多模態大模型對齊新范式,10個評估維度全面提升,快手&中科院&南大打破瓶頸
盡管多模態大語言模型(MLLMs)取得了顯著的進展,但現有的先進模型仍然缺乏與人類偏好的充分對齊。這一差距的存在主要是因為現有的對齊研究多集中于某些特定領域(例如減少幻覺問題),是否與人類偏好對齊可以全面提升MLLM的各種能力仍是一個未知數。
快手,中科院,南大合作從三個層面入手推動MLLM alignment的發展,包括數據集,獎勵模型以及訓練算法,最終的alignment pipeline使得不同基礎模型在10個評估維度,27個benchmark上都取得了一致的性能增益,比較突出的是,基于本文提出的數據集和對齊算法對LLaVA-ov-7B模型進行微調后, conversational能力平均提升了19.5%,安全性平均提升了60%。

偏好數據,訓練算法,模型以及評估pipeline均已全面開源。
該方法在twitter上也引起了熱議,被評為多模態alignment的game-changers。

主要貢獻:
- 新數據集:本文引入了一個包含120k精細標注的偏好比較對的數據集,包含三個維度的打分,排序,文本描述的具體原因以及平局等標注,所有標注由人類專家完成,一共50名標注人員,8名專家,耗時兩個月。與現有資源相比,這一數據集在規模、樣本多樣性、標注粒度和質量等方面都有顯著提升。
- 創新的獎勵模型:提出了基于批評的獎勵模型(Critique-Based Reward Model),該模型首先對模型輸出進行批評,然后再進行評分。這一方法相比傳統的標量獎勵機制,提供了更好的可解釋性和更有信息量的反饋,基于該方法的模型只需要7B size,在reward model benchmark就明顯優于現有公開的72B-size的MLLM。
- 動態獎勵縮放:提出了動態獎勵縮放(Dynamic Reward Scaling)方法,通過根據獎勵信號調整每個樣本的損失權重,優化了高質量比較對的使用,進一步提高了數據的使用效率。
- 全面評估:本文在10個維度和27個基準上對提出的方案進行了嚴格評估,同時構造了一個reward model的benchmark以及safety相關的benchmark來彌補現有benchmark的不足,結果顯示,在各個方面均取得了顯著且一致的性能提升。
