














譯者 | 朱先忠
審校 | 重樓
引言
想象一下,你正在手術(shù)過程中控制著一臺(tái)機(jī)械臂。此機(jī)械臂的離散動(dòng)作可能有:
- 向上移動(dòng)
- 向下移動(dòng)
- 抓取
或
- 釋放
這些都是明確、直接的命令,在簡單情況下是易于執(zhí)行的。但是,如果執(zhí)行精細(xì)的動(dòng)作,例如:
- 將手臂移動(dòng)0.5毫米以避免損傷組織
- 施加3N的力以壓縮組織
或
- 旋轉(zhuǎn)手腕15°以調(diào)整切口角度
該怎么辦呢?
在這些情況下,你需要的不僅僅是選擇一個(gè)動(dòng)作——你必須決定需要多少動(dòng)作。這是連續(xù)動(dòng)作空間的世界,也是深度確定性策略梯度(DDPG)算法大放異彩的地方!
像深度Q網(wǎng)絡(luò)(DQN)這樣的傳統(tǒng)方法在離散動(dòng)作方面效果很好,但在連續(xù)動(dòng)作方面卻舉步維艱。另一方面,確定性策略梯度(DPG)算法解決了這個(gè)問題,但面臨著探索性差和不穩(wěn)定的挑戰(zhàn)。DDPG算法最早是在TP.Lillicrap等人的論文中提出的,它結(jié)合了DPG算法和DQN算法的優(yōu)勢,以提高連續(xù)動(dòng)作空間環(huán)境中的穩(wěn)定性和性能。
在本文中,我們將討論DDPG算法背后的理論和架構(gòu),研究它在Python上的實(shí)現(xiàn),評(píng)估其性能(通過在MountainCarContinuous游戲上進(jìn)行測試),并簡要討論如何在生物工程領(lǐng)域使用DDPG算法。
DDPG算法架構(gòu)
與評(píng)估每個(gè)可能的“狀態(tài)-動(dòng)作”對(duì)以找到最佳動(dòng)作(由于組合無限,在連續(xù)空間中不可能)的DQN算法不同,DPG算法使用的是“演員-評(píng)論家(Actor-Critic)”架構(gòu)。演員學(xué)習(xí)一種將狀態(tài)直接映射到動(dòng)作的策略,避免詳盡的搜索并專注于學(xué)習(xí)每個(gè)狀態(tài)的最佳動(dòng)作。
但是,DPG算法面臨兩個(gè)主要挑戰(zhàn):
- 它是一種確定性算法,限制了對(duì)動(dòng)作空間的探索。
- 由于學(xué)習(xí)過程不穩(wěn)定,它無法有效地使用神經(jīng)網(wǎng)絡(luò)。
DDPG算法通過Ornstein-Uhlenbeck過程引入探索噪聲,并使用批量歸一化和DQN技術(shù)(如重放緩沖區(qū)和目標(biāo)網(wǎng)絡(luò))穩(wěn)定訓(xùn)練,從而改進(jìn)了DPG算法。
借助這些增強(qiáng)功能,DDPG算法非常適合在連續(xù)動(dòng)作空間中訓(xùn)練AI代理,例如在生物工程應(yīng)用中控制機(jī)器人系統(tǒng)。
接下來,讓我們深入探索DDPG模型的關(guān)鍵組成!
