













WHALE來了,南大周志華團(tuán)隊(duì)做出更強(qiáng)泛化的世界模型
人類能夠在腦海中設(shè)想一個(gè)想象中的世界,以預(yù)測(cè)不同的動(dòng)作可能導(dǎo)致不同的結(jié)果。受人類智能這一方面的啟發(fā),世界模型被設(shè)計(jì)用于抽象化現(xiàn)實(shí)世界的動(dòng)態(tài),并提供這種「如果…… 會(huì)怎樣」的預(yù)測(cè)。
因此,具身智能體可以與世界模型進(jìn)行交互,而不是直接與現(xiàn)實(shí)世界環(huán)境交互,以生成模擬數(shù)據(jù),這些數(shù)據(jù)可以用于各種下游任務(wù),包括反事實(shí)預(yù)測(cè)、離線策略評(píng)估、離線強(qiáng)化學(xué)習(xí)。
世界模型在具身環(huán)境的決策中起著至關(guān)重要的作用,使得在現(xiàn)實(shí)世界中成本高昂的探索成為可能。為了促進(jìn)有效的決策,世界模型必須具備強(qiáng)大的泛化能力,以支持分布外 (OOD) 區(qū)域的想象,并提供可靠的不確定性估計(jì)來評(píng)估模擬體驗(yàn)的可信度,這兩者都對(duì)之前的可擴(kuò)展方法提出了重大挑戰(zhàn)。
本文,來自南京大學(xué)、南棲仙策等機(jī)構(gòu)的研究者引入了 WHALE(World models with beHavior-conditioning and retrAcing-rollout LEarning),這是一個(gè)用于學(xué)習(xí)可泛化世界模型的框架,由兩種可以與任何神經(jīng)網(wǎng)絡(luò)架構(gòu)普遍結(jié)合的關(guān)鍵技術(shù)組成。

