













忘掉 DeepSeek:Qwen 2.5 VL 與 Qwen Max 來了
作者:de
先從 Qwen 2.5 VL 說起。它不僅能看圖識物,還能理解視頻、文本,具備執行電腦操作(agentic)的能力,甚至能做物體檢測等。
Qwen 系列又推出了兩款令人矚目的新模型:Qwen 2.5 VL 和 Qwen 2.5 Max。
如果還停留在“DeepSeek 是最強”那一檔,就可能要重新考慮一下,因為這兩款模型的實力相當驚艷。
什么是 Qwen 2.5 VL?
先從 Qwen 2.5 VL 說起。它不僅能看圖識物,還能理解視頻、文本,具備執行電腦操作(agentic)的能力,甚至能做物體檢測等。
Qwen 2.5 VL 的核心特性
高級視覺理解
- 不只是識別常見物體(鮮花、鳥類等),還能處理復雜視覺元素,如圖表、圖標、排版布局等。
- 能理解圖像中的空間結構和文字內容,分析文檔或圖形信息時更得力。
Agentic 能力
- 可視為一個“視覺代理”,可以進行推理、執行命令、和工具動態交互。
- 能在電腦或手機等數字設備上自動化操作,無需對特定任務做額外微調。
長視頻理解
- 能處理超過一小時的視頻,并分段提取關鍵片段。
- 提供二級精度的事件定位,對總結和信息提取非常有用。
視覺定位
- 能識別圖像中的物體,并輸出精確的邊界框或關鍵點。
- 還能生成穩定的 JSON 結果用于描述對象屬性,方便結構化分析。
結構化輸出
- 可將掃描文件、發票、表單等轉化為可讀的數字數據,方便在金融和商務場景下使用。
- 自動化數據抽取,讓處理文檔更高效并保持高準確度。
強大的圖像識別
- 擁有非常廣泛的識別能力,從地標、動物、植物到流行文化元素都能辨識。
- 可以對多類別圖像進行識別和分類,適合檢索和分類等應用。
增強的文本與文檔解析
- OCR(光學字符識別)能力更強,多語言、多方向、多場景都能處理。
- 引入 QwenVL HTML 格式,能從雜志、論文、網頁中提取復雜的布局結構。
強化視頻處理
- 采用動態幀率訓練及絕對時間編碼,能精準把握時間信息。
- 在長視頻場景下的場景識別、事件提取和摘要能力更上一層樓。
性能優化
- Vision Transformer(ViT)中采用 Window Attention,保持精度同時減少計算量。
- 使用 RMSNorm、SwiGLU 等結構,使得它與 LLM 架構更好對齊。
多規格模型可選
- 提供 3B、7B、72B 三種大小,面向不同的硬件與應用需求。
- 同時在 Hugging Face、ModelScope 開源,基礎版與指令版都有。
接下來是 Qwen 2.5 Max
Qwen2.5 Max 則是另一款大殺器。下面簡單介紹它的核心功能。
Qwen 2.5 Max 的主要特點
大規模 MoE(Mixture-of-Experts)模型
- 采用專家混合架構,實現更高效的擴展性。
- 預訓練超過 20 萬億令牌(tokens),知識覆蓋面極廣。
強化的后期訓練
- 使用 SFT(Supervised Fine-Tuning)進行更好的任務定向調優。
- 通過人類反饋強化學習(RLHF)進一步對齊用戶偏好。
基準表現
- 在 Arena-Hard、LiveBench、LiveCodeBench、GPQA-Diamond 等測試上超越 DeepSeek V3。
- 在 MMLU-Pro(大學水平知識測評)上也保持領先或具備競爭力。
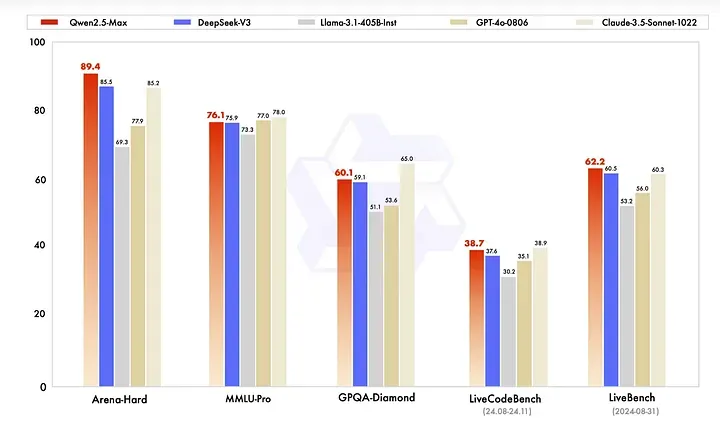
與主流模型對比
- 在對話與編程任務上,可與 GPT-4o、Claude-3.5-Sonnet 等商業模型一較高下。
- 底層模型能力勝過同樣開源的 DeepSeek V3 與 Llama-3.1–405B。
API 與 OpenAI 兼容
- 可以通過阿里云(Alibaba Cloud)訪問,并且兼容 OpenAI-API,使用方便。
- 輕松在 Python 或其他 OpenAI 支持的框架中集成。
總之,看得出來 Qwen 在下一盤大棋!
如何使用 Qwen 2.5 VL 與 Qwen 2.5 Max?
對于想嘗鮮或在項目中集成這兩款新模型,主要途徑大致有:
- 開源平臺:可以到 Hugging Face、ModelScope 等處找到對應倉庫,下載基礎版(Base)或指令版(Instruct)模型。
- 云端服務:阿里云已提供官方 API,并支持與 OpenAI 兼容的方式接入。只要你熟悉 Python 或 OpenAI SDK,就能快速上手。
- 本地部署(硬件允許的話):如果在本地有足夠算力,可以下載合適大小的模型自行部署,用于敏感數據處理或離線場景。
從視覺理解到大規模推理,Qwen 2.5 VL 與 Qwen 2.5 Max 都彰顯了下一個階段的模型實力。對需要極致性能或全能 AI 方案的人來說,確實值得一試。
責任編輯:姜華
來源:
大遷世界





