演員-評(píng)論家(Actor-Critic)框架
- 演員(策略網(wǎng)絡(luò)):根據(jù)代理所處的狀態(tài)告訴代理要采取哪種操作。網(wǎng)絡(luò)的參數(shù)(即權(quán)重)用θμ表示。
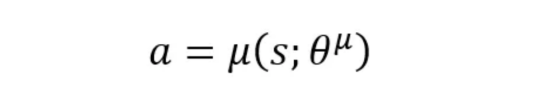
【提示】將演員網(wǎng)絡(luò)視為決策者:它將當(dāng)前狀態(tài)映射到單個(gè)動(dòng)作。
- 評(píng)論家(Q值網(wǎng)絡(luò)):通過估計(jì)該狀態(tài)-動(dòng)作對(duì)的Q值來評(píng)估演員采取的行動(dòng)有多好。
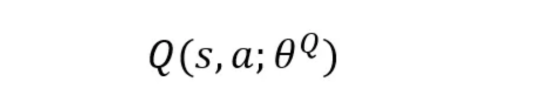
提示!將CriticNetwork視為評(píng)估者,它為每個(gè)動(dòng)作分配一個(gè)質(zhì)量分?jǐn)?shù),并幫助改進(jìn)演員的策略,以確保它確實(shí)在每個(gè)給定狀態(tài)下生成最佳動(dòng)作。
注意!評(píng)論家將使用估計(jì)的Q值做兩件事:
1. 改進(jìn)演員的策略(演員策略更新)。
演員的目標(biāo)是調(diào)整其參數(shù)(θμ),以便輸出最大化評(píng)論家的Q值的動(dòng)作。
為此,演員需要了解所選動(dòng)作a如何影響評(píng)論家的Q值,以及其內(nèi)部參數(shù)如何影響其策略,這通過此策略梯度方程完成(它是從小批量計(jì)算出的所有梯度的平均值):
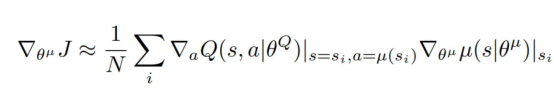
2. 通過最小化下面的損失函數(shù)來改進(jìn)其自己的網(wǎng)絡(luò)(評(píng)論家Q值網(wǎng)絡(luò)更新)。
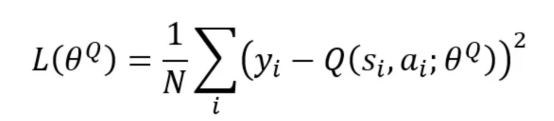
其中,N是在小批量中采樣的經(jīng)驗(yàn)數(shù),y_i是按如下方式計(jì)算的目標(biāo)Q值。
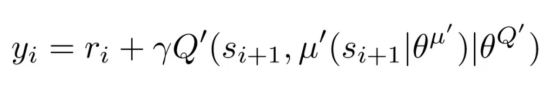
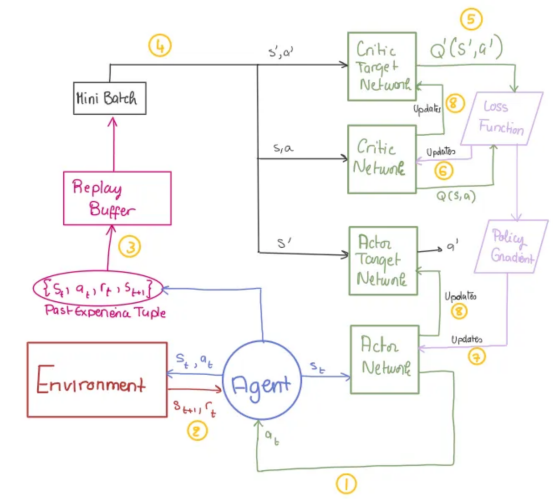
重放緩沖區(qū)
當(dāng)代理探索環(huán)境時(shí),過去的經(jīng)驗(yàn)(狀態(tài)、動(dòng)作、獎(jiǎng)勵(lì)、下一個(gè)狀態(tài))會(huì)作為元組(s,a,r,s′)存儲(chǔ)在重放緩沖區(qū)中。在訓(xùn)練期間,會(huì)隨機(jī)抽取由其中一些經(jīng)驗(yàn)組成的小批量來訓(xùn)練代理。
問題!重放緩沖區(qū)實(shí)際上如何減少不穩(wěn)定性?