- 論文地址:https://arxiv.org/pdf/2411.05619
- 論文標(biāo)題:WHALE: TOWARDS GENERALIZABLE AND SCALABLE WORLD MODELS FOR EMBODIED DECISION-MAKING
首先,在確定策略分布差異是泛化誤差的主要來源的基礎(chǔ)上,作者引入了一種行為 - 條件(behavior-conditioning)技術(shù)來增強(qiáng)世界模型的泛化能力,該技術(shù)建立在策略條件模型學(xué)習(xí)的概念之上,旨在使模型能夠主動(dòng)適應(yīng)不同的行為,以減輕分布偏移引起的外推誤差。
此外,作者還提出了一種簡單而有效的技術(shù),稱為 retracing-rollout,以便對(duì)模型想象進(jìn)行有效的不確定性估計(jì)。作為一種即插即用的解決方案, retracing-rollout 可以有效地應(yīng)用于各種實(shí)施任務(wù)中的末端執(zhí)行器姿態(tài)控制,而無需對(duì)訓(xùn)練過程進(jìn)行任何更改。
為了實(shí)現(xiàn) WHALE 框架,作者提出了 Whale-ST,這是一個(gè)基于時(shí)空 transformer 的可擴(kuò)展具身世界模型,旨在為現(xiàn)實(shí)世界的視覺控制任務(wù)提供忠實(shí)的長遠(yuǎn)想象。
為了證實(shí) Whale-ST 的有效性,作者在模擬的 Meta-World 基準(zhǔn)和物理機(jī)器人平臺(tái)上進(jìn)行了廣泛的實(shí)驗(yàn)。
在模擬任務(wù)上的實(shí)驗(yàn)結(jié)果表明,Whale-ST 在價(jià)值估計(jì)準(zhǔn)確率和視頻生成保真度方面均優(yōu)于現(xiàn)有的世界模型學(xué)習(xí)方法。此外,作者還證明了基于 retracing-rollout 技術(shù)的 Whale-ST 可以有效捕獲模型預(yù)測(cè)誤差并使用想象的經(jīng)驗(yàn)增強(qiáng)離線策略優(yōu)化。
作為進(jìn)一步的舉措,作者引入了 Whale-X,這是一個(gè)具有 414M 參數(shù)的世界模型,該模型在 Open X-Embodiment 數(shù)據(jù)集中的 970k 個(gè)現(xiàn)實(shí)世界演示上進(jìn)行了訓(xùn)練。通過在完全沒見過的環(huán)境和機(jī)器人中的一些演示進(jìn)行微調(diào),Whale-X 在視覺、動(dòng)作和任務(wù)視角中展示了強(qiáng)大的 OOD 通用性。此外,通過擴(kuò)大預(yù)訓(xùn)練數(shù)據(jù)集或模型參數(shù),Whale-X 在預(yù)訓(xùn)練和微調(diào)階段都表現(xiàn)出了令人印象深刻的可擴(kuò)展性。
總結(jié)來說,這項(xiàng)工作的主要貢獻(xiàn)概述如下:
- 作者引入了 WHALE,這是一個(gè)學(xué)習(xí)可泛化世界模型的框架,由兩項(xiàng)關(guān)鍵技術(shù)組成:行為 - 條件(behavior-conditioning)和 retracing-rollout,以解決世界模型在決策應(yīng)用中的兩個(gè)主要挑戰(zhàn):泛化和不確定性估計(jì);
- 通過整合 WHALE 的這兩種技術(shù),作者提出了 Whale-ST,這是一種可擴(kuò)展的基于時(shí)空 transformer 的世界模型,旨在實(shí)現(xiàn)更有效的決策,作者進(jìn)一步提出了 Whale-X,這是一個(gè)在 970K 機(jī)器人演示上預(yù)訓(xùn)練的 414M 參數(shù)世界模型;
- 最后,作者進(jìn)行了大量的實(shí)驗(yàn),以證明 Whale-ST 和 Whale-X 在模擬和現(xiàn)實(shí)世界任務(wù)中的卓越可擴(kuò)展性和泛化性,突出了它們?cè)谠鰪?qiáng)決策方面的效果。
學(xué)習(xí)可泛化的世界模型以進(jìn)行具身決策
世界模型中的序列決策通常需要智能體探索超出訓(xùn)練數(shù)據(jù)集的分布外 (OOD) 區(qū)域。這要求世界模型表現(xiàn)出強(qiáng)大的泛化能力,使其能夠做出與現(xiàn)實(shí)世界動(dòng)態(tài)密切相關(guān)的準(zhǔn)確預(yù)測(cè)。同時(shí),可靠地量化預(yù)測(cè)不確定性對(duì)于穩(wěn)健的決策至關(guān)重要,這可以防止離線策略優(yōu)化利用錯(cuò)誤的模型預(yù)測(cè)。考慮到這些問題,作者提出了 WHALE,這是一個(gè)用于學(xué)習(xí)可泛化世界模型的框架,具有增強(qiáng)的泛化性和高效的不確定性估計(jì)。
用于泛化的行為 - 條件
根據(jù)公式(2)的誤差分解可知,世界模型的泛化誤差主要來源于策略分歧引起的誤差積累。

為了解決這個(gè)問題,一種可能的解決方案是將行為信息嵌入到世界模型中,使得模型能夠主動(dòng)識(shí)別策略的行為模式,并適應(yīng)由策略引起的分布偏移。
基于行為 - 條件,作者引入了一個(gè)學(xué)習(xí)目標(biāo),即從訓(xùn)練軌跡中獲取行為嵌入,并整合學(xué)習(xí)到的嵌入。
作者希望將訓(xùn)練軌跡 τ_H 中的決策模式提取到行為嵌入中,這讓人聯(lián)想到以歷史 τ_h 為條件的軌跡似然 ELBO(evidence lower bound)的最大化:

作者建議通過最大化 H 個(gè)決策步驟上的 ELBO 并調(diào)整類似于 β-VAE 的 KL 約束數(shù)量來學(xué)習(xí)行為嵌入:

