













成本不到150元!李飛飛等26分鐘訓(xùn)出個推理模型,媲美o1和R1,秘訣:用蒸餾
成本不到150元,訓(xùn)練出一個媲美DeepSeek-R1和OpenAI o1的推理模型?!
這不是洋蔥新聞,而是AI教母李飛飛、斯坦福大學(xué)、華盛頓大學(xué)、艾倫人工智能實驗室等攜手推出的最新杰作:s1。
在數(shù)學(xué)和編程能力的評測集上,s1的表現(xiàn)比肩DeepSeek-R1和o1。

而訓(xùn)一個這樣性能的模型,團隊僅僅用了16個英偉達H100,訓(xùn)練耗時26分鐘。
據(jù)TechCrunch,這個訓(xùn)練過程消耗了不到50美元的云計算成本,約合人民幣364.61元;而s1模型作者之一表示,訓(xùn)練s1所需的計算資源,在當(dāng)下約花20美元(約145.844元)就能租到。
怎么做到的???
s1團隊表示,秘訣只有一個:蒸餾。
簡單來說,團隊以阿里通義團隊的Qwen2.5- 32B-Instruct作為基礎(chǔ)模型,通過蒸餾谷歌DeepMind的推理模型Gemini 2.0 Flash Thinking實驗版,最終得到了s1模型。
為了訓(xùn)練s1,研究團隊創(chuàng)建了一個包含1000個問題(精心挑選那種)的數(shù)據(jù)集,且每個問題都附有答案,以及Gemini 2.0 Flash Thinking實驗版的思考過程。
目前,項目論文《s1: Simple test-time scaling》已經(jīng)掛上arXiv,模型s1也已在GitHub上開源,研究團隊提供了訓(xùn)練它的數(shù)據(jù)和代碼。
150元成本,訓(xùn)練26分鐘
s1團隊搞這個花活,起因是OpenAI o1展現(xiàn)了Test-time Scaling的能力。
即「在推理階段通過增加計算資源或時間,來提升大模型的性能」,這是原本預(yù)訓(xùn)練Scaling Law達到瓶頸后的一種新Scaling。
但OpenAI并未公開是如何實現(xiàn)這一點的。
在復(fù)現(xiàn)狂潮之下,s1團隊的目標(biāo)是尋找到Test-time Scaling的簡單方法。
過程中,研究人員先構(gòu)建了一個1000個樣本的數(shù)據(jù)集,名為s1K。