通過隨機(jī)抽取經(jīng)驗(yàn),重放緩沖區(qū)打破了連續(xù)樣本之間的相關(guān)性,減少了偏差并帶來了更穩(wěn)定的訓(xùn)練。
目標(biāo)網(wǎng)絡(luò)
目標(biāo)網(wǎng)絡(luò)是演員和評(píng)論家的緩慢更新副本。它們提供穩(wěn)定的Q值目標(biāo),防止快速變化并確保平穩(wěn)、一致的更新。
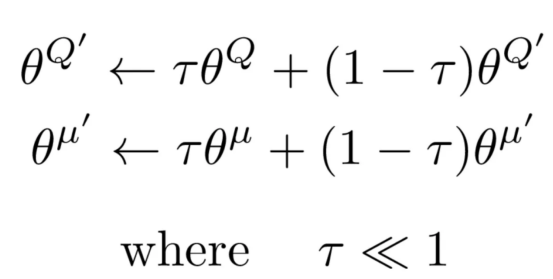
【問題】目標(biāo)網(wǎng)絡(luò)實(shí)際上如何減少不穩(wěn)定性?
如果沒有評(píng)論家目標(biāo)網(wǎng)絡(luò),則目標(biāo)Q值直接從評(píng)論家Q值網(wǎng)絡(luò)計(jì)算,該網(wǎng)絡(luò)會(huì)不斷更新。這會(huì)導(dǎo)致目標(biāo)Q值在每一步都發(fā)生變化,從而產(chǎn)生“移動(dòng)目標(biāo)”問題。因此,評(píng)論家最終會(huì)追逐不斷變化的目標(biāo),導(dǎo)致訓(xùn)練不穩(wěn)定。
此外,由于演員依賴于評(píng)論家的反饋,因此一個(gè)網(wǎng)絡(luò)中的錯(cuò)誤會(huì)放大另一個(gè)網(wǎng)絡(luò)中的錯(cuò)誤,從而形成相互依賴的不穩(wěn)定循環(huán)。
通過引入使用軟更新規(guī)則逐步更新的目標(biāo)網(wǎng)絡(luò),我們確保目標(biāo)Q值保持更一致,從而減少突然變化并提高學(xué)習(xí)穩(wěn)定性。
批量歸一化
批量歸一化將輸入歸一化到神經(jīng)網(wǎng)絡(luò)的每一層,確保平均值為零且方差為1個(gè)單位。
【問題】批量歸一化實(shí)際上如何減少不穩(wěn)定性?
從重放緩沖區(qū)中提取的樣本可能具有與實(shí)時(shí)數(shù)據(jù)不同的分布,從而導(dǎo)致網(wǎng)絡(luò)更新期間不穩(wěn)定。
批量歸一化確保輸入的一致縮放,以防止由輸入分布變化引起的不穩(wěn)定更新。
探索噪聲
由于演員的策略是確定性的,因此在訓(xùn)練期間將探索噪聲添加到動(dòng)作中,以鼓勵(lì)代理探索盡可能多的動(dòng)作空間。
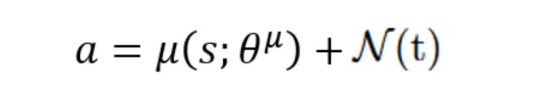
在DDPG論文中,作者使用Ornstein-Uhlenbeck過程生成時(shí)間相關(guān)噪聲,以模擬現(xiàn)實(shí)世界的系統(tǒng)動(dòng)態(tài)。
DDPG算法偽代碼:分步分解

此偽代碼取自http://arxiv.org/abs/1509.02971(參見“參考文獻(xiàn)1”)。
- 定義演員和評(píng)論家網(wǎng)絡(luò):
class Actor(nn.Module):
"""
針對(duì)DDPG算法的演員網(wǎng)絡(luò)。
"""
def __init__(self, state_dim, action_dim, max_action,use_batch_norm):
"""
初始化演員的策略網(wǎng)絡(luò)
:參數(shù)state_dim: 狀態(tài)空間的維度
:參數(shù)action_dim: 動(dòng)作空間的維度
:參數(shù)max_action: 動(dòng)作的最大值
"""
super(Actor, self).__init__()
self.bn1 = nn.LayerNorm(HIDDEN_LAYERS_ACTOR) if use_batch_norm else nn.Identity()
self.bn2 = nn.LayerNorm(HIDDEN_LAYERS_ACTOR) if use_batch_norm else nn.Identity()
self.l1 = nn.Linear(state_dim, HIDDEN_LAYERS_ACTOR)
self.l2 = nn.Linear(HIDDEN_LAYERS_ACTOR, HIDDEN_LAYERS_ACTOR)
self.l3 = nn.Linear(HIDDEN_LAYERS_ACTOR, action_dim)
self.max_action = max_action
def forward(self, state):
"""
通過網(wǎng)絡(luò)正向傳播。
:參數(shù)state: 輸入狀態(tài)
:返回值: 動(dòng)作
"""
a = torch.relu(self.bn1(self.l1(state)))
a = torch.relu(self.bn2(self.l2(a)))
return self.max_action * torch.tanh(self.l3(a))
