分割仍舊發光!Mask2Map:爆拉MapTRv2 近10個點~
本文經自動駕駛之心公眾號授權轉載,轉載請聯系出處。
寫在前面 & 筆者理解
高精地圖(HD Map)一直以來被認為是是保證自動駕駛車輛安全有效導航的關鍵要素。它們通過提供地圖實例的詳細位置和語義信息,促進精確的規劃和障礙物避讓。傳統上,利用基于SLAM的方法離線構建的高精地圖,涉及復雜的過程,需要大量的勞動力和經濟成本。而且,這種方法在響應道路條件變化并提供及時更新方面存在局限性。所以,最近越來越多的論文開始研究如何基于學習來在線構造高精地圖構建,專注于生成自車周圍的局部地圖。
論文地址:https://arxiv.org/pdf/2407.13517
早期的工作將地圖構建視為一種語義分割任務,基于從各種傳感器獲得的BEV特征。它們預測了柵格格式中每個像素的類別標簽,避免了生成精確矢量輪廓的復雜性。雖然這種方法提供了語義地圖信息,但在捕捉不同類別的地圖組件的精確關鍵位置及其結構關系方面存在不足。因此,其輸出并不適合直接應用于下游任務,如運動預測和規劃。為了解決這個問題,越來越多的研究者將 HD map 矢量化,能夠直接生成矢量化的地圖實體。常見的方法如下圖1所示。

