













通用場景拉滿了!GenXD:生成任何3D&4D場景(新加坡國立&微軟最新)
寫在前面&筆者的個人理解
近年來,利用擴散和自回歸建模生成2D視覺內容已經取得了顯著成功,并已在實際應用中進行廣泛使用。除了 2D 生成之外,3D 內容生成也至關重要,可應用于視頻游戲、視覺效果和可穿戴混合現實設備。然而,由于 3D 建模的復雜性和 3D 數據的局限性,3D 內容生成仍然遠遠不能令人滿意,并且正在引起學術界和工業界越來越多的關注。
之前大多數的研究工作主要聚焦于使用合成的目標數據實現3D和4D內容的生成。合成的目標數據通常是網格,從而允許研究人員從任何的視角來渲染圖像和其他的3D信息。然而,目標生成對領域專家的益處遠遠大于大眾。相比之下,場景級的生成可以幫助每個人用更加豐富的內容來增強他們的圖像以及視頻。因此,最近的研究探索了單一模型中的一般 3D 生成,并取得了令人印象深刻的生成性能。盡管如此,這些研究工作僅關注靜態 3D 生成,而沒有解決動態的問題。
考慮到 4D 生成面臨的首要挑戰是缺乏通用 4D 數據。在這項工作中,我們提出了 CamVid-30K數據集,其中包含大約 30K 個 4D 數據樣本。4D 數據需要多視圖空間信息和時間動態,因此我們轉向視頻數據來獲取必要的 4D 數據。
此外,我們也提出了一個統一的框架 GenXD,用于在單個模型中處理 3D 和 4D 生成,能夠從不同視角和時戳生成任意數量的條件圖像,其生成的部分內容如下圖所示。

此外,我們對各種現實世界和合成數據集進行了廣泛的實驗和評估,證明了與之前的 3D 和 4D 生成方法相比,我們提出的GenXD算法模型具有更好的有效性和多功能性。
論文鏈接:https://arxiv.org/pdf/2411.02319
GenXD網絡結構&技術細節梳理
生成模型
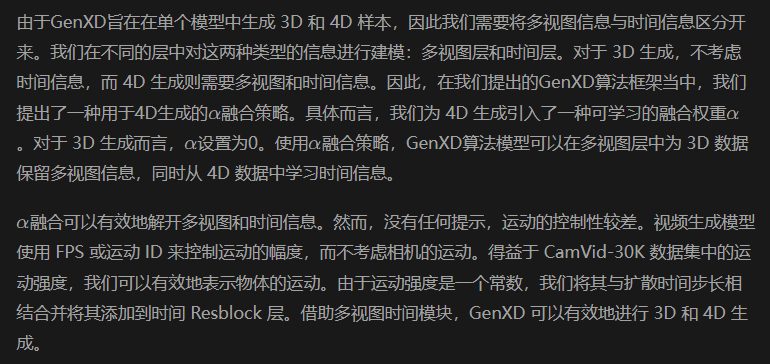
由于大多數的場景級3D和4D數據通過視頻獲得,因此這些數據缺少明確的表示。所以,我們采用一種生成與空間相機姿勢和時間戳步長對齊的圖像的方法。具體而言,我們將擴散模型納入到我們的框架當中,引入額外的多視圖時域層,包括多視圖時序ResBlocks和多視圖時序Transformer,以解耦和融合3D和時序信息,下面是我們提出的GenXD的整體網絡結構圖。

Mask Latent Conditioned Diffusion Model


GenXD 生成具有相機姿勢和參考圖像的多視圖圖像和視頻,因此它需要相機和圖像條件。相機條件對于每幅圖像都是獨立的,無論是 條件性的還是有針對性的。因此,很容易將其附加到每個潛在圖像中。在這里,我們選擇Plucker射線作為相機條件