class Critic(nn.Module):
"""
針對(duì)DDPG算法的評(píng)論家網(wǎng)絡(luò)。
"""
def __init__(self, state_dim, action_dim,use_batch_norm):
"""
初始化評(píng)論家的值網(wǎng)絡(luò)。
:參數(shù)state_dim: 狀態(tài)空間的維度
:參數(shù)action_dim: 動(dòng)作空間的維度
"""
super(Critic, self).__init__()
self.bn1 = nn.BatchNorm1d(HIDDEN_LAYERS_CRITIC) if use_batch_norm else nn.Identity()
self.bn2 = nn.BatchNorm1d(HIDDEN_LAYERS_CRITIC) if use_batch_norm else nn.Identity()
self.l1 = nn.Linear(state_dim + action_dim, HIDDEN_LAYERS_CRITIC)
self.l2 = nn.Linear(HIDDEN_LAYERS_CRITIC, HIDDEN_LAYERS_CRITIC)
self.l3 = nn.Linear(HIDDEN_LAYERS_CRITIC, 1)
def forward(self, state, action):
"""
通過網(wǎng)絡(luò)的正向傳播。
:參數(shù)state:輸入狀態(tài)
:參數(shù)action: 輸入動(dòng)作
:返回值: “狀態(tài)-動(dòng)作”對(duì)的Q-值
"""
q = torch.relu(self.bn1(self.l1(torch.cat([state, action], 1))))
q = torch.relu(self.bn2(self.l2(q)))
return self.l3(q)- 定義重放緩沖區(qū)
實(shí)現(xiàn)ReplayBuffer類來存儲(chǔ)和采樣上一節(jié)中討論的轉(zhuǎn)換元組(s,a,r,s’),以實(shí)現(xiàn)小批量離策略學(xué)習(xí)。
class ReplayBuffer:
def __init__(self, capacity):
self.buffer = deque(maxlen=capacity)
def push(self, state, action, reward, next_state, done):
self.buffer.append((state, action, reward, next_state, done))
def sample(self, batch_size):
return random.sample(self.buffer, batch_size)
def __len__(self):
return len(self.buffer)- 定義OU噪聲類
添加OUNoise類來生成探索噪聲,幫助代理更有效地探索動(dòng)作空間。
"""
節(jié)選自https://github.com/vitchyr/rlkit/blob/master/rlkit/exploration_strategies/ou_strategy.py
"""
class OUNoise(object):
def __init__(self, action_space, mu=0.0, theta=0.15, max_sigma=0.3, min_sigma=0.3, decay_period=100000):
self.mu = mu
self.theta = theta
self.sigma = max_sigma
self.max_sigma = max_sigma
self.min_sigma = min_sigma
self.decay_period = decay_period
self.action_dim = action_space.shape[0]
self.low = action_space.low
self.high = action_space.high
self.reset()
def reset(self):
self.state = np.ones(self.action_dim) * self.mu
def evolve_state(self):
x = self.state
dx = self.theta * (self.mu - x) + self.sigma * np.random.randn(self.action_dim)
self.state = x + dx
return self.state
def get_action(self, action, t=0):
ou_state = self.evolve_state()
