深入理解 RAG 中的嵌入模型 Embedding Model
在當前流行的RAG引擎(例如RAGFlow、Qanything、Dify、FastGPT等)中,嵌入模型(Embedding Model)是必不可少的關鍵組件。在RAG引擎中究竟扮演著怎樣的角色呢?本文筆者進行了總結,與大家分享~

什么是Embedding?
在學習嵌入模型之前,我們需要先了解什么是Embedding。簡單來說,Embedding是一種將離散的非結構化數據(如文本中的單詞、句子或文檔)轉換為連續向量的技術。
在自然語言處理(NLP)領域,Embedding通常用于將文本映射為固定長度的實數向量,以便計算機能夠更好地處理和理解這些數據。每個單詞或句子都可以用一個包含其語義信息的向量來表示。
Embedding常用于將文本數據映射為固定長度的實數向量,從而使計算機能夠更好地處理和理解這些數據。每個單詞或句子都可以用一個包含其語義信息的實數向量來表示。

以“人騎自動車”為例,在計算機中,單詞是以文字形式存在的,但計算機無法直接理解這些內容。Embedding的作用就是將每個單詞轉化為向量,例如:
- “人”可以表示為 [0.2, 0.3, 0.4]
- “騎”可以表示為 [0.5, 0.6, 0.7]
- “自行車”可以表示為 [0.8, 0.9, 1.0]
通過這些向量,計算機可以執行各種計算,比如分析“人”和“自行車”之間的關系,或者判斷“騎”這個動作與兩者之間的關聯性。
此外,Embedding還可以幫助計算機更好地處理和理解自然語言中的復雜關系。例如:
- 相似的詞(如“人”和“騎手”)在向量空間中會比較接近。
- 不相似的詞(如“人”和“汽車”)則會比較遠。
那么為什么需要向量呢?
因為計算機只能處理數字,無法直接理解文字。通過將文本轉換為向量,相當于為數據分配了一個數學空間中的“地址”,使計算機能夠更高效地理解和分析數據。
什么是Embedding Model?
在自然語言處理(NLP)中,嵌入模型(Embedding Model) 是一種將詞語、句子或文檔轉換成數字向量的技術。它通過將高維、離散的輸入數據(如文本、圖像、聲音等)映射到低維、連續的向量空間中,使得計算機能夠更好地理解和處理這些數據。

Embedding Model就像是給每個詞或句子分配一個獨特的“指紋”,這個“指紋”能夠在數學空間中表示這個詞或句子的含義。具體來說,這種模型將每個詞語或句子轉換成一個固定長度的數字向量。通過這種方式,計算機可以對文本進行各種數學計算,例如:
- 比較詞語的相似性:通過計算兩個詞語向量之間的距離(如余弦相似度),可以判斷它們在語義上的相似程度。
- 分析句子的意義:通過對句子中的所有詞語向量進行聚合(如平均值或加權和),可以得到整個句子的向量表示,并進一步分析其語義信息。
這種技術在許多NLP任務中具有重要意義,以下是幾個典型的應用示例:
- 語義搜索:通過計算查詢向量與文檔庫中各文檔向量的相似度,找到與查詢最相關的文檔或段落。例如,用戶輸入“如何制作披薩?”,系統會返回最相關的烹飪指南。
- 情感分析:判斷一段文本的情感傾向(如正面、負面或中性)。例如,對于一篇產品評論“這款手機性能出色,但電池續航一般”,系統可以分析出該評論整體上是正面的,但也存在一些負面因素。
- 機器翻譯:將一種語言的文本轉換為另一種語言。例如,用戶輸入“我喜歡貓”,系統將其轉換為對應的英文翻譯“I like cats”。
- 問答系統:根據用戶的問題,從知識庫中檢索相關信息并生成回答。例如,用戶提問“太陽有多大?”,系統通過嵌入模型找到相關天文學文檔,并生成詳細的回答。
- 文本分類:將文本歸類到預定義的類別中。例如,新聞文章可以被自動分類為政治、體育、科技等不同類別,基于其內容的向量表示。
- 命名實體識別(NER):識別文本中的特定實體(如人名、地名、組織名等)。例如,在一段文字“李華在北京大學學習”中,系統可以識別出“李華”是人名,“北京大學”是組織名。
Embedding Model的作用
在RAG引擎中,嵌入模型(Embedding Model) 扮演著至關重要的角色。它用于將文本轉換為向量表示,以便進行高效的信息檢索和文本生成。以下是Embedding Model在RAG引擎中的具體作用和示例:
(1) 文本向量化
- 作用:將用戶的問題和大規模文檔庫中的文本轉換為向量表示。
- 舉例:在RAG引擎中,用戶輸入一個問題,如“如何制作意大利面?”,Embedding Model會將這個問題轉換為一個高維向量。
(2) 信息檢索
- 作用:使用用戶的查詢向量在文檔庫的向量表示中檢索最相似的文檔。
- 舉例:RAG引擎會計算用戶問題向量與文檔庫中每個文檔向量的相似度,然后返回最相關的文檔,這些文檔可能包含制作意大利面的步驟。
(3) 上下文融合
- 作用:將檢索到的文檔與用戶的問題結合,形成一個新的上下文,用于生成回答。
- 舉例:檢索到的關于意大利面的文檔會被Embedding Model轉換為向量,并與問題向量一起作為上下文輸入到生成模型中。
(4) 生成回答
- 作用:利用融合了檢索文檔的上下文,生成模型生成一個連貫、準確的回答。
- 舉例:RAG引擎結合用戶的問題和檢索到的文檔,生成一個詳細的意大利面制作指南作為回答。
(5) 優化檢索質量
- 作用:通過微調Embedding Model,提高檢索的相關性和準確性。
- 舉例:如果RAG引擎在特定領域(如醫學或法律)中使用,可以通過領域特定的數據對Embedding模型進行微調,以提高檢索的質量。
(6) 多語言支持
- 作用:在多語言環境中,Embedding Model可以處理和理解不同語言的文本。
- 舉例:如果用戶用中文提問,而文檔庫包含英語內容,Embedding Model需要能夠處理兩種語言的文本,并將它們轉換為統一的向量空間,以便進行有效的檢索。
(7) 處理長文本
- 作用:將長文本分割成多個片段,并為每個片段生成Embedding,以便在RAG引擎中進行檢索。
- 舉例:對于長篇文章或報告,Embedding Model可以將其分割成多個部分,每個部分都生成一個向量,這樣可以在不損失太多語義信息的情況下提高檢索效率。
通過以上幾點,Embedding Model在RAG引擎中提供了一個橋梁,連接了用戶查詢和大量文本數據,使得信息檢索和文本生成成為可能。如下圖所示,Embedding Model正處于整個RAG系統的中心位置。

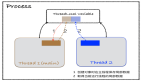
RAG引擎中的工作流
以下是一個RAG引擎中工作流的示意圖,此流程基本與各大RAG引擎相匹配。雖然各個不同的RAG引擎內部算法可能有所區別,但整體工作流程大同小異。

流程說明:
- 查詢嵌入化:將用戶輸入的查詢傳遞給嵌入模型,并在語義上將查詢內容表示為嵌入的查詢向量。
- 向量數據庫查詢:將嵌入式查詢向量傳遞給向量數據庫。
- 檢索相關上下文:檢索前k個相關上下文——通過計算查詢嵌入和知識庫中所有嵌入塊之間的距離(如余弦相似度)來衡量檢索結果。
- 上下文融合:將查詢文本和檢索到的上下文文本傳遞給對話大模型(LLM)。
- 生成回答:LLM 將使用提供的內容生成回答內容。