Plucker 射線是一種密集嵌入編碼,不僅編碼了像素信息,還編碼了相機位姿和內在信息,相比于全局相機而言更具有優勢。參考圖像條件更為復雜。GenXD 旨在通過單視圖和多視圖輸入進行 3D 和 4D 生成。單視圖生成要求較低,而多視圖生成結果更一致。因此,將單視圖和多視圖生成結合起來將帶來更好的實際應用。
然而,之前的相關研究工作通過將潛在條件連接到目標潛在條件,并通過交叉注意力合并CLIP模型的圖像嵌入來生成圖像。連接方式的改變需要更改模型的通道,無法處理任意輸入視圖。CLIP嵌入可以支持多種條件。然而,這兩種方式都無法對多種條件的位置信息進行建模,也無法對輸入視圖之間的信息進行建模。鑒于這種局限性,我們利用掩碼作為潛在條件來處理圖像條件。如上圖所示,我們使用VAE編碼器之后,對目標幀應用前向擴散過程,使用條件保持原樣。然后通過去噪模型估計兩幀上的噪聲,并通過后向過程進行去除。
掩碼潛在條件有三個主要優點。首先,模型可以支持任何輸入視圖而無需修改參數。其次,對于序列生成(多視圖圖像或視頻),我們不需要限制條件幀的位置,因為條件幀在序列中保持其位置。相反,許多工作要求條件圖像在序列中的固定位置(通常是第一幀)。第三,如果沒有來自其他模型的條件嵌入,可以刪除用于集成條件嵌入的交叉注意層,這將大大減少模型參數的數量。為此,我們在GenXD算法模型中利用掩碼潛在條件方法。
MultiView-Temporal Modules
3D表達生成
GenXD 可以使用一個或多個條件圖像生成具有不同視點和時間步長的圖像。但是,為了呈現任意的 3D 一致視圖,我們需要將生成的樣本提升為 3D 表示。以前的工作通常通過從生成模型中提取知識來優化 3D 表示。由于 GenXD 可以生成高質量且一致的結果,我們直接使用生成的圖像來優化 3D 表示。具體來說,我們利用 3D Gaussian Splatting 和 Zip-NeRF 進行 3D 生成,利用 4D Gaussian Splatting (4D-GS) 進行 4D 生成。
CAMVID-30K數據集介紹
由于缺乏大規模 4D 場景數據限制了動態 3D 任務的發展,包括但不限于 4D 生成、動態相機姿勢估計和可控視頻生成。為了解決這個問題,我們在本文中引入了一個高質量的 4D 數據集。首先,我們使用基于結構運動 (SfM) 的方法估計相機姿勢,然后使用所提出的運動強度過濾掉沒有物體運動的數據,整個流程如下圖所示。

相機位姿估計
相機姿態估計基于SfM,它從一系列圖像中的投影重建 3D 結構。SfM 涉及三個主要步驟:(1) 特征檢測和提取,(2) 特征匹配和幾何驗證,(3) 3D 重建和相機姿態估計。在第二步中,匹配的特征必須位于場景的靜態部分。否則,在特征匹配期間,物體移動將被解釋為相機移動,這會損害相機姿態估計的準確性。為了獲得準確的相機姿勢,必須分割所有移動像素。在這種情況下,假陽性錯誤比假陰性更容易接受。為了實現這一點,我們使用實例分割模型來貪婪地分割所有可能移動的像素。在分割出可能移動的像素后,我們使用 Particle-SfM估計相機姿態,以獲得相機信息和稀疏點云。
目標運動估計
雖然實例分割可以準確地將物體與背景分開,但它無法確定物體本身是否在移動,而靜態物體會對運動學習產生負面影響。因此,我們引入了運動強度來識別真正的物體運動,并過濾掉只有靜態物體的視頻。
由于攝像機運動和物體運動都存在于視頻中,因此基于 2D 的運動估計方法無法準確表示真實的物體運動。有兩種方法可以捕捉真實的物體運動:通過測量 3D 空間中的運動或通過將視頻中的運動投影到同一臺攝像機。這兩種方法都需要與攝像機姿勢比例對齊的深度圖。稀疏深度圖可以通過投影 3D 點云到相機視角來獲得