之前的工作主要分為三種思路:
- 圖1(a): 基于分割的解碼方法,該方法涉及語義分割,然后使用啟發式后處理算法生成矢量化地圖。然而,這種方法需要大量的處理時間。
- 圖1(b): 基于檢測的解碼方法識別對應于各種實例的關鍵點,然后按順序生成矢量化地圖組件。但是,僅依賴關鍵點可能無法充分捕捉實例的多樣化形狀,從而阻礙了生成準確的高精地圖。
- 圖1(c): 各種基于可學習查詢的解碼方法,這些方法通過并行從BEV特征中解碼可學習查詢,直接預測矢量化地圖組件。由于初始可學習查詢與給定場景無關,它們限制了同時捕獲復雜場景中地圖實例的語義和幾何信息的能力。
在這篇論文中,作者介紹了一種新的端到端高精地圖構建框架,稱為Mask2Map。如圖1(d)所示,Mask2Map通過利用分割掩碼來區分BEV領域中不同類別的實例。所提出的Mask2Map架構包括兩個網絡:實例級掩碼預測網絡(Instance Level Mask Prediction Network,IMPNet)和掩碼驅動地圖預測網絡(Mask-Driven Map Prediction Network,MMPNet)。最初,IMPNet從傳感器數據構建多尺度BEV特征,并生成掩碼感知查詢,從全局角度捕獲實例的語義特征。遵循實例分割模型Mask2Former的框架,作者設計了掩碼感知查詢,能夠生成與BEV范圍中不同類別的實例相關聯的BEV分割掩碼。隨后,基于IMPNet提供的掩碼感知查詢,MMPNet動態地從BEV范圍的局部角度預測地圖實例的有序點集。
相關工作
BEV分割方法
BEV分割任務指的是利用傳感器數據收集有關車輛周圍靜態環境信息的任務。該類分割方法通常從傳感器數據中提取BEV特征,并使用靜態場景的柵格化圖像作為GT,在BEV領域執行語義分割。例如,Lift-Splat-Shoot (LSS) 將從多視圖相機提取的特征轉換為3D特征,使用預測的深度信息,然后通過聚合這些特征生成BEV表示。CVT 使用交叉視圖注意力從透視圖到BEV領域學習幾何變換,使用相機感知的位置編碼。BEVFormer 通過與空間和時間信息交互,通過預定義的網格狀BEV查詢統一BEV表示。BEVSegFormer 通過使用可變形交叉注意力模塊,從不依賴于相機內參和外參的多視圖相機特征中生成密集的語義查詢,執行BEV語義分割。
矢量化高精地圖構建方法
在線高精地圖構建方法因其潛力而受到廣泛關注,有可能取代自動駕駛中的高精地圖,并為規劃和定位提供有用信息。這些方法使用傳感器數據實時預測自車周圍的詳細地圖實例。例如,HDMapNet 使用帶有BEV特征的語義分割模型和后處理方法來生成矢量化高精地圖。然而,這種方法需要大量的計算時間。為了提高處理效率,引入了基于查詢的方法,利用Transformer注意力解碼場景并直接預測地圖實例的有序點序列。VectorMapNet 引入了一個兩階段框架,首先檢測地圖實例的邊界框,然后使用自回歸解碼器依次預測每個實例的點。MapTR 利用DETR的架構將地圖實例表示為有序點集,并使用層次化查詢對Transformer解碼器進行編碼。MapTRv2 進一步擴展了其能力,使用深度監督學習3D幾何信息,并在透視視圖和BEV上進行語義分割。MapVR 為每個地圖實例生成矢量化地圖,然后使用可微分光柵化器將其轉換為光柵化地圖,提供實例級分割監督。PivotNet 通過生成關鍵點的有序列表預測地圖實例,這些關鍵點對于捕獲地圖組件的整體形狀至關重要。
去噪訓練策略
基于DETR架構的感知模型已經采用了基于Transformer架構的查詢預測,通過二分匹配將GT標簽分配給預測,以確保適當的監督。然而,這種分配有時會導致跨時期或層之間的匹配不一致。例如,不同的GT標簽可能在不同的時期分配給相同的查詢,從而導致收斂速度變慢和性能下降。為了解決這個挑戰,DN-DETR 引入了去噪訓練策略。該策略將從嘈雜的GT邊界框派生的查詢集成到DETR解碼器的現有查詢中,將預測這些GT邊界框的任務分配給這些GT查詢。這種方法已被證明在穩定跨訓練時期的二分匹配中是有效的。MP-Former 解決了連續解碼器層之間不一致的掩碼預測問題。MP-Former 采用了掩碼引導訓練方法,使用故意加入噪聲的GT查詢和GT掩碼,以減輕不準確掩碼預測的負面影響。Mask DINO 引入了一個統一的去噪訓練框架,增強了多任務學習在目標檢測和分割任務中的穩定性。
方法論
創新點
作者引入了幾種創新方法來提高預測高精地圖的準確性:
- 設計了位置查詢生成器(Positional Query Generator,PQG),它生成捕獲全面位置信息的實例級位置查詢,以增強掩碼感知查詢。
- 大多數現有方法在構建高精地圖時沒有考慮每個地圖實例的點級信息,但是作者引入了幾何特征提取器(Geometric Feature Extractor,GFE)來捕獲每個實例的幾何結構。GFE處理BEV分割掩碼,從BEV特征中提取地圖實例的點級幾何特征。
- 作者觀察到由于IMPNet和MMPNet的查詢與不同實例的GT相關聯,Mask2Map的性能受到限制。為了解決這個問題,作者提出了一種網絡間去噪訓練策略(Inter-network Denoising Training )。這種方法使用嘈雜的GT查詢和擾動的GT分割掩碼作為IMPNet的輸入,并引導模型對抗噪聲,從而確保網絡間的一致性并提高高精地圖構建的性能。
模型結構
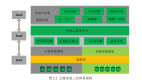
Mask2Map的整體架構如下圖2所示。Mask2Map架構包括兩個網絡:IMPNet和MMPNet。首先,IMPNet生成從全局視角捕獲全面語義信息的掩碼感知查詢。隨后,MMPNet利用通過PQG和GFE獲得的幾何信息,從局部視角構建更詳細的矢量化地圖。

實例級掩碼預測網絡(IMPNet)
IMPNet由BEV編碼器和掩碼感知查詢生成器組成。BEV編碼器從傳感器數據中提取多尺度BEV特征,掩碼感知查詢生成器產生掩碼感知查詢,隨后用于生成BEV分割掩碼。
BEV編碼器: IMPNet通過處理多視圖相機圖像、激光雷達點云或兩者的融合,生成BEV特征。多視圖相機圖像通過LSS操作轉換為BEV表示。激光雷達點云通過體素編碼轉換為BEV表示。當集成相機和激光雷達傳感器進行融合時,從兩種模態提取的BEV特征被連接并通過額外的卷積層。

