框尺寸。
- 通過選擇K個(gè)錨框模板,我們確保模型在不同物體大小上表現(xiàn)良好。
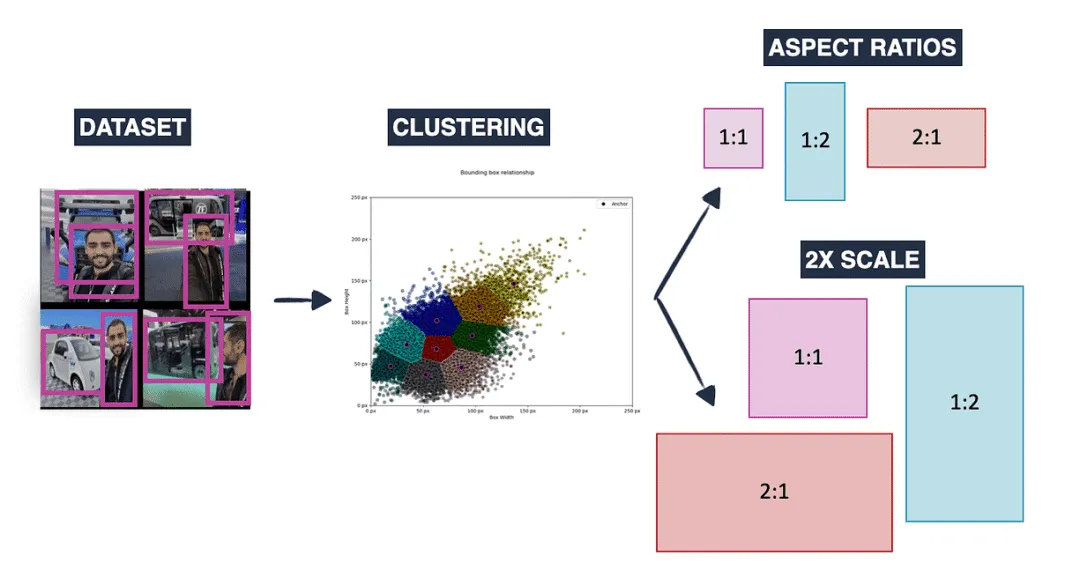
六、在目標(biāo)檢測中生成錨框
一旦確定了錨框的大小和寬高比,我們生成多個(gè)不同大小和變化的錨框。這些變化包括:
- 不同大小(例如(16,32), (32,32), (32,16))
- 不同寬高比(例如1:1, 1:2, 2:1)
- 不同尺度(例如1x, 2x, 3x),這些尺度放大或縮小框
這導(dǎo)致了一組大量的錨框,確保可以有效地檢測各種形狀和大小的物體。
七、在推理過程中如何生成錨框?
生成錨框的確切方法取決于所使用的目標(biāo)檢測算法。
示例:Faster R-CNN和區(qū)域提議網(wǎng)絡(luò)(RPN)的作用
在Faster R-CNN中,區(qū)域提議網(wǎng)絡(luò)(RPN)負(fù)責(zé)生成潛在的對(duì)象位置。
RPN如何與錨框一起工作:
(1) 特征提取
- 輸入圖像通過卷積神經(jīng)網(wǎng)絡(luò)(CNN)提取特征圖。
(2) 將錨框應(yīng)用于特征圖區(qū)域
- 在特征圖的每個(gè)位置上,放置多個(gè)不同大小和寬高比的錨框。
- 這些錨框作為檢測對(duì)象的起點(diǎn)。
(3) 錨框細(xì)化(回歸+分類)
- RPN預(yù)測調(diào)整(回歸)以細(xì)化錨框,使其與實(shí)際對(duì)象對(duì)齊。
- 它還分類每個(gè)錨框是否包含對(duì)象。
- 只有最有希望的框(稱為區(qū)域提議)被傳遞到下一步。
八、錨框變化示例
假設(shè)我們定義了一個(gè)16×16大小的錨框,并應(yīng)用:
- 兩種寬高比:1:1, 1:2, 和2:1
- 兩種尺度:1x和2x
這導(dǎo)致每個(gè)區(qū)域有6個(gè)錨框:
- 16×16 → 1:1比例的方形框,尺度1
- 16×32 → 1:2比例的高框,尺度1
- 32×16 → 2:1比例的寬框,尺度1
- 32×32 → 1:1比例的方形框,尺度2
- 32×64 → 1:2比例的高框,尺度2
- 64×32 → 2:1比例的寬框,尺度2
這確保我們覆蓋多種物體形狀(方形、寬、高)和多種物體大小(小到大)。
- 小物體(例如32×32)
- 中等物體(例如128×128)
- 大物體(例如512×512)
通過使用多樣化的錨框,模型可以準(zhǔn)確檢測小而遠(yuǎn)的物體和大而近的物體。
九、從錨框到邊界框
錨框不是最終的邊界框;它們只是預(yù)定義的參考形狀,用于幫助模型預(yù)測實(shí)際物體位置。為了將錨框轉(zhuǎn)換為最終的邊界框,模型根據(jù)圖像中的物體調(diào)整(或“回歸”)它們。讓我們通過一個(gè)示例逐步分解這個(gè)過程。
步驟1:在特征圖上生成錨框
- 圖像首先通過CNN傳遞,提取不同層的特征圖。