這里,KL 項(xiàng)將子軌跡的嵌入預(yù)測(cè)約束到每個(gè)時(shí)間步驟 h,鼓勵(lì)它們近似后驗(yàn)編碼。這確保了表示保持策略一致,這意味著由相同策略生成的軌跡表現(xiàn)出相似的行為模式,從而表現(xiàn)出相似的表示。然后使用學(xué)習(xí)到的先驗(yàn)預(yù)測(cè)器 從歷史 τ_h 中獲得行為嵌入 z_h,以便在世界模型學(xué)習(xí)期間進(jìn)行行為調(diào)節(jié),其中行為嵌入被接受為未來預(yù)測(cè)的額外協(xié)變量:
從歷史 τ_h 中獲得行為嵌入 z_h,以便在世界模型學(xué)習(xí)期間進(jìn)行行為調(diào)節(jié),其中行為嵌入被接受為未來預(yù)測(cè)的額外協(xié)變量:

不確定性估計(jì) Retracing-rollout
世界模型不可避免地會(huì)產(chǎn)生不準(zhǔn)確和不可靠的樣本,先前的研究從理論和實(shí)驗(yàn)上都證明,如果無限制地使用模型生成的數(shù)據(jù),策略的性能可能會(huì)受到嚴(yán)重?fù)p害。因此,不確定性估計(jì)對(duì)于世界模型至關(guān)重要。
作者引入了一種新穎的不確定性估計(jì)方法,即 retracing-rollout。retracing-rollout 的核心創(chuàng)新在于引入了 retracing-action,它利用了具身控制中動(dòng)作空間的語義結(jié)構(gòu),從而能夠更準(zhǔn)確、更高效地估計(jì)基于 Transformer 的世界模型的不確定性。

接下來作者首先介紹了 retracing-action,具體地說,retracing-action 可以等效替代任何給定的動(dòng)作序列,形式如公式(5),其中 表示動(dòng)作 a_i 第 j 維的值。
表示動(dòng)作 a_i 第 j 維的值。

接下來是一個(gè)全新的概念:Retracing-rollout。
具體來說:假設(shè)給定一個(gè)「回溯步驟」k,整個(gè)過程開始于從當(dāng)前時(shí)間步 t,回溯到時(shí)間步 t-k,將 o_t?k 作為起始幀。
然后,執(zhí)行一個(gè)回溯動(dòng)作 ,從 o_t?k 開始,生成相應(yīng)的結(jié)果 o_k+1。
,從 o_t?k 開始,生成相應(yīng)的結(jié)果 o_k+1。
在實(shí)際操作中,為了避免 超出動(dòng)作空間的范圍,回溯動(dòng)作被分解為 k 步。在每一步中,前六個(gè)維度的動(dòng)作被設(shè)置為
超出動(dòng)作空間的范圍,回溯動(dòng)作被分解為 k 步。在每一步中,前六個(gè)維度的動(dòng)作被設(shè)置為 ,而最后一個(gè)維度
,而最后一個(gè)維度 保持不變。通過這種方式,模型可以通過多步回溯產(chǎn)生期望的結(jié)果。
保持不變。通過這種方式,模型可以通過多步回溯產(chǎn)生期望的結(jié)果。
為了估計(jì)某一時(shí)間點(diǎn) (o_t,a_t) 的不確定性,采用多種回溯步驟生成不同的回溯 - 軌跡預(yù)測(cè)結(jié)果。具體來說,要計(jì)算不同回溯 - 軌跡輸出與不使用回溯的輸出之間的「感知損失」。同時(shí),引入動(dòng)態(tài)模型的預(yù)測(cè)熵,通過將「感知損失」和預(yù)測(cè)熵相乘,得到最終的不確定性估計(jì)結(jié)果。
與基于集成的其他方法不同,retracing-rollout 方法不需要在訓(xùn)練階段進(jìn)行任何修改,因此相比集成方法,它顯著減少了計(jì)算成本。
作者在論文中還給出了具體的實(shí)例。圖 3 展示了 Whale-ST 的整體架構(gòu)。具體來說,Whale-ST 包含三個(gè)主要組件:行為調(diào)節(jié)模型、視頻 tokenizer 和動(dòng)態(tài)模型。這些模塊采用了時(shí)空 transformer 架構(gòu)。
這些設(shè)計(jì)顯著簡化了計(jì)算需求,從相對(duì)于序列長度的二次依賴關(guān)系簡化為線性依賴關(guān)系,從而降低了模型訓(xùn)練的內(nèi)存使用量和計(jì)算成本,同時(shí)提高了模型推理速度。

