













單提示生成「主體一致」圖像,且無(wú)需訓(xùn)練!已斬獲ICLR 2025 Spotlight
現(xiàn)在的AI畫圖工具,比如文圖生成模型,已經(jīng)能根據(jù)文字描述創(chuàng)作出高質(zhì)量的圖像了。
但是,當(dāng)我們需要用模型來(lái)畫故事,并且希望故事中的人物在不同場(chǎng)景下都保持一致時(shí),這些模型就有點(diǎn)犯難了。
目前,為了解決人物不一致的問(wèn)題,通常需要用海量數(shù)據(jù)進(jìn)行額外訓(xùn)練,或者對(duì)模型本身進(jìn)行比較復(fù)雜的修改。這讓這些方法在不同領(lǐng)域和各種 AI 模型上的應(yīng)用都受到限制,不太方便。
其實(shí)語(yǔ)言模型本身就有一種內(nèi)在的「上下文理解」能力,即使只給一個(gè)簡(jiǎn)單的提示,語(yǔ)言模型也能根據(jù)上下文來(lái)理解人物的身份特征。
受到這個(gè)發(fā)現(xiàn)的啟發(fā),南開(kāi)大學(xué)、中科院等機(jī)構(gòu)的研究人員提出了一種全新的、而且無(wú)需任何額外訓(xùn)練的方法,來(lái)實(shí)現(xiàn)人物形象一致的文圖生成,方法名叫「One-Prompt-One-Story」 (1Prompt1Story),也就是「一個(gè)提示講故事」。

文章鏈接:https://arxiv.org/abs/2501.13554
GitHub代碼:https://github.com/byliutao/1Prompt1Story
項(xiàng)目主頁(yè):https://byliutao.github.io/1Prompt1Story.github.io/
1Prompt1Story的核心做法是,把所有場(chǎng)景的文字描述合并成一個(gè)長(zhǎng)長(zhǎng)的輸入提示,直接給AI畫圖模型。
這樣,模型就能在最開(kāi)始就記住人物的身份特征,保證初步的一致性。接下來(lái),他們還使用了兩項(xiàng)新技術(shù)來(lái)優(yōu)化生成過(guò)程:「奇異值重加權(quán)」和「身份保持交叉注意力」。這兩項(xiàng)技術(shù)能夠確保生成的每一幀圖像都更符合對(duì)應(yīng)的文字描述,同時(shí)人物形象還不會(huì)跑偏。
在實(shí)驗(yàn)部分,研究人員將他們的方法與現(xiàn)有的各種保持一致性的文圖生成方法進(jìn)行了對(duì)比。結(jié)果表明,無(wú)論是從數(shù)據(jù)指標(biāo)還是實(shí)際生成效果來(lái)看,他們的新方法都更有效。