MM-RLHF人類偏好數據
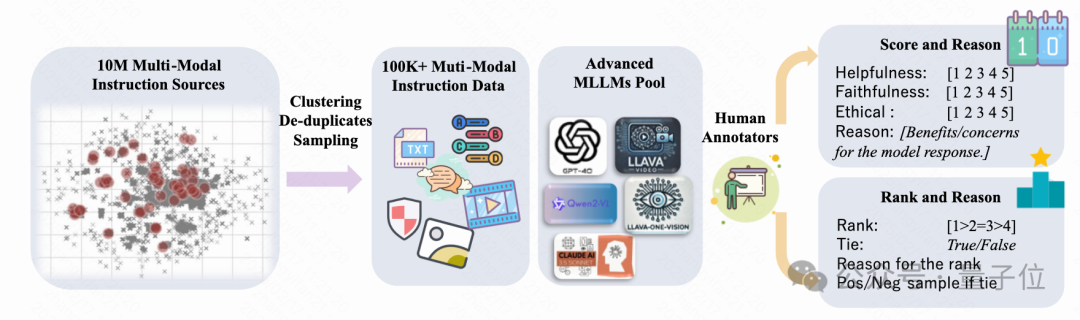
數據來源: 圖像數據來源包括 LLaVA-OV、VLfeedback、LLaVA-RLHF、lrv-instruction 和 Unimm-Chat 等,總共10M,視頻數據來源主要是SharedGPT-4-video,安全性相關的數據來源主要包括 VLGuard 和自構造內容。
數據過濾與模型響應生成, 通過預定義的多選題,長文本等類別均勻采樣,確保少數類也有足夠的樣本。同時采用了knn聚類并采樣的策略,保證數據的diversity。響應生成使用到了Qwen2-VL-72B、LLaVA-OV-72B、GPT-4o 和 Claude 3.5-sonnet等最先進的MLLM。
數據標注: 主要包含三個維度,有用性,真實性,倫理性,同時標注人員需要提供打分的依據,最終排名以及排名的依據,標注粒度細,通過專家定期進行質量檢查和互動評審保證標注質量。
MM-RLHF獎勵模型
標準獎勵模型通常通過預訓練的LLM,并用線性獎勵頭替換原有頭部,以輸出一個標量獎勵值。然而,這些模型難以充分利用人類注釋中的豐富信息,也不具備足夠的透明性。
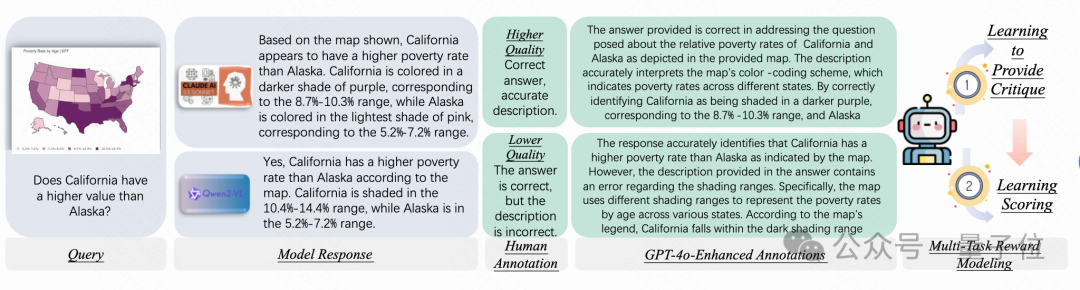
為了解決標準獎勵模型的局限性,本文提出了一種基于批評的訓練框架。在這個框架中,模型首先生成批評(對響應的分析和評估),然后基于批評來打分。批評生成部分與打分部分共同作用,確保了更細致的評價。
增強注釋以提高批評質量:由于人工注釋往往簡潔且精煉,直接使用它們作為訓練目標效果有限。因此,本文通過GPT-4o增強人工注釋,使其更為詳細和流暢,從而提高批評的質量。
在訓練過程中,批評的生成與獎勵頭的訓練同時進行,在訓練獎勵頭時采取了teacher-forcing的策略,即采用了ground truth的批評作為輸入,默認損失權重都為1。測試階段先生成批評,然后基于批評得出最終得分。
性能評估

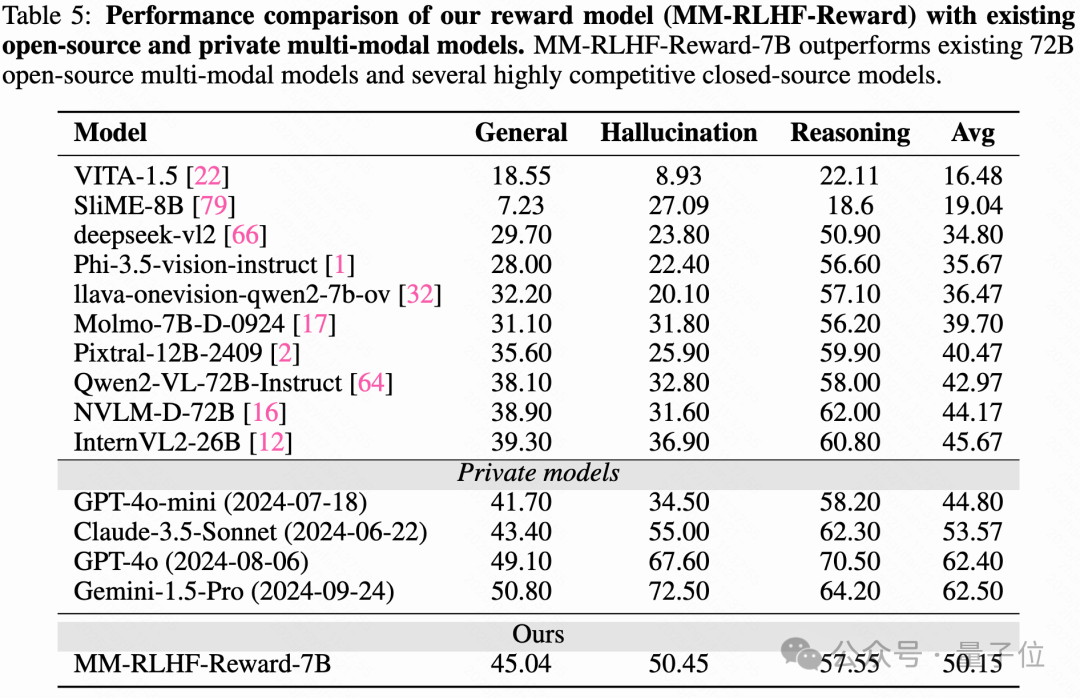