self.sigma = self.max_sigma - (self.max_sigma - self.min_sigma) * min(1.0, t / self.decay_period)
return np.clip(action + ou_state, self.low, self.high)- 定義DDPG代理
定義了一個(gè)DDPG類,它負(fù)責(zé)封裝代理的行為:
初始化:創(chuàng)建演員和評(píng)論家網(wǎng)絡(luò),以及它們的目標(biāo)對(duì)應(yīng)方和重放緩沖區(qū)。
class DDPG():
"""
深度確定性策略梯度(DDPG)代理。
"""
def __init__(self, state_dim, action_dim, max_action,use_batch_norm):
"""
初始化DDPG算法代理。
:參數(shù)state_dim: 狀態(tài)空間的維度
:參數(shù)action_dim: 動(dòng)作空間的維度
:參數(shù)max_action: 動(dòng)作的最大值
"""
# [第0步]
#初始化演員的策略網(wǎng)絡(luò)
self.actor = Actor(state_dim, action_dim, max_action,use_batch_norm)
# 使用與演員的策略網(wǎng)絡(luò)相同的權(quán)重初始化演員目標(biāo)網(wǎng)絡(luò)
self.actor_target = Actor(state_dim, action_dim, max_action,use_batch_norm)
self.actor_target.load_state_dict(self.actor.state_dict())
self.actor_optimizer = optim.Adam(self.actor.parameters(), lr=ACTOR_LR)
#初始化評(píng)論家的值網(wǎng)絡(luò)
self.critic = Critic(state_dim, action_dim,use_batch_norm)
#使用與評(píng)論家的值網(wǎng)絡(luò)相同的權(quán)重初始化評(píng)論家的目標(biāo)網(wǎng)絡(luò)
self.critic_target = Critic(state_dim, action_dim,use_batch_norm)
self.critic_target.load_state_dict(self.critic.state_dict())
self.critic_optimizer = optim.Adam(self.critic.parameters(), lr=CRITIC_LR)
#初始化重放緩沖區(qū)
self.replay_buffer = ReplayBuffer(BUFFER_SIZE)動(dòng)作選擇:select_action方法根據(jù)當(dāng)前策略選擇動(dòng)作。
def select_action(self, state):
"""
根據(jù)當(dāng)前狀態(tài)選擇一個(gè)動(dòng)作。
:參數(shù)state:當(dāng)前狀態(tài)
:返回值:選擇的動(dòng)作
"""
state = torch.FloatTensor(state.reshape(1, -1))
action = self.actor(state).cpu().data.numpy().flatten()
return action訓(xùn)練:訓(xùn)練方法定義了如何使用重放緩沖區(qū)中的經(jīng)驗(yàn)來更新網(wǎng)絡(luò)。
注意:由于本文介紹了使用目標(biāo)網(wǎng)絡(luò)和批量歸一化來提高穩(wěn)定性,因此我設(shè)計(jì)了訓(xùn)練方法,允許我們打開或關(guān)閉這些方法。這讓我們可以比較代理在使用和不使用它們的情況下的性能。請(qǐng)參閱下面的代碼以了解詳細(xì)的實(shí)現(xiàn)。
def train(self, use_target_network,use_batch_norm):
"""
訓(xùn)練DDPG代理
:參數(shù)use_target_network: 是否使用目標(biāo)網(wǎng)絡(luò)
:參數(shù)use_batch_norm: 是否使用批量歸一化
"""
if len(self.replay_buffer) < BATCH_SIZE:
return
# [第4步]. 從重放緩沖區(qū)中抽取一批樣本
batch = self.replay_buffer.sample(BATCH_SIZE)
state, action, reward, next_state, done = map(np.stack, zip(*batch))