1Prompt1Story生成人物一致的故事的示例圖
研究背景
目前,實(shí)現(xiàn)圖像生成中人物身份一致性的方法,主要可以分為兩類:需要訓(xùn)練的方法,比如 Texture-Inversion 和 IP-Adapter,以及無(wú)需訓(xùn)練的方法,像 ConsiStory 和 StoryDiffusion。但現(xiàn)有的這些方法,多少都存在一些問(wèn)題。
需要訓(xùn)練的方法 (Training-based methods)
耗時(shí)耗力:通常需要在龐大的數(shù)據(jù)集上進(jìn)行長(zhǎng)時(shí)間的訓(xùn)練,這需要大量的計(jì)算資源和時(shí)間成本。
容易引起語(yǔ)言漂移 (Language Drift):通過(guò)微調(diào)模型或?qū)W習(xí)新的映射編碼器來(lái)保持一致性,可能會(huì)導(dǎo)致模型對(duì)原始語(yǔ)言指令的理解發(fā)生偏差,產(chǎn)生意外或不理想的結(jié)果。
無(wú)需訓(xùn)練的方法 (Training-free methods)
資源消耗或設(shè)計(jì)復(fù)雜:為了加強(qiáng)模型的一致性生成能力,這些方法通常需要大量的內(nèi)存資源,或者需要設(shè)計(jì)復(fù)雜的模塊結(jié)構(gòu),這增加了實(shí)現(xiàn)的難度和成本。
忽略了長(zhǎng)提示的內(nèi)在特性:現(xiàn)有的一些無(wú)需訓(xùn)練的方法,雖然在生成一致性圖像方面取得了一定的成果,但它們 沒(méi)有充分利用語(yǔ)言模型固有的上下文一致性。
也就是說(shuō),它們可能沒(méi)有意識(shí)到長(zhǎng)文本提示本身已經(jīng)蘊(yùn)含了保持身份一致的信息,從而導(dǎo)致方法可能變得更加復(fù)雜或資源密集,而沒(méi)有充分利用語(yǔ)言模型的自身能力。
更重要的是,就像下圖上半部分展示的,現(xiàn)有的方法普遍存在背景混淆的問(wèn)題。
比如第一行和第二行生成的圖像,背景就非常相似,但明明對(duì)應(yīng)的文字描述場(chǎng)景是不一樣的。如果用基礎(chǔ)模型,像SDXL,就不會(huì)出現(xiàn)這種背景混淆,這說(shuō)明現(xiàn)有的方法或多或少破壞了模型原本優(yōu)秀的文本-圖像對(duì)齊能力。
而該方法就很好地解決了這個(gè)問(wèn)題,看下圖最后一行,該方法生成的圖像,不同場(chǎng)景之間的背景區(qū)分就很清晰,完美地展現(xiàn)了各種文字描述的場(chǎng)景,背景不再「千篇一律」!

