北交開源o1代碼版!強化學習+蒙特卡洛樹搜索,源代碼、精選數據集以及衍生模型通通開源
北京交通大學研究團隊悄默聲推出了一版o1,而且所有源代碼、精選數據集以及衍生模型都開源!
名為O1-CODER,專注于編碼任務。
 圖片
圖片
團隊認為編碼是一個需要System-2思維方式的典型任務,涉及謹慎、邏輯、一步步的問題解決過程。
而他們的策略是將強化學習(RL)與蒙特卡洛樹搜索(MCTS)相結合,讓模型能夠不斷生成推理數據,提升其System-2能力。
實驗中,團隊有以下幾點關鍵發現:
- 當推理正確時,基于偽代碼的推理顯著提升了代碼生成質量
- 將監督微調(SFT)與直接偏好優化(DPO)相結合能夠提升測試用例生成效果
- 自我對弈強化學習為推理和代碼生成創造了持續改進的循環機制
具體來說,團隊采用了測試用例生成器,在經過DPO后達到89.2%的通過率,相比初始微調后的80.8%有顯著提升;Qwen2.5-Coder-7B采用偽代碼方法實現了74.9%的平均采樣通過率,提升了25.6%。
網友直呼很需要這樣的模型。
 圖片
圖片
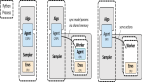
O1-CODER,究竟長啥樣?
 圖片
圖片
六步,逐步優化o1
應用于代碼生成的自我對弈強化學習面臨兩大挑戰:
- 結果評估,即如何評判生成代碼的質量。與圍棋等任務不同,評估代碼需要在測試環境中運行并驗證。
- 定義思考和搜索行為,即確定過程獎勵的對象和粒度。
對于第一個挑戰,團隊提出訓練一個測試用例生成器(TCG),根據問題和標準代碼自動生成測試用例,為強化學習提供標準化的代碼測試環境和結果獎勵。
對于第二個挑戰,他們采取”先思考后行動“的方式:先通過詳細的偽代碼思考問題,再基于偽代碼生成最終的可執行代碼。
這種方式的優勢在于適應性(同一偽代碼可對應不同的具體實現)和可控粒度(通過調整偽代碼的細節程度控制推理/搜索行為的粒度)。
具體來說,研究團隊提出了一個包含六個步驟的框架:
- 訓練測試用例生成器(TCG),為代碼測試提供標準化的環境
- 利用MCTS生成包含推理過程的代碼數據
- 迭代微調策略模型,先生成偽代碼,再生成完整代碼
- 基于推理過程數據初始化過程獎勵模型(PRM)
- 在TCG提供的結果獎勵和PRM提供的過程獎勵的雙重引導下,通過強化學習和MCTS更新策略模型
- 利用優化后的策略模型生成新的推理數據,返回第4步迭代訓練
 圖片
圖片
兩階段訓練測試用例生成器
在實驗部分,研究人員詳細介紹了測試用例生成器的訓練過程。
分為兩個階段:監督微調(SFT)和直接偏好優化(DPO)。
SFT階段的主要目標是確保生成器的輸出符合預定義格式,以便準確解析和提取生成的測試用例。訓練數據來自TACO數據集。
 圖片
圖片
DPO階段的目標是引導模型生成符合特定偏好的測試用例,進一步提高生成器的性能和可靠性。
這里采用了帶有人工構建樣本對的DPO方法,構建了一個偏好數據集。
實驗表明,SFT階段過后,TCG在標準代碼上生成的測試用例通過率達到80.8%,DPO階段進一步提升至89.2%,大幅改善了生成器產出可靠測試用例的能力。
偽代碼推理,引導模型進行深度推理
特別值得一提的是,研究者引入了基于偽代碼的提示方法,將其作為引導模型進行深度推理的“認知工具”。
 圖片
圖片
他們為此定義了三個關鍵行為:
- 使用偽代碼定義算法結構:勾勒主要函數的結構和接口,把握任務的整體框架
- 細化偽代碼:逐步明確每個函數的具體步驟、邏輯和操作
- 從偽代碼生成代碼:將偽代碼的結構和邏輯精準翻譯為可執行代碼
 圖片
圖片
在MBPP數據集上進行的初步實驗表明,盡管整體通過率(Pass@1)有所下降,但Average Sampling Pass Rate(ASPR)顯著提高。
 圖片
圖片
表明結合偽代碼顯著改善了推理過程的質量,特別是在細化通向正確輸出的路徑方面。這為后續的自監督微調和強化學習提供了良好的起點。
自我對弈+強化學習
研究人員詳細描述了如何使用蒙特卡洛樹搜索(MCTS)來構建步驟級別的過程獎勵數據。
這個過程涉及到為每個問題形成一個推理路徑,該路徑由一系列推理步驟組成,并最終產生一個可執行的代碼。在MCTS的路徑探索中,使用偽代碼提示策略來引導推理過程。當達到終端節點時,就形成了一個完整的偽代碼推理路徑。
終端節點的獎勵值是基于兩個關鍵指標計算的:編譯成功率(compile)和測試用例通過率(pass)。
 圖片
圖片
這些指標被用來評估生成的代碼的質量和正確性。
獎勵值被反向傳播到路徑上的所有前序節點,為每個步驟分配一個獎勵值。通過這種方式,構建了推理過程數據集,為策略模型的初始化和訓練提供了基礎。
 圖片
圖片
過程獎勵模型(PRM)的任務是為當前步驟分配一個獎勵值,以估計其對最終答案的貢獻。
在數據合成過程中使用的樹搜索方法可以組織成點式(point-wise)和成對式(pair-wise)兩種數據格式。
 圖片
圖片
基于這些經過驗證的正確推理解,策略模型得到初始化。
接下來,過程獎勵模型(PRM)開始發揮作用,評估每一步推理對最終答案的貢獻。在測試用例生成器(TCG)提供的結果獎勵和PRM提供的過程獎勵的雙重引導下,策略模型通過強化學習不斷改進。
更新后的策略模型被用來生成新的推理數據,補充到現有數據集中,形成自我對弈的閉環。這個數據生成-獎勵建模-策略優化的迭代循環,確保了系統推理能力的持續提升。
論文鏈接:https://arxiv.org/pdf/2412.00154
參考鏈接:https://x.com/rohanpaul_ai/status/1864488583744377271?s=46&t=iTysI4vQLQqCNJjSmBODPw