掩碼驅動地圖預測網絡(MMPNet)
MMPNet包括三個主要組成部分:位置查詢生成器(Positional Query Generator)、幾何特征提取器(Geometric Feature Extractor)和掩碼引導地圖解碼器(Mask-Guided Map Decoder)。位置查詢生成器注入位置信息以增強掩碼感知查詢,而幾何特征提取器處理BEV分割掩碼以從BEV特征中提取幾何特征。最后,掩碼引導地圖解碼器使用位置查詢生成器和幾何特征提取器提供的特征,預測地圖實例的類別和有序點集的坐標。


網絡間去噪訓練
Mask2Map通過IMPNet傳遞掩碼感知查詢給MMPNet,以進行實例特征的層次化細化。為了確保有效的訓練,作者為IMPNet分配了實例分割損失,為MMPNet分配了地圖構建損失。IMPNet和MMPNet使用的查詢應該通過二分匹配與它們各自的GT進行匹配。然而,當IMPNet和MMPNet的查詢與不同實例的GT相關聯時,匹配過程中可能會出現不一致性。作者觀察到這種網絡間的不一致性往往會引發收斂速度變慢和性能下降。
為了解決這個問題,作者采用了去噪訓練策略。關鍵思想是將從每個GT實例派生的嘈雜GT查詢,合并到IMPNet內的可學習查詢中(見圖2)。作者的模型被訓練以去噪這些查詢,通過直接將它們與相應的GT匹配。這與通過二分匹配將可學習查詢與GT匹配的方式形成對比。因此,這種策略被稱為網絡間去噪訓練。這個過程引導模型在IMPNet和MMPNet使用的查詢之間建立對應關系,有效減輕了網絡間的不一致性。此外,除了GT查詢,作者還生成了擾動的GT分割掩碼,以替代IMPNet的BEV分割掩碼。

作者通過為每個實例的GT類別分配所有類別嵌入向量之一來生成GT查詢。作者通過以概率λ隨機替換類嵌入向量與其他類別之一來添加翻轉噪聲。同時,作者還通過將地圖噪聲添加到每個實例的有序點序列中,并將其光柵化,生成擾動的GT分割掩碼,如圖3(c)所示。
嘈雜GT查詢和可學習查詢的組合被稱為可學習實例查詢。與使用BEV分割掩碼不同,作者專門使用擾動的GT分割掩碼進行嘈雜GT查詢。嘈雜GT查詢通過IMPNet和MMPNet傳遞,其預測結果與相應的GT匹配,而不進行二分匹配。
訓練損失
用于訓練Mask2Map的總損失L由下式給出:

實驗
實驗設置
數據集。 作者在nuScenes 和 Argoverse2 兩個公開數據集上做了測試。
評估指標。 作者定義了感知范圍為橫向方向 [-15.0m, 15.0m] 和縱向方向 [-30.0m, 30.0m]。作者將地圖實例分為三類用于高精地圖構建:人行橫道、車道分隔線和道路邊界。作者采用兩種評估指標:基于 Chamfer 距離提出的平均精度 (AP) 和基于光柵化的 AP 。作者主要使用 Chamfer 距離度量,使用 0.5、1.0 和 1.5 米的閾值計算平均精度 (mAP)。對于基于光柵化的平均精度 (mAP?),作者測量每個地圖實例的交并比,閾值設置為 {0.50, 0.55, ..., 0.75} 用于人行橫道和 {0.25, 0.30, ..., 0.50} 用于線形元素。為了進一步評估網絡間匹配一致性比率,作者使用了查詢利用率 (Query Utilization, Util) 指標,該指標計算 MMPNet 的第一解碼器層與 IMPNet 的最后一層匹配的一致性比率。