方法
總的來(lái)說(shuō),1Prompt1Story的核心思想可以概括為「一個(gè)提示,講一個(gè)故事」,主要通過(guò)以下幾個(gè)步驟來(lái)實(shí)現(xiàn)人物身份一致性的圖像生成:
提示整合 (PCon):故事的「劇本」
把人物身份描述 (P0) 和多個(gè)場(chǎng)景描述 (P1, P2, ... PN) 像寫劇本一樣串聯(lián)成一個(gè)超長(zhǎng)提示 (CC)。
作用:將整個(gè)故事的文本信息整合到一個(gè)提示中,方便模型統(tǒng)一理解。
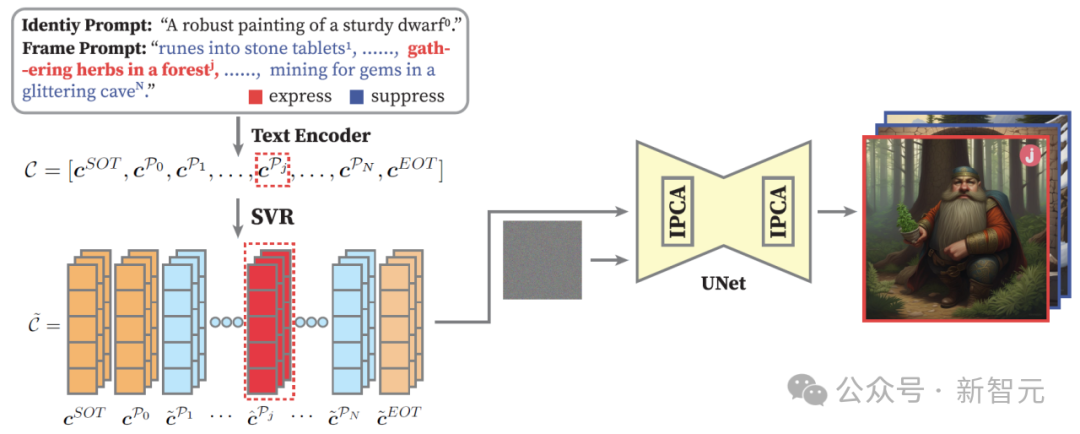
奇異值重加權(quán) (SVR): 突出重點(diǎn),抑制干擾
解決長(zhǎng)提示中場(chǎng)景描述互相干擾問(wèn)題,讓模型「看清」當(dāng)前要畫的場(chǎng)景。
SVR+ (增強(qiáng)當(dāng)前幀): 像聚光燈一樣,放大當(dāng)前場(chǎng)景描述 (Pj) 的語(yǔ)義信息,讓模型更關(guān)注它。(簡(jiǎn)化公式理解:放大重要特征)
SVR- (抑制其他幀): 同時(shí),弱化其他場(chǎng)景描述 (Pk, k≠j) 的語(yǔ)義信息,減少干擾。(簡(jiǎn)化公式理解:減弱不重要特征)
技術(shù)核心: 利用 奇異值分解 (SVD) 來(lái)分析和調(diào)整詞向量的「重要性」,達(dá)到增強(qiáng)和抑制語(yǔ)義的效果。
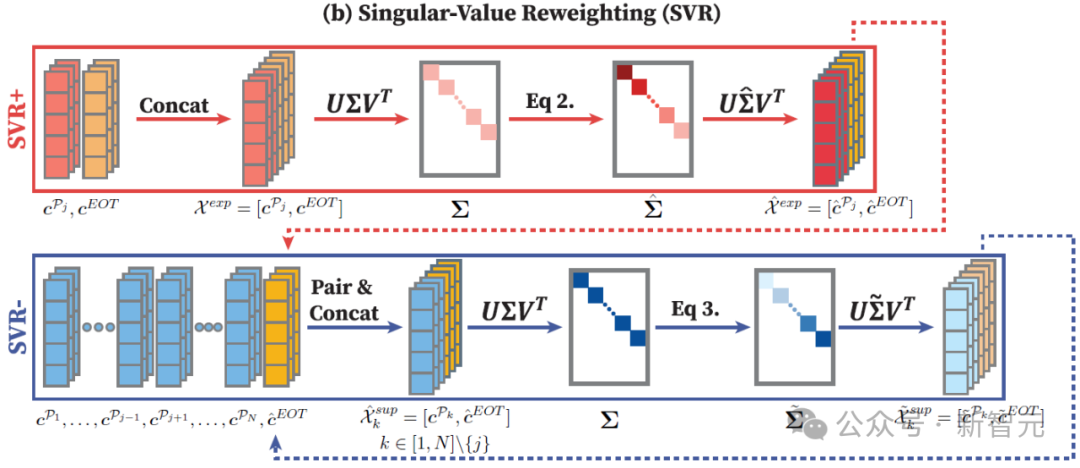
身份保持交叉注意力 (IPCA): 強(qiáng)化身份,排除干擾
目的: 進(jìn)一步強(qiáng)化人物身份的一致性,排除場(chǎng)景描述對(duì)人物身份的干擾。
核心: 在圖像生成過(guò)程中,強(qiáng)制模型更關(guān)注人物身份描述 (P0) 的特征,忽略或弱化場(chǎng)景描述對(duì)人物身份的影響。
具體操作: 在交叉注意力計(jì)算時(shí),修改Key(K)和Value(V)矩陣,只保留與身份提示相關(guān)的特征,并進(jìn)行拼接, 確保每一幀圖像都牢牢抓住人物的身份特征。(簡(jiǎn)化理解:專注身份,弱化場(chǎng)景對(duì)身份的影響)
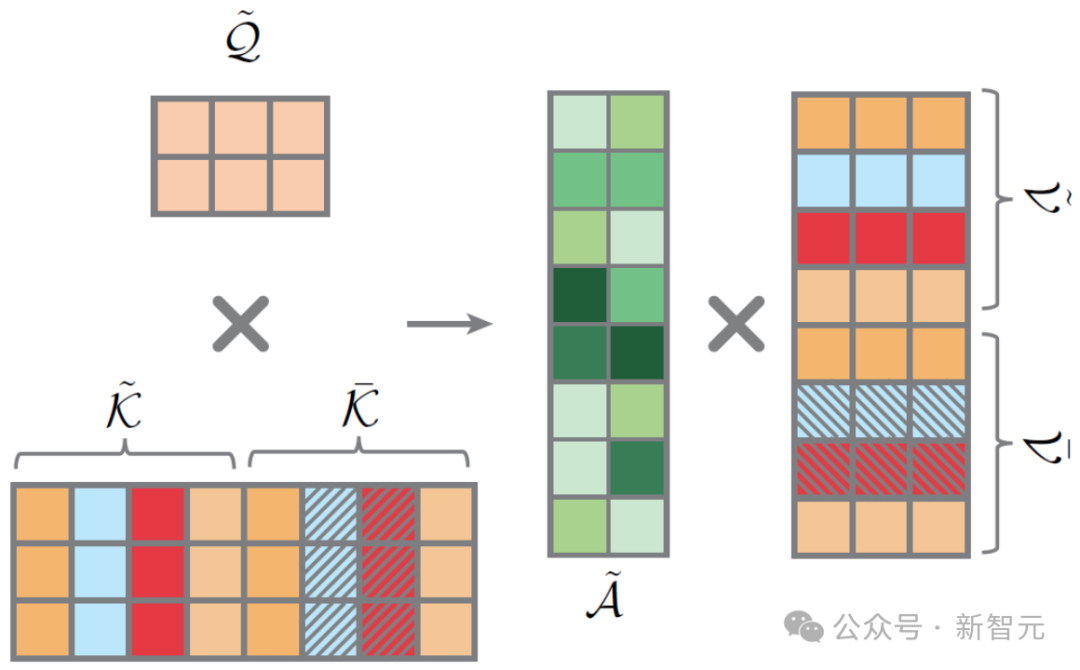
總結(jié)1Prompt1Story的流程
Prompt Consolidation (PCon): 將身份提示和所有幀提示串聯(lián)成一個(gè)長(zhǎng)提示。
Singular-Value Reweighting (SVR): SVR+: 增強(qiáng)當(dāng)前幀提示的語(yǔ)義信息、SVR-: 減弱其他幀提示的語(yǔ)義信息。
Identity-Preserving Cross-Attention (IPCA): 在交叉注意力層,強(qiáng)化身份提示特征,抑制幀提示特征。
通過(guò)這三個(gè)步驟的協(xié)同作用,1Prompt1Story能夠有效地生成人物身份一致,且圖像內(nèi)容準(zhǔn)確對(duì)應(yīng)每個(gè)場(chǎng)景描述的故事圖像。
實(shí)驗(yàn)