起初,在遵循質(zhì)量、難度、多樣性原則的基礎(chǔ)上,這個數(shù)據(jù)集收集了來自MATH、AGIEval等諸多來源的59029個問題。
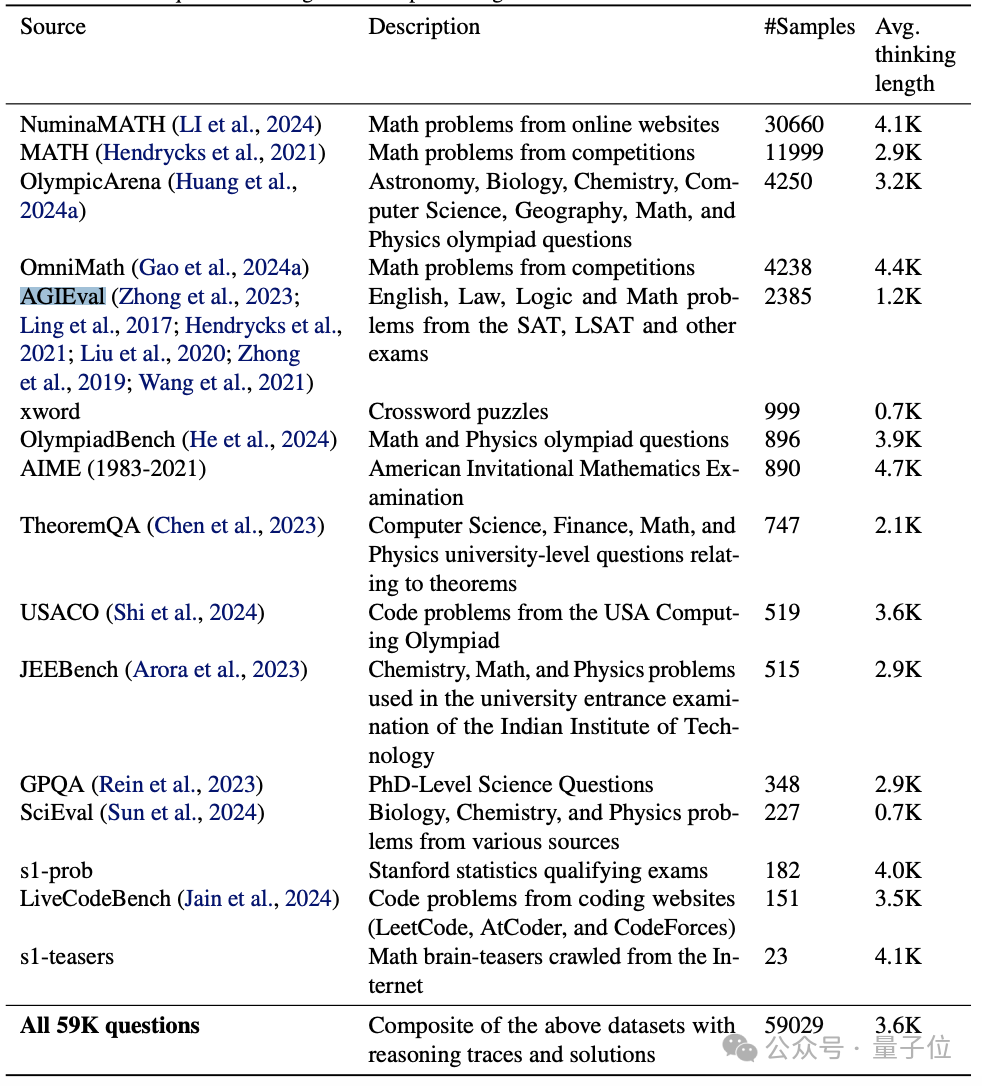
經(jīng)去重、去噪后,通過質(zhì)量篩選、基于模型性能和推理痕跡長度的難度篩選,以及基于數(shù)學(xué)學(xué)科分類的多樣性篩選,最終留下了一個涵蓋1000個精心挑選過的問題的數(shù)據(jù)集。
且每個問題都附有答案,以及谷歌Gemini 2.0 Flash Thinking實驗版的模型思考過程。
這就是最終的s1K。
研究人員表示,Test-time Scaling有2種。
第1種,順序Scaling,較晚的計算取決于焦躁的計算(如較長的推理軌跡)。
第2種,并行Scaling,be like計算獨立運行(如多數(shù)投票任務(wù))。
s1團隊專注于順序這部分,原因是團隊“從直覺上”認(rèn)為它可以起到更好的Scaling——因為后面的計算可以以中間結(jié)果為基礎(chǔ),從而允許更深入的推理和迭代細(xì)化。
基于此,s1團隊提出了新的順序Scaling方法,以及對應(yīng)的Benchmark。
研究過程中,團隊提出了一種簡單的解碼時間干預(yù)方法budget forcing,在測試時強制設(shè)定最大和/或最小的思考token數(shù)量。
具體來說,研究者使用了一種很簡單的辦法:
直接添加“end-of-thinking token分隔符”和“Final Answer”,來強制設(shè)定思考token數(shù)量上限,從而讓模型提前結(jié)束思考階段,并促使它提供當(dāng)前思考過程中的最佳答案。
為了強制設(shè)定思考過程的token數(shù)量下限,團隊又禁止模型生成“end-of-thinking token分隔符”,并可以選擇在模型當(dāng)前推理軌跡中添加“wait”這個詞,鼓勵它多想想,反思反思當(dāng)前的思考結(jié)果,引導(dǎo)最佳答案。
以下是budget forcing這個辦法的一個實操示例:

團隊還為budget forcing提供了baseline。
一是條件長度控制方法(Conditional length-control methods),該方法依賴于,在提示中告訴模型它應(yīng)該花費多長時間來生成輸出。