實(shí)驗(yàn)
該團(tuán)隊(duì)在模擬任務(wù)和現(xiàn)實(shí)世界任務(wù)上進(jìn)行了廣泛的實(shí)驗(yàn),主要是為了回答以下問題:
- Whale-ST 在模擬任務(wù)上與其他基線相比表現(xiàn)如何?行為 - 條件和 retracing-rollout 策略有效嗎?
- Whale-X 在現(xiàn)實(shí)世界任務(wù)上的表現(xiàn)如何?Whale-X 能否從互聯(lián)網(wǎng)規(guī)模數(shù)據(jù)的預(yù)訓(xùn)練中受益?
- Whale-X 的可擴(kuò)展性如何?增加模型參數(shù)或預(yù)訓(xùn)練數(shù)據(jù)是否能提高在現(xiàn)實(shí)世界任務(wù)上的表現(xiàn)?
模擬任務(wù)中的 Whale-ST
該團(tuán)隊(duì)在 Meta-World 基準(zhǔn)測(cè)試上開展實(shí)驗(yàn)。Meta-World 是一個(gè)包含多種視覺操作任務(wù)的測(cè)試集。研究者們構(gòu)建了一個(gè)包含 6 萬條軌跡的訓(xùn)練數(shù)據(jù)集,這些軌跡是從 20 個(gè)不同的任務(wù)中收集來的。模型學(xué)習(xí)算法需要使用這些數(shù)據(jù)從頭開始訓(xùn)練。
研究團(tuán)隊(duì)將 Whale-ST 與 FitVid、MCVD、DreamerV3、iVideoGPT 進(jìn)行了對(duì)比。評(píng)估指標(biāo)如下:
- 預(yù)測(cè)準(zhǔn)確性:驗(yàn)證模型是否能夠正確估計(jì)給定動(dòng)作序列的值,具體通過值差、回報(bào)相關(guān)性 (Return Correlation) 和 Regret 進(jìn)行評(píng)估;
- 視頻保真度:研究團(tuán)隊(duì)采用 FVD、PSNR、LPIPS 和 SSIM 來衡量視頻軌跡生成的質(zhì)量。
下表展示了預(yù)測(cè)準(zhǔn)確性的結(jié)果,其中,Whale-ST 在所有三個(gè)指標(biāo)上都表現(xiàn)出色。在 64 × 64 的分辨率下,Whale-ST 的值差與 DreamerV3 的最高分非常接近。當(dāng)在更高分辨率 256 × 256 測(cè)試時(shí),Whale-ST 的表現(xiàn)進(jìn)一步提升,取得了最小的值差和最高的回報(bào)相關(guān)性,反映了 Whale-ST 能更細(xì)致地理解動(dòng)態(tài)環(huán)境。

表 2 展示了視頻保真度的結(jié)果,Whale-ST 在所有指標(biāo)上均優(yōu)于其他方法,特別是 FVD 具有顯著優(yōu)勢(shì)。

不確定性估計(jì)
針對(duì)不確定性,研究團(tuán)隊(duì)比較了 retracing-rollout 與兩種基準(zhǔn)方法:
(1)基于熵的方法:研究團(tuán)隊(duì)采用基于 Transformer 的動(dòng)態(tài)模型,它通過計(jì)算模型輸出的預(yù)測(cè)熵來量化不確定性
(2)基于集成的方法:研究團(tuán)隊(duì)訓(xùn)練了三個(gè)獨(dú)立的動(dòng)態(tài)模型,然后通過比較每個(gè)模型生成的圖像之間的像素級(jí)差異來估計(jì)不確定性。
具體來說,他們從模型誤差預(yù)測(cè)和離線強(qiáng)化學(xué)習(xí)兩個(gè)角度進(jìn)行評(píng)估。
下表展示了模型誤差預(yù)測(cè)的結(jié)果,在所有 5 個(gè)任務(wù)中,retracing-rollout 均優(yōu)于其他基線方法。與基于集成的方法相比,retracing-rollout 提升了 500%,與基于熵的方法相比,提高了 50%。