- 在每個(gè)特征圖上,每個(gè)空間位置放置多個(gè)不同大小和寬高比的錨框。
- 每個(gè)錨框作為物體可能位置的起點(diǎn)。
示例:
假設(shè)我們有一個(gè)10×10的特征圖,在每個(gè)位置上放置3個(gè)不同大小的錨框:
- 小框:32×32像素
- 中框:64×64像素
- 大框:128×128像素
由于我們有100個(gè)空間位置(10×10特征圖)和每個(gè)位置3個(gè)錨框,我們最終得到300個(gè)錨框。
步驟2:預(yù)測物體得分
評(píng)估每個(gè)錨框以確定是否包含物體。
- 分類頭為每個(gè)錨框分配一個(gè)概率得分。
- 如果得分高,意味著框可能包含物體。
- 如果得分低,則忽略。
示例:
- 模型預(yù)測在特征圖(5,5)位置的64×64錨框有80%的概率包含汽車。
- 該位置的其他錨框被忽略,因?yàn)樗鼈兊母怕瘦^低。
步驟3:調(diào)整錨框(邊界框回歸)
即使錨框接近物體,它也可能沒有完美對(duì)齊。因此,模型調(diào)整(或“回歸”)錨框坐標(biāo)以更好地適應(yīng)物體。
模型為每個(gè)錨框預(yù)測四個(gè)調(diào)整(偏移):
- Δx — 水平移動(dòng)中心的距離。
- Δy — 垂直移動(dòng)中心的距離。
- Δw — 調(diào)整寬度的距離。
- Δh — 調(diào)整高度的距離。
新的邊界框坐標(biāo)計(jì)算如下:
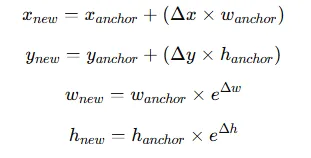
示例:
- 原始錨框在(5,5)位置,大小為64×64像素。
- 模型預(yù)測Δx = 0.1, Δy = -0.2, Δw = 0.05, Δh = -0.1。
- 應(yīng)用這些調(diào)整后,錨框稍微移動(dòng)并調(diào)整大小以更準(zhǔn)確地匹配汽車。
步驟4:去除冗余框(非最大抑制)
許多錨框可能會(huì)預(yù)測同一個(gè)物體,略有變化。
模型應(yīng)用非最大抑制(NMS)去除冗余框,只保留最好的一個(gè)。
選擇置信度最高的邊界框。
示例:
- 有5個(gè)重疊的邊界框圍繞汽車,具有不同的置信度得分(80%, 75%, 60%等)。
- 模型保留置信度最高的框,去除其他框。
最終結(jié)果
經(jīng)過所有這些步驟,我們得到一個(gè)最終邊界框,緊密地圍繞檢測到的物體。
示例總結(jié):
- 在特征圖上放置了一個(gè)64×64的錨框。
- 模型以80%的置信度檢測到一輛汽車。
- 模型調(diào)整了錨框以正確匹配汽車。
- 使用非最大抑制(NMS)去除了其他重疊框。
- 最終的邊界框準(zhǔn)確地圍繞圖像中的汽車。
【參考資料】
終于理解目標(biāo)檢測中的錨框(2D和3D):https://www.thinkautonomous.ai/blog/anchor-boxes/




