正如圖中所示的定性比較結(jié)果,1Prompt1Story方法在幾個(gè)關(guān)鍵表現(xiàn)上都非常出色。這包括能夠準(zhǔn)確地保留人物身份、精確地描繪圖像幀的內(nèi)容,以及生成多樣化的物體姿態(tài)。反觀其他方法,在這些方面就顯得不足了。
具體來(lái)說(shuō),在左側(cè)的例子中,PhotoMaker、ConsiStory和StoryDiffusion生成的「龍」這個(gè)主體,都出現(xiàn)了身份不一致的問(wèn)題,龍看起來(lái)不像同一個(gè)龍。
另外,IP-Adapter則傾向于生成姿勢(shì)和背景都非常相似的圖像,并且常常忽略了幀提示中關(guān)于細(xì)節(jié)的描述。ConsiStory在生成連貫的圖像序列時(shí),也表現(xiàn)出背景重復(fù)的問(wèn)題。
除了定性比較,研究人員還進(jìn)行了定量分析。在衡量文本與圖像對(duì)齊程度的CLIP-T得分上,1Prompt1Story方法已經(jīng)非常接近原始的SDXL模型。
在身份一致性方面(使用DreamSim指標(biāo)評(píng)估),也僅次于IP-Adapter。
然而,需要指出的是,IP-Adapter之所以在身份相似性上表現(xiàn)很高,很大程度上是因?yàn)樗鼉A向于生成姿勢(shì)和布局非常相似的人物圖像,這實(shí)際上限制了多樣性。
正如下方的圖表所展示的,1Prompt1Story方法位于圖表的右上角,這表明它在文本-圖像對(duì)齊和身份一致性之間取得了良好的平衡。

更多結(jié)果
多主體故事生成

與不同的基礎(chǔ)模型結(jié)合

長(zhǎng)故事生成






