下圖展示了離線 MBRL 的結(jié)果,retracing-rollout 在 5 個(gè)任務(wù)中的 3 個(gè)任務(wù)中收斂得更好、具備更強(qiáng)的穩(wěn)定性。特別是在關(guān)水龍頭和滑盤子任務(wù)中,retracing-rollout 是唯一能夠穩(wěn)定收斂的方法,而其他方法在訓(xùn)練后期出現(xiàn)了不同程度的性能下降。

Whale-X 在真實(shí)世界中的表現(xiàn)
為了評(píng)估 Whale-X 在實(shí)際物理環(huán)境中的泛化能力,研究團(tuán)隊(duì)在 ARX5 機(jī)器人上進(jìn)行了全面實(shí)驗(yàn)。
與預(yù)訓(xùn)練數(shù)據(jù)不同,評(píng)估任務(wù)調(diào)整了攝像機(jī)角度和背景等,增加了對(duì)世界模型的挑戰(zhàn)。他們收集了每個(gè)任務(wù) 60 條軌跡的數(shù)據(jù)集用于微調(diào),任務(wù)包括開箱、推盤、投球和移動(dòng)瓶子,還設(shè)計(jì)了多個(gè)模型從未接觸過的任務(wù)來測(cè)試模型的視覺、運(yùn)動(dòng)和任務(wù)泛化能力。
如圖 5 所示,Whale-X 在真實(shí)世界中展現(xiàn)出了明顯的優(yōu)勢(shì)。
具體來說:

1. 與沒有行為 - 條件的模型相比,Whale-X 的一致性提高了 63%,表明該機(jī)制顯著提升了 OOD 泛化能力;
2. 在 97 萬個(gè)樣本上進(jìn)行預(yù)訓(xùn)練的 Whale-X,比從零開始訓(xùn)練的模型具有更高的一致性,凸顯了大規(guī)模互聯(lián)網(wǎng)數(shù)據(jù)預(yù)訓(xùn)練的優(yōu)勢(shì);
3. 增加模型參數(shù)能夠提升世界模型的泛化能力。Whale-X-base(203M)動(dòng)態(tài)模型在三個(gè)未見任務(wù)中的一致性率是 77M 版本的三倍。
此外,視頻生成質(zhì)量與一致性的結(jié)果一致,如表 4 所示。通過行為 - 條件策略、大規(guī)模預(yù)訓(xùn)練數(shù)據(jù)集和擴(kuò)展模型參數(shù),三種策略結(jié)合,顯著提高了模型的 OOD 泛化能力,尤其是在生成高質(zhì)量視頻方面。

擴(kuò)展性
固定視頻 token 和行為 - 條件這兩個(gè)部分不變,僅調(diào)整模型的參數(shù)量和預(yù)訓(xùn)練數(shù)據(jù)集的大小,Whale-X 的拓展性如何呢?
研究團(tuán)隊(duì)在預(yù)訓(xùn)練階段訓(xùn)練了四個(gè)動(dòng)態(tài)模型,參數(shù)數(shù)量從 39M 到 456M 不等,結(jié)果如圖 7 的前兩幅圖所示。