state = torch.FloatTensor(state)
action = torch.FloatTensor(action)
next_state = torch.FloatTensor(next_state)
reward = torch.FloatTensor(reward.reshape(-1, 1))
done = torch.FloatTensor(done.reshape(-1, 1))
#評(píng)論家網(wǎng)絡(luò)更新#
if use_target_network:
target_Q = self.critic_target(next_state, self.actor_target(next_state))
else:
target_Q = self.critic(next_state, self.actor(next_state))
# [第5步]. 計(jì)算目標(biāo)Q-value (y_i)
target_Q = reward + (1 - done) * GAMMA * target_Q
current_Q = self.critic(state, action)
critic_loss = nn.MSELoss()(current_Q, target_Q.detach())
# [第6步]. 使用梯度下降來更新評(píng)論家網(wǎng)絡(luò)的權(quán)重
#以最小化損失函數(shù)
self.critic_optimizer.zero_grad()
critic_loss.backward()
self.critic_optimizer.step()
#更新演員網(wǎng)絡(luò)#
actor_loss = -self.critic(state, self.actor(state)).mean()
# [第7步]. 使用梯度下降來更新演員網(wǎng)絡(luò)的權(quán)重
#以最小化損失函數(shù)和最大化Q-value => 選擇產(chǎn)生最高累積獎(jiǎng)勵(lì)的動(dòng)作
self.actor_optimizer.zero_grad()
actor_loss.backward()
self.actor_optimizer.step()
# [第8步]. 更新目標(biāo)網(wǎng)絡(luò)
if use_target_network:
for param, target_param in zip(self.critic.parameters(), self.critic_target.parameters()):
target_param.data.copy_(TAU * param.data + (1 - TAU) * target_param.data)
for param, target_param in zip(self.actor.parameters(), self.actor_target.parameters()):
target_param.data.copy_(TAU * param.data + (1 - TAU) * target_param.data)- 訓(xùn)練DDPG代理
將所有定義的類和方法整合在一起,我們就可以訓(xùn)練DDPG代理。我的train_dppg函數(shù)遵循偽代碼和DDPG模型圖結(jié)構(gòu)。
提示:為了讓你更容易理解,我已將每個(gè)代碼部分標(biāo)記為偽代碼和圖表中相應(yīng)的步驟編號(hào)。希望對(duì)你有所幫助!
def train_ddpg(use_target_network, use_batch_norm, num_episodes=NUM_EPISODES):
"""
訓(xùn)練DDPG代理
:參數(shù)use_target_network: 是否使用目標(biāo)網(wǎng)絡(luò)
:參數(shù)use_batch_norm: 是否使用批量歸一化
:參數(shù)num_episodes: 需要訓(xùn)練的回合數(shù)
:返回值: 回合獎(jiǎng)勵(lì)列表
"""
agent = DDPG(state_dim, action_dim, 1,use_batch_norm)
episode_rewards = []
noise = OUNoise(env.action_space)
for episode in range(num_episodes):
state= env.reset()
noise.reset()
episode_reward = 0
done = False
step=0
while not done:
action_actor = agent.select_action(state)
action = noise.get_action(action_actor,step) # Add noise for exploration