團隊按顆粒度將它們分為Token-conditional控制、步驟條件控制和類條件控制。
- Token-conditional控制:在提示詞中,指定Thinking Tokens的上限;
- 步驟條件控制:指定一個思考步驟的上限。其中每個步驟約100個tokens;
- 類條件控制:編寫兩個通用提示,告訴模型思考短時間或長時間。
二是拒絕抽樣(rejection sampling)。
即在抽樣過程中,若某一生成內(nèi)容符合預(yù)先設(shè)定的計算預(yù)算,就停止計算。
該算法通過其長度來捕捉響應(yīng)的后驗分布。
而s1模型的整個訓(xùn)練過程,只用了不到半個小時——
團隊在論文中表示,他們使用Qwen2.532B-Instruct模型在s1K數(shù)據(jù)集上進行SFT,使用16個英偉達H100,訓(xùn)練耗時26分鐘。
s1研究團隊的Niklas Muennighoff(斯坦福大學(xué)研究員)告訴TechCrunch,訓(xùn)練s1所需的計算資源,在當(dāng)下約花20美元就能租到。
研究新發(fā)現(xiàn):頻繁抑制思考會導(dǎo)致死循環(huán)
訓(xùn)出模型后,團隊選用3個推理基準(zhǔn)測試,把s1-32B和OpenAI o1系列、DeepSeek-R1系列、阿里通義Qwen2.5系列/QWQ、昆侖萬維Sky系列、Gemini 2.0 Flash Thinking實驗版等多個模型進行對比。
3個推理基準(zhǔn)測試如下:
- AIME24:2024年美國數(shù)學(xué)邀請考試中使用的30個問題
- MATH500:不同難度的競賽數(shù)學(xué)問題的基準(zhǔn)
- GPQA Diamond:生物、化學(xué)和物理領(lǐng)域的198個博士級問題
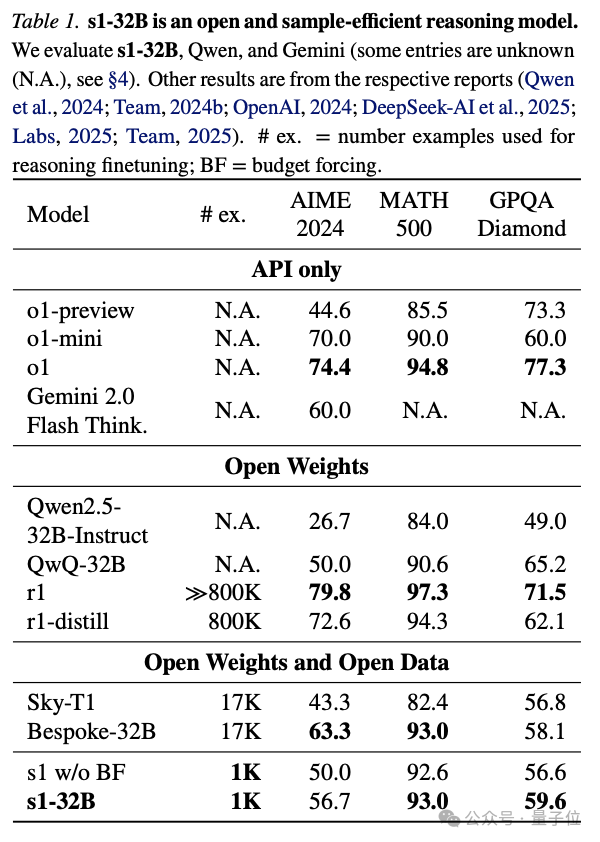
整體來說,采用了budget forcing的s1-32B擴展了更多的test-time compute。
評測數(shù)據(jù)顯示,s1-32B在MATH500上拿到了93.0的成績,超過o1-mini,媲美o1和DeepSeek-R1。
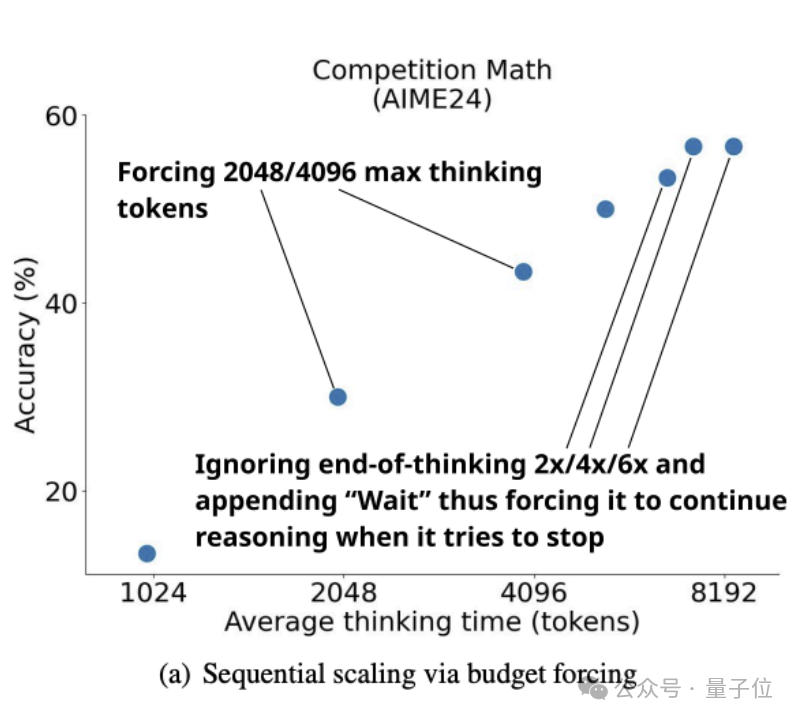