這些結(jié)果表明,Whale-X 展現(xiàn)出強(qiáng)大的擴(kuò)展性:無論是增加預(yù)訓(xùn)練數(shù)據(jù)還是增加模型參數(shù),都會(huì)降低訓(xùn)練 loss。
除此之外,研究團(tuán)隊(duì)還驗(yàn)證了更大的模型在微調(diào)階段是否能夠展現(xiàn)更好的性能。
為此,他們微調(diào)了一系列動(dòng)態(tài)模型,結(jié)果如圖 7 最左側(cè)所示。不難發(fā)現(xiàn),經(jīng)過微調(diào)后,更大的模型在測(cè)試數(shù)據(jù)上表現(xiàn)出更低的 loss,進(jìn)一步突顯了 Whale-X 在真實(shí)任務(wù)中出色的擴(kuò)展性。
可視化
- 定性評(píng)估
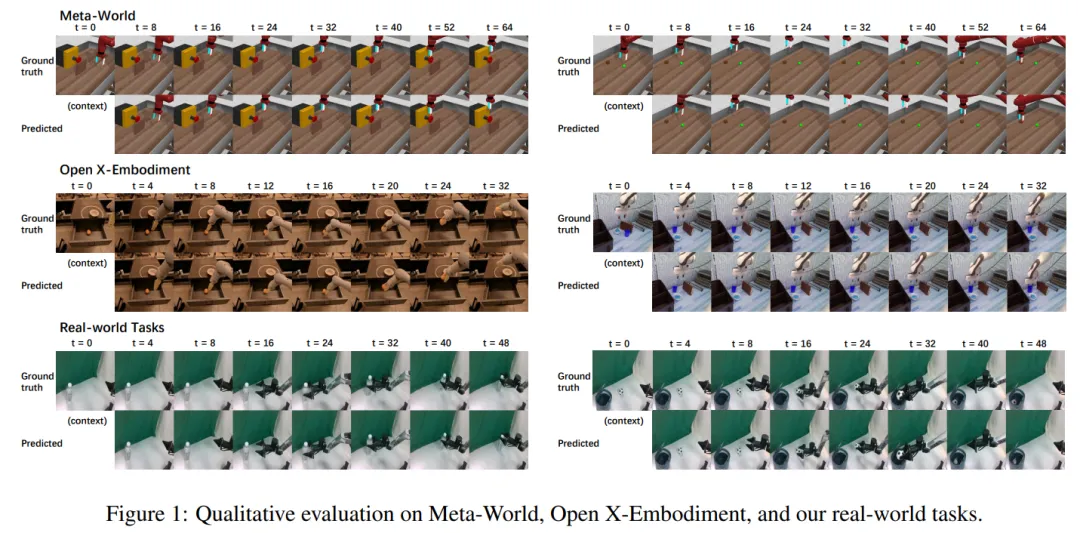
圖 1 展示了在 Meta-World、Open X-Embodiment 和研究團(tuán)隊(duì)設(shè)計(jì)的真實(shí)任務(wù)上的定性評(píng)估結(jié)果。

結(jié)果表明,Whale-ST 和 Whale-X 能夠生成高保真度的視頻軌跡,尤其是在長時(shí)間跨度的軌跡生成過程中,保持了視頻的質(zhì)量和一致性。
- 可控生成
圖 8 展示了 Whale-X 在控制性和泛化性方面的強(qiáng)大能力。給定一個(gè)未見過的動(dòng)作序列,Whale-X 能夠生成與人類理解相符的視頻,學(xué)習(xí)動(dòng)作與機(jī)器人手臂移動(dòng)之間的因果聯(lián)系。

- 行為條件可視化
通過 t-SNE 可視化,研究表明 Whale-X 成功地學(xué)習(xí)到行為嵌入,能夠區(qū)分不同策略之間的差異。例如,對(duì)于同一任務(wù),不同的策略會(huì)有不同的行為表示,而噪聲策略的嵌入則介于專家策略和隨機(jī)策略之間,體現(xiàn)了模型在策略建模上的合理性。此外,專家策略在不同任務(wù)中的嵌入也能被區(qū)分,而隨機(jī)策略則無法區(qū)分,表明模型更擅長表示和區(qū)分策略,而不是任務(wù)本身。
 更多研究細(xì)節(jié),請(qǐng)參考原文。
更多研究細(xì)節(jié),請(qǐng)參考原文。
