next_state, reward, done,_= env.step(action)
done = float(done) if isinstance(done, (bool, int)) else float(done[0])
agent.replay_buffer.push(state, action, reward, next_state, done)
if len(agent.replay_buffer) > BATCH_SIZE:
agent.train(use_target_network,use_batch_norm)
state = next_state
episode_reward += reward
step+=1
episode_rewards.append(episode_reward)
if (episode + 1) % 10 == 0:
print(f"Episode {episode + 1}: Reward = {episode_reward}")
return agent, episode_rewards性能和結(jié)果:DDPG算法有效性評(píng)估
至此,我們已經(jīng)在MountainCarContinuous-v0環(huán)境中測試了DDPG算法在連續(xù)動(dòng)作空間中的有效性。在該環(huán)境中,代理學(xué)會(huì)了如何獲得動(dòng)力以將汽車開上陡峭的山坡。結(jié)果表明,與其他配置相比,使用目標(biāo)網(wǎng)絡(luò)和批量歸一化可以實(shí)現(xiàn)更快的收斂、更高的獎(jiǎng)勵(lì)和更穩(wěn)定的學(xué)習(xí)。
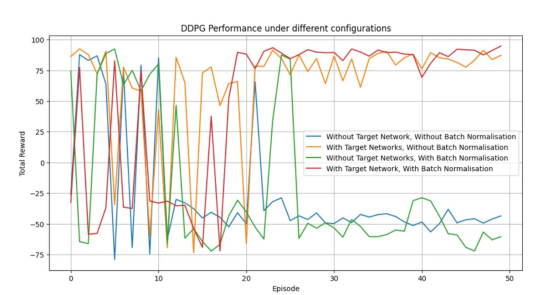
作者本人生成的圖表

作者本人生成的GIF動(dòng)畫
注意:你可以通過運(yùn)行從我的GitHub代碼倉庫下載的代碼并根據(jù)需要更改環(huán)境名稱,然后在你選擇的任何環(huán)境中自行實(shí)現(xiàn)此功能!
生物工程領(lǐng)域的DDPG算法:高精度和適應(yīng)性
通過本文的介紹,我們已經(jīng)看到DDPG是一種強(qiáng)大的算法,可用于在具有連續(xù)動(dòng)作空間的環(huán)境中訓(xùn)練代理。通過結(jié)合DPG算法和DQN算法的技術(shù),DDPG算法可以提高探索、穩(wěn)定性和性能——這正是機(jī)器人手術(shù)和生物工程應(yīng)用的關(guān)鍵因素。
想象一下,像達(dá)芬奇系統(tǒng)(da Vinci system)這樣的機(jī)器人外科醫(yī)生使用DDPG實(shí)時(shí)控制精細(xì)動(dòng)作,確保精確調(diào)整而不會(huì)出現(xiàn)任何錯(cuò)誤。借助DDPG算法,機(jī)器人可以以毫米為單位調(diào)整手臂的位置,在縫合時(shí)施加精確的力,甚至可以輕微旋轉(zhuǎn)手腕以獲得最佳切口。這種實(shí)時(shí)精度可以改變手術(shù)結(jié)果,縮短恢復(fù)時(shí)間,并最大限度地減少人為錯(cuò)誤。
但DDPG算法的潛力不僅限于醫(yī)學(xué)手術(shù)領(lǐng)域。它已經(jīng)推動(dòng)了生物工程的發(fā)展,使機(jī)器人假肢和輔助設(shè)備能夠復(fù)制人類肢體的自然運(yùn)動(dòng)(有興趣的讀者可以查看這篇有趣的文章:https://www.tandfonline.com/doi/abs/10.1080/00207179.2023.2201644)。
現(xiàn)在,我們已經(jīng)介紹了DDPG算法背后的理論,是時(shí)候由你來探索它的實(shí)際應(yīng)用了。你可以從簡單的例子開始,逐漸深入到更復(fù)雜的實(shí)戰(zhàn)場景!
參考文獻(xiàn)
- Lillicrap TP、Hunt JJ、Pritzel A、Heess N、Erez T、Tassa Y等人。使用深度強(qiáng)化學(xué)習(xí)的連續(xù)控制(Continuous control with deep reinforcement learning [Internet])。arXiv;2019年。出處:http://arxiv.org/abs/1509.02971
譯者介紹
朱先忠,51CTO社區(qū)編輯,51CTO專家博客、講師,濰坊一所高校計(jì)算機(jī)教師,自由編程界老兵一枚。
原文標(biāo)題:Understanding DDPG: The Algorithm That Solves Continuous Action Control Challenges,作者:Sirine Bhouri
