性能比較
nuScenes 上的結果。 表1展示了 Mask2Map 在 nuScenes 驗證集上的全面性能分析,使用 Chamfer 距離度量。Mask2Map 建立了新的最先進性能,顯著優于現有方法。當僅使用相機輸入時,Mask2Map 在 24 個周期內取得了 71.6% mAP 的顯著結果,在 110 個周期內取得了 74.6% mAP,分別比之前的最先進模型 MapTRv2 高出 10.1% mAP 和 5.9% mAP。當使用相機-激光雷達融合時,Mask2Map 比 MapTRv2 提高了 9.4% mAP 的性能。表2基于光柵化度量評估了 Mask2Map 的性能。值得注意的是,作者的 Mask2Map 方法比 MapTRv2 提高了 18.0 mAP 的顯著性能。
Argoverse2 上的結果。 表3展示了幾種高精地圖構建方法在 Argoverse2 驗證集上的性能評估。所提出的 Mask2Map 與現有模型相比顯示出顯著的性能提升。Mask2Map 超過了當前領先的方法 MapTRv2,提高了 4.1% mAP,表明作者的模型在不同場景中實現了一致的性能。

消融研究
作者進行了消融研究,以評估 Mask2Map 核心思想的貢獻。在這些實驗中,使用了僅相機輸入和 ResNet50 骨干網絡。訓練在 nuScenes 訓練數據集的 1/4 上進行了 24 個周期。評估在完整驗證集上執行。
主要組件的貢獻: 表4展示了 Mask2Map 每個組件的影響。作者通過逐個添加每個組件來評估性能。第一行代表一個基線模型,使用基于 LSS 的 BEV 編碼器提取 BEV 特征,并使用可變形注意力預測矢量化地圖實例。將 IMPNet 添加到基線模型時,作者注意到 mAP 顯著增加了 5.9%,表明包含掩碼感知查詢(能夠生成實例分割結果)顯著提升了高精地圖構建的性能。此外,添加 MMPNet 使 mAP 進一步提高了 3.8%,強調了通過 BEV 分割掩碼注入地圖實例的位置和幾何信息的重要性。最后,作者的網絡間去噪訓練提供了額外的 6.5% mAP 增加,強調了其在提升性能中的有效性。
MMPNet 子模塊的貢獻: 作者在表5中詳細研究了 PQG 和 GFE 的貢獻。僅 GFE 就比基線貢獻了顯著的 3.1% mAP 增加,而僅 PQG 則產生了 3.4% mAP 的改進。PQG 和 GFE 的組合通過 4.8% mAP 進一步提高了性能,展示了它們的互補效應。
網絡間去噪訓練對匹配一致性的影響: 作者進一步研究了網絡間去噪訓練的影響。如表6所示,網絡間去噪訓練將匹配比率 Util 從 24.7% 顯著提高到 74.7%,這轉化為整體 mAP 性能的 6.5% 顯著增加。這表明作者的網絡間去噪訓練有效地減輕了 IMPNet 和 MMPNet 之間查詢到 GT 匹配的不一致性。
網絡間去噪訓練中噪聲的影響: 在表7中,作者探索了在網絡間去噪訓練中使用的地圖噪聲的影響。作者將方法與不使用地圖噪聲的 GT 分割掩碼的基線進行了比較。結果表明,在 GT 中添加地圖噪聲比基線提高了 0.8% mAP。

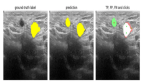
定性分析
定性結果。 圖4展示了所提出的 Mask2Map 產生的定性結果。作者與當前的最先進方法 MapTRv2 進行了比較。注意,Mask2Map 產生了比 MapTRv2 更好的地圖構建結果。

總結
作者介紹了一種名為Mask2Map的端到端在線高精地圖構建方法。Mask2Map利用IMPNet生成掩碼感知查詢和BEV分割掩碼,從全局視角捕獲語義場景上下文。隨后,MMPNet通過PQG和GFE增強掩碼感知查詢,整合語義和幾何信息。最后,掩碼引導地圖解碼器預測地圖實例的類別和有序點集。此外,作者提出了網絡間去噪訓練,以減輕IMPNet和MMPNet之間由于不同的二分匹配結果導致的網絡間不一致性。作者在nuScenes和Argoverse2基準測試上的評估表明,所提出的想法比基線帶來了顯著的性能提升,以相當大的優勢超越了現有的高精地圖構建方法。