由于在 3D 重建過程中僅匹配靜態部分的特征,因此我們只能獲得靜態區域的稀疏點云。然而,動態部分的深度信息對于估計運動至關重要。為了解決這個問題,我們利用預先訓練的相對單目深度估計模型來預測每幀的相對深度,然后我們應用比例因子和移位來使其與 SfM 稀疏深度對齊

有了對齊的深度,我們可以將幀中的動態目標投影到 3D 空間中,從而提供一種直接測量目標運動的方法。如上圖 (b) 所示,如果目標(例如,穿綠色襯衫的人)正在移動,則投影的 3D 點云中將發生位移。但是,由于 SfM 的運行范圍很廣,因此直接在 3D 空間中測量運動可能會導致幅度問題。因此,我們將動態目標投影到相鄰視圖中并估計目標運動場。
具體來說,我們首先需要在 2D 視頻中找到匹配點。我們不使用光流等密集表示,而是為每個目標實例采樣關鍵點,并在 2D 視頻中使用視頻目標分割和關鍵點跟蹤來建立匹配關系。然后將每個關鍵點投影到相鄰幀中。首先將第幀中的關鍵點反向投影到世界空間,以獲得 3D 關鍵點。

有了每個物體的運動場,我們可以通過平均運動場的絕對幅度來估計物體的全局運動。對于每個視頻,運動強度由所有物體中的最大運動值表示。如下圖所示,當相機移動而物體保持靜止時(第二個示例),與有物體運動的視頻相比,運動強度明顯較小。使用運動強度,我們進一步過濾掉缺乏明顯物體運動的數據。

實驗結果&評價指標
4D生成實驗結果
我們將 GenXD 與開源相機條件視頻生成方法進行了比較,我們使用Stable Video Diffusion作為baseline模型,并利用攝像機軌跡和第一幀條件生成視頻,相關的實驗結果如下表所示。

以第一視圖為條件,GenXD 在兩個指標上均明顯優于 CameraCtrl 和 MotionCtrl。此外,以 3 個視圖(第一幀、中間幀和最后一幀)為條件,GenXD 的表現遠遠優于之前的作品。這些結果證明了 GenXD 在 4D 生成上的強大泛化能力。
此外,為了直觀的展現出GenXD算法模型的性能,我們將相關的生成結果展示在下圖中。我們比較了三種方法的定性結果。在這個例子中,MotionCtrl 無法生成明顯的物體運動,而 CameraCtrl 生成的視頻既不是 3D 的也不是時間一致的。相反,我們的單視圖條件模型可以生成流暢且一致的 4D 視頻。通過 3 個條件視圖,GenXD 可以生成非常逼真的結果。

3D生成實驗結果
對于少視圖 3D 重建設置,我們在分布內和分布外數據集上評估 GenXD。我們從 Re10K 中選擇了 10 個場景,在 LLFF 中選擇了所有 8 個場景,每個場景中的 3 個視圖用于訓練。使用渲染測試視圖上的 PSNR、SSIM 和 LPIPS 指標評估性能。作為生成模型,GenXD 可以從稀疏輸入視圖中生成附加視圖,并提高任何重建方法的性能。在這個實驗中,我們利用了兩種基線方法:Zip-NeRF 和 3D-GS。這兩個基線是多視圖重建的方法,因此我們調整超參數以實現更好的少視圖重建。如下表所示,Zip-NeRF 和 3D-GS 都可以使用 GenXD 生成的圖像進行改進,并且 Zip-NeRF 基線的改進更為顯著。具體來說,Re10K(分布內)和 LLFF(分布外)上的 PSNR 分別提高了 4.82 和 5.13。

更加直觀的展示結果如下圖所示,使用生成的視圖,重建場景中的浮動物和模糊減少了。

結論
在本文中,我們提出了GenXD算法模型來處理一般的 3D 和 4D 內容生成。GenXD 可以利用多視圖時間模塊來解開相機和物體的移動,并且能夠通過掩碼潛在條件來支持任意數量的輸入條件視圖。提出的GenXD算法模型可以處理多種應用,并且可以通過一個模型在所有設置中實現相當或更好的性能。

























