













如何利用 DeepSeek-R1 本地部署強大的推理模型:從 ChatGPT 風格界面到 API 集成
01、概述
隨著開源推理模型如 DeepSeek-R1 的崛起,開發者可以在本地運行強大的 AI,而不再依賴于云服務。這一技術的出現引發了不小的網絡熱議,或許你也在好奇如何利用這一模型在本地搭建自己的 AI 系統。
本指南將帶你了解兩種關鍵的使用場景:
普通用戶:創建一個 ChatGPT 風格的界面
開發者:通過 API 集成模型到應用中
在開始之前,如果你有興趣深入了解 DeepSeek-R1 的背景,以便更好地理解接下來的過程,可以參考我的文章《DeepSeek-R1 理論簡介(適合初學者)》。
02、本地部署必備工具
1. 安裝 Ollama
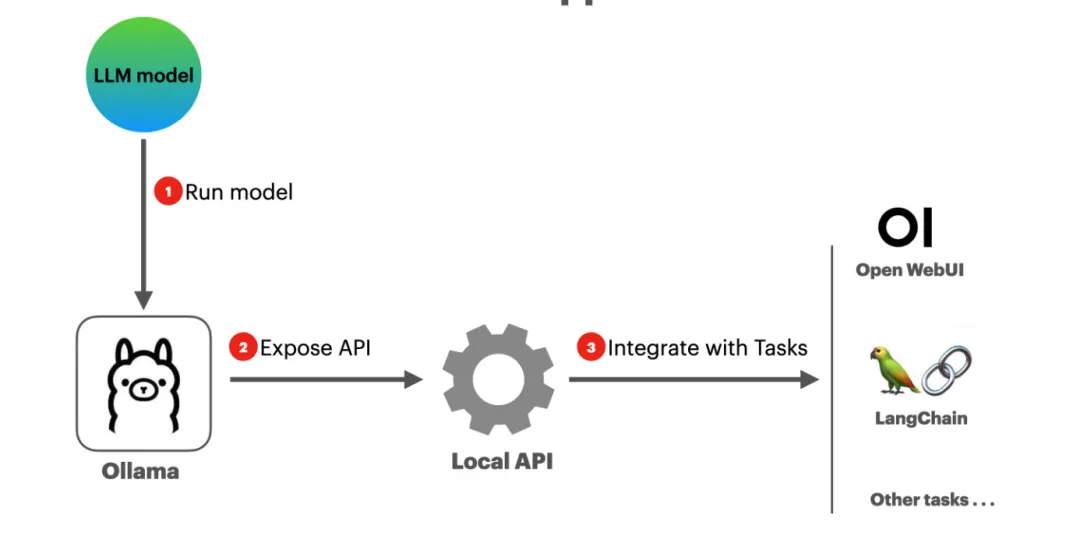
首先,我們需要安裝 Ollama,這是一個可以幫助你在本地下載并托管 DeepSeek-R1 模型的工具。無論你是 macOS M 系列、Windows 還是 Linux 用戶,都可以通過以下方式安裝 Ollama:
macOS 或 Windows 用戶:可以訪問 Ollama 官方網站 下載并安裝適合你系統的版本。
Linux 用戶:使用命令行安裝:
curl -fsSL https://ollama.com/install.sh | sh這會安裝模型運行工具,并自動啟用 GPU 加速(Apple M 系列使用 Metal,NVIDIA 顯卡使用 CUDA)。
簡單來說,Ollama 是一個幫助你下載并本地運行 DeepSeek-R1 模型的工具,同時它也能讓其他應用能夠調用該模型。
2. 下載 DeepSeek-R1 模型
根據你的硬件配置選擇適合的 DeepSeek-R1 版本。你可以在 DeepSeek-R1 模型庫 中查看不同版本的模型。值得注意的是,模型有精簡版和完整版之分,精簡版的模型保留了原版模型的大部分功能,但體積更小,運行速度更快,對硬件的要求也較低。
大部分情況下,較大的模型通常更強大,但對于本地托管而言,我們建議選擇一個適合你 GPU 性能的版本。幸運的是,DeepSeek-R1 提供了一個 compact 版本 DeepSeek-R1-Distill-Qwen-1.5B,它僅使用大約 1GB 的顯存,甚至可以在 8GB 內存的 M1 MacBook Air 上運行。
安裝命令如下:
ollama run deepseek-r1:1.5b # 平衡速度和質量(約 1.1GB VRAM)03、場景 1:ChatGPT 風格的聊天界面
如果你想體驗 DeepSeek-R1 模型,并通過一個 ChatGPT 風格的界面與其互動,可以利用 Open WebUI 來實現。這是一個用戶友好的聊天界面,適用于本地托管的 Ollama 模型。
通過以下 Docker 命令,快速部署 Open WebUI:
docker run -d -p 3000:8080 -v ollama:/root/.ollama -v open-webui:/app/backend/data \\
--add-host=host.docker.internal:host-gateway --name open-webui ghcr.io/open-webui/open-webui:main部署完成后,打開瀏覽器訪問 http://localhost:3000,創建一個賬戶,并從模型下拉菜單中選擇 deepseek-r1:1.5b。
使用本地部署的 LLM 進行聊天具有以下幾個優勢:
易于訪問:你可以隨時試驗不同的開源模型。
離線聊天:無需互聯網連接,你依然可以使用類似 ChatGPT 的服務來提高工作效率。
更高的隱私保護:因為聊天數據完全保存在本地,避免了敏感信息泄露的風險。
04、場景 2:開發者的 API 集成
如果你已經將 DeepSeek-R1 在本地托管,并且是開發者,你可以通過 Ollama 提供的 OpenAI 兼容 API 輕松集成模型到應用中。API 地址為 http://localhost:11434/v1。
使用 OpenAI Python 客戶端進行集成:
from openai import OpenAI
# 配置客戶端,使用 Ollama 本地服務器地址
client = OpenAI(
base_url="http://localhost:11434/v1", # Ollama 服務器地址
api_key="no-api-key-needed", # Ollama 不需要 API 密鑰
)使用 LangChain 集成:
from langchain_ollama import ChatOllama
# 配置 Ollama 客戶端,使用本地服務器地址
llm = ChatOllama(
base_url="http://localhost:11434", # Ollama 服務器地址
model="deepseek-r1:1.5b", # 指定你在 Ollama 本地托管的模型
)更多相關代碼和設置可以參考 GitHub 上的項目:DeepSeek-R1 本地 API 集成指南。
05、總結
通過 Ollama 和 DeepSeek-R1,你現在可以在本地使用 GPU 加速運行強大的 AI,體驗 ChatGPT 風格的聊天界面,并且通過標準的 API 將 AI 能力集成到你的應用中——這一切都在離線狀態下進行,確保了隱私保護。
無論你是普通用戶想要快速體驗 AI 聊天功能,還是開發者希望將強大的語言模型融入自己的應用中,DeepSeek-R1 都是一個非常適合的選擇。
通過本地部署,你不僅能夠享受到更低的延遲和更高的性能,還能避免將敏感數據暴露在云端,極大提升了安全性和效率。
參考:





