不過,如下圖所示,團隊發(fā)現(xiàn),雖然可以用budget forcing和更多的test-time compute來提高s1在AIME24上的性能,在AIME24上比 o1-preview最高提升27%。
但曲線最終在性能提升6倍后趨于平緩。
由此,團隊在論文中寫道:
過于頻繁地抑制思考結(jié)束標(biāo)記分隔符,會導(dǎo)致模型進入重復(fù)循環(huán),而不是繼續(xù)推理。
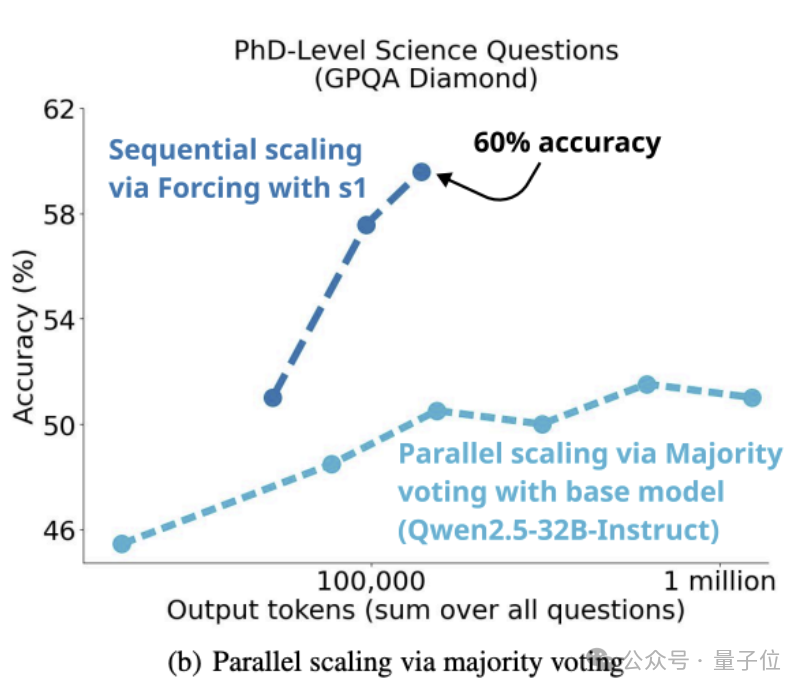
而如下圖所示,在s1K上訓(xùn)練Qwen2.5-32B-Instruct來得到s1-32B,并為它配備了簡單的budget forcing后,它采用了不同的scaling范式。
具體來說,通過多數(shù)投票在基礎(chǔ)模型上對test-time compute進行Scale的方法,訓(xùn)出的模型無法趕上s1-32B的性能。
這就驗證了團隊之前的“直覺”,即順序Scaling比并行Scaling更有效。
此外,團隊提到,s1-32B僅僅使用了1000個樣本訓(xùn)練,在AIME24上的成績就能接近Gemini 2.0 Thinking,是“樣本效率最高的開源數(shù)據(jù)推理模型”。
研究人員還表示,Budget forcing在控制、縮放和性能指標(biāo)上表現(xiàn)最佳。
而其它方法,如Token-conditional控制、步驟條件控制、類條件控制等,均存在各種問題。
One More Thing
s1模型,是在一個1000個精挑細(xì)選的小樣本數(shù)據(jù)集上,通過SFT,讓小模型能力在數(shù)學(xué)等評測集上性能飆升的研究。
但結(jié)合近期刷爆全網(wǎng)的DeepSeek-R1——以1/50成本比肩o1性能——背后的故事,可以窺見模型推理技術(shù)的更多值得挖掘之處。
模型蒸餾技術(shù)加持下,DeepSeek-R1的訓(xùn)練成本震撼硅谷。
現(xiàn)在,AI教母李飛飛等,又一次運用「蒸餾」,花費低到令人咋舌的訓(xùn)練成本,做出了一個能媲美頂尖推理模型的32B推理模型。
一起期待大模型技術(shù)更精彩的2025年吧~
arXiv:
https://arxiv.org/pdf/2501.19393
GitHub:
https://github.com/simplescaling/s1





























