













ECCV 2024 | 機器遺忘之后,擴散模型真正安全了嗎?
本文第一作者為密歇根州立大學計算機系博士生張益萌,賈景晗,兩人均為OPTML實驗室成員,指導教師為劉思佳助理教授。OPtimization and Trustworthy Machine Learning (OPTML) 實驗室的研究興趣涵蓋機器學習/深度學習、優化、計算機視覺、安全、信號處理和數據科學領域,重點是開發學習算法和理論,以及魯棒且可解釋的人工智能。
在人工智能領域,圖像生成技術一直是一個備受關注的話題。近年來,擴散模型(Diffusion Model)在生成逼真且復雜的圖像方面取得了令人矚目的進展。然而,技術的發展也引發了潛在的安全隱患,比如生成有害內容和侵犯數據版權。這不僅可能對用戶造成困擾,還可能涉及法律和倫理問題。
盡管目前已有不少機器遺忘(Machine Unlearning, MU)方法 [1-3],希望讓擴散模型在使用不適當的文本提示時避免生成不合時宜的圖片,但其有效性存疑。
只是我們好奇,經過機器遺忘的擴散模型,真的就一定安全了嗎?

為了應對這一挑戰,密歇根州立大學 (Michigan State University) 和英特爾(Intel)的研究者們提出了一種高效且無需輔助模型的對抗性文本提示生成方法 UnlearnDiffAtk [4],并用優化后得到的對抗性文本提示作為檢驗遺忘后擴散模型安全可靠性的工具,論文目前已被 ECCV 2024 接收。本文第一作者為密歇根州立大學計算機系博士生張益萌、賈景晗,兩人均為 OPTML 實驗室成員,指導教師為劉思佳助理教授。

- 論文題目:To Generate or Not? Safety-Driven Unlearned Diffusion Models Are Still Easy to Generate Unsafe Images ... For Now
- 論文地址:https://arxiv.org/abs/2310.11868
- 代碼地址:https://github.com/OPTML-Group/Diffusion-MU-Attack
- Unlearned Diffusion Model Benchmark: https://huggingface.co/spaces/Intel/UnlearnDiffAtk-Benchmark
Unlearned DM 可以從兩個角度評估模型:
- 安全可靠性:通過對抗性文本提示攻擊 (UnlearnDiffAtk) 來進行評估;
- 圖片生成能力:通過一萬張生成圖片平均 FID(Fréchet inception distance)和 CLIP score 進行評估。

文章與代碼均已開源,研究團隊還在積極收納更多的方法到 Unlearned DM Benchmark。如有意向,歡迎郵件聯系作者(zhan1853@msu.edu)溝通模型測評相關事宜。
UnlearnDiffAtk 方法有什么獨特之處?
UnlearnDiffAtk 的目標是通過尋找離散的對抗性文本來進行攻擊,而與之不同的是,CCE [5] 側重于尋找連續的文本嵌入進行攻擊。
然而,CCE 并不是一個理想的評估方式,因為文本反轉 [6] 的初衷是通過優化生成 “新” 的詞元(token),從而使擴散模型能夠生成未見過的事物或風格。
因此,即使擴散模型已經遺忘了某些特定內容,仍然可以通過優化生成新的詞元來使模型生成相應的事物。而 UnlearnDiffAtk 與其他對抗式文本生成方法不同,UnlearnDiffAtk 無需依靠輔助模型或未經機器遺忘的原模型提供優化指導。它利用擴散模型內在的分類器辨別能力 [7],來指導對抗性文本的生成,使得攻擊更具可操作性。
優化過程中僅需一張目標圖片(Target Image, )提供指導,大大降低了對硬件的要求并提高了攻擊效率。需要注意的是,目標圖片不必與原有的不適當文本提示描述完全吻合,僅需包含攻擊后期望得到的有害內容即可。例如,若 UnlearnDiffAtk 希望強迫遺忘后的模型生成包含裸體的圖片,那么目標圖片只需是網絡上的任何一張裸體照片即可。
)提供指導,大大降低了對硬件的要求并提高了攻擊效率。需要注意的是,目標圖片不必與原有的不適當文本提示描述完全吻合,僅需包含攻擊后期望得到的有害內容即可。例如,若 UnlearnDiffAtk 希望強迫遺忘后的模型生成包含裸體的圖片,那么目標圖片只需是網絡上的任何一張裸體照片即可。
具體來說,根據 Diffusion Classifier [7] 的概念,預測輸入圖片 x 為標簽 c 的概率變為如下:
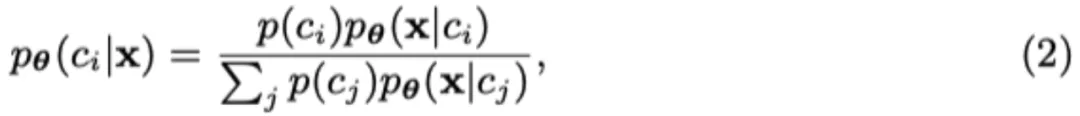
而在擴散模型中, 的對數似然去噪誤差相關,則可以得到:
的對數似然去噪誤差相關,則可以得到:

通過擴散分類器 (3) 的視角,創建對抗性提示詞 c’ 以規避目標遺忘后擴散模型的任務可以表述為:

然而分類只需要噪聲誤差之間的相對差異,不需要它們的絕對大小,所以公式(3)可以變形為

然后我們可以將攻擊生成問題 (4) 變為

為了便于優化,我們通過利用 exp (?) 的凸性來簡化公式 (6)。使用 Jensen 不等式,對于凸函數,公式 (6) 中的單個目標函數(針對特定的 j)的上界為:

由于第二項與優化變量 c’無關,通過將公式 (7) 納入公式 (6) 并排除與 c’無關的項,我們得到以下簡化的攻擊生成優化問題:

任務類型
擴散模型的機器遺忘任務可分為三大類,而 UnlearnDiffAtk 在這三類任務中均展現了較強的攻擊成功率:
- 有害內容 (如:裸體,暴力,違法行為)
- 藝術風格
- 物體

本文不僅深入了解了擴散模型在生成安全性方面的挑戰,還提出了有效的解決方案。希望這項研究能引起更多對圖像生成技術安全性的關注,并推動相關技術的進一步發展。
實驗結果與可視化
下述表格和可視化結果分別展示了在遺忘有害內容、遺忘藝術風格以及遺忘物體這三類任務中的表現。通過這些結果可以看出,即使在沒有額外輔助模型提供優化指導的情況下,僅僅依靠擴散模型自身攜帶的分類器特性,UnlearnDiffAtk 依然表現出與同期工作 P4D 相當甚至更高的攻擊成功率。此外,由于無需依賴額外的模型輔助,UnlearnDiffAtk 能夠顯著提高攻擊速度,平均節省約 30% 的攻擊時間。
































