CVPR 2024 Spotlight | 解鎖圖像編輯新境界, 北大、騰訊提出DiffEditor,讓精細編輯更簡單!
本文經AIGC Studio公眾號授權轉載,轉載請聯系出處。
在圖像生成領域,大型文本到圖像(T2I)擴散模型近年來取得了革命性的突破。然而,將這些強大的生成能力轉化為精細的圖像編輯任務,仍面臨諸多挑戰。CVPR 2024, 來自北京大學深圳研究生院與騰訊PCG的研究團隊提出了一種創新的圖像編輯方法——DiffEditor,該方法不僅顯著提升了編輯的準確性和靈活性,還拓寬了擴散模型在圖像編輯領域的應用邊界。 DiffEditor可以對一般圖像執行各種細粒度的圖像編輯操作。給定一張圖片,用戶可以選擇一個對象進行移動或調整大小,也可以選擇多個像素點進行更精確的內容拖動。此外,用戶還可以選擇參考圖像進行跨圖像編輯,即對象粘貼和外觀替換。
DiffEditor可以對一般圖像執行各種細粒度的圖像編輯操作。給定一張圖片,用戶可以選擇一個對象進行移動或調整大小,也可以選擇多個像素點進行更精確的內容拖動。此外,用戶還可以選擇參考圖像進行跨圖像編輯,即對象粘貼和外觀替換。

相關鏈接
- 論文:https://arxiv.org/pdf/2402.02583
- 項目:https://github.com/MC-E/DragonDiffusion
背景與挑戰
現有的基于擴散模型的圖像編輯方法,如DragDiff和DragonDiff,雖然在一定程度上實現了圖像的精細編輯,但仍存在局限性。DragDiff受限于GAN模型的容量,而DragonDiff則在編輯過程中犧牲了部分靈活性。此外,這些方法往往忽視了文本提示在精細編輯中的潛在作用,導致編輯結果在某些場景下缺乏細節和準確性。
方法
 DiffEditor 概述,它由可訓練的圖像提示編碼器和帶有不需要訓練的編輯指導的擴散采樣組成。
DiffEditor 概述,它由可訓練的圖像提示編碼器和帶有不需要訓練的編輯指導的擴散采樣組成。
- 引入圖像提示:DiffEditor首次嘗試將圖像提示引入精細圖像編輯任務中,與文本提示相結合,為編輯內容提供了更詳細的描述,從而顯著提高了編輯質量。
- 區域SDE策略:為了提升編輯的靈活性,DiffEditor提出了一種區域隨機微分方程(SDE)策略,該策略能夠在編輯區域注入隨機性,同時保持其他區域的內容一致性。
- 時間旅行策略:為了進一步改善編輯質量,DiffEditor引入了時間旅行策略,在單個擴散時間步內建立循環指導,從而精煉編輯效果。
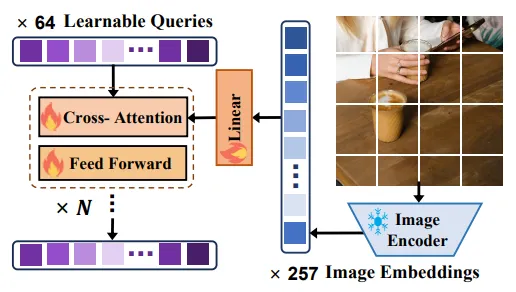
圖像提示編碼器設計說明
實驗與性能

DiffEditor與其他面部處理方法的定性比較。當前點和目標點用紅色和藍色標記嗎,白線表示距離,結果和目標之間的 MSE 距離用黃色標記。

提出的方法與其他方法在外觀替換、對象粘貼和對象移動任務上的視覺比較。

不同擴散模型上的編輯結果可視化。
綜上所示,研究團隊通過大量實驗驗證了DiffEditor在各種精細圖像編輯任務(如內容拖動、對象移動、縮放、粘貼和外觀替換)中的優越性能。與現有的基于擴散和GAN的方法相比,DiffEditor不僅具有更高的編輯準確性和內容一致性,還保持了良好的靈活性。特別是在需要想象新內容的場景中,DiffEditor能夠產生更自然的結果。
結論
DiffEditor是一種高效且靈活的圖像編輯方法,能夠無縫融入各種精細圖像編輯任務,無需針對特定任務進行訓練。盡管DiffEditor已經取得了顯著成果,但在某些需要大量內容想象的場景中,如旋轉汽車的前部,仍存在一定的編輯難度。研究團隊認為,這主要歸因于基礎模型SD的多樣性限制。未來,他們將繼續探索更先進的模型架構和訓練策略,以進一步拓展DiffEditor的應用范圍和編輯能力。