該模型框架簡單,且在多個基準測試中的表現與GPT-4o相媲美,甚至超越了許多開源模型,表現出色,尤其在自定義基準測試中,其表現遠超GPT-4o,這驗證了其作為訓練算法獎勵信號的有效性。
表4中也展示了,當獎勵頭直接使用偏好數據集進行訓練時,模型的ACC+穩定在50%左右。然而,當引入人工注釋作為學習目標時,ACC+穩定提升了5%。進一步通過GPT-4o擴展人工注釋,生成更加詳細和流暢的批評,最終提高了ACC+達17%。當評估時直接使用人工批評時,ACC和ACC+均接近90%,表明評估質量對獎勵模型效果的至關重要性。
MM-DPO:有效利用高質量偏好數據

要有效利用MM-RLHF中的高質量數據,有以下的實驗發現和技巧:
MM-DPO不再僅僅關注“最難的比較對”(即排名差異最大的一對),而是將一個查詢下所有可能的響應對都納入訓練。具體來說,對于一個查詢 ,如果有多個響應,每一對具有不同排名的響應都被視為一個有效的比較對。這種全面的處理方式可以捕捉更細粒度的排序信息,讓模型從更廣泛的偏好數據中學習。然而,這種策略也帶來了新的挑戰:當響應對的排名差異較小時(例如排名 3 和排名 4 的比較),其獎勵差距(reward margin)往往較小,而排名差異較大的響應對(例如排名 1 和排名 4 的比較)包含的信息質量更高。如果對所有樣本對一視同仁,會導致高置信度的信息被低效利用。
為了解決這個問題,MM-DPO 引入了動態獎勵縮放(Dynamic Reward Scaling)機制,根據獎勵差距動態調整更新強度,優先利用高置信度的樣本對。
具體而言,獎勵模型可以自然地為樣本對提供獎勵差距(reward margin),這為動態控制樣本的更新權重提供了一個直接的信號。
本文采用MM-RLHF-Reward-7B模型來計算獎勵差距 其中 和
DPO中,動態縮放因子
其中: 是初始默認縮放因子; 是一個參數,用于平衡動態部分的貢獻; 是一個可調超參數,控制 隨著的變化速度。
接下來只需要將DPO算法中的部分替換為動態的即可。
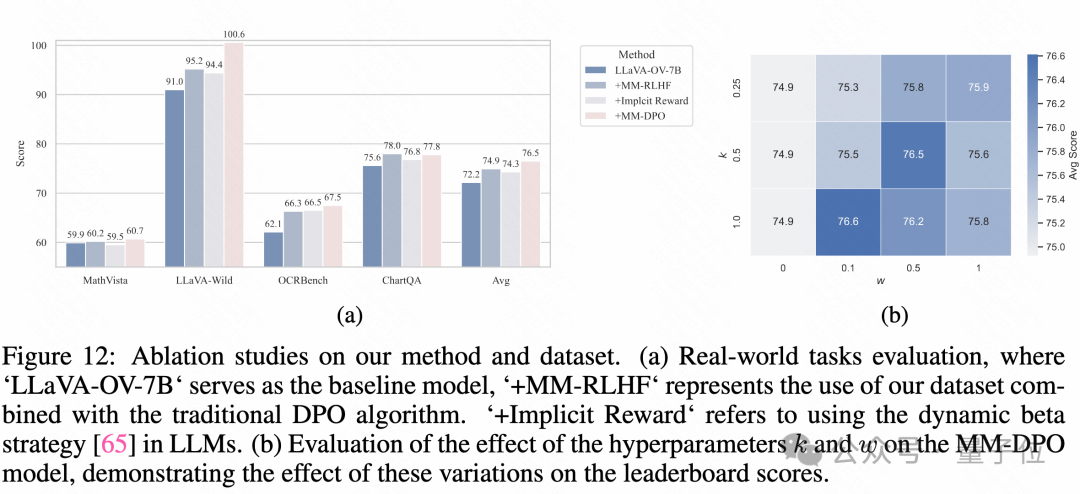
MM-DPO在各類benchmark上都表現出了不錯的性能增益,而且其對于超參數并不是非常敏感,大多數情況下都能使得高質量pair的利用效率得到明顯提升。
27個評估標準,10種評估維度的綜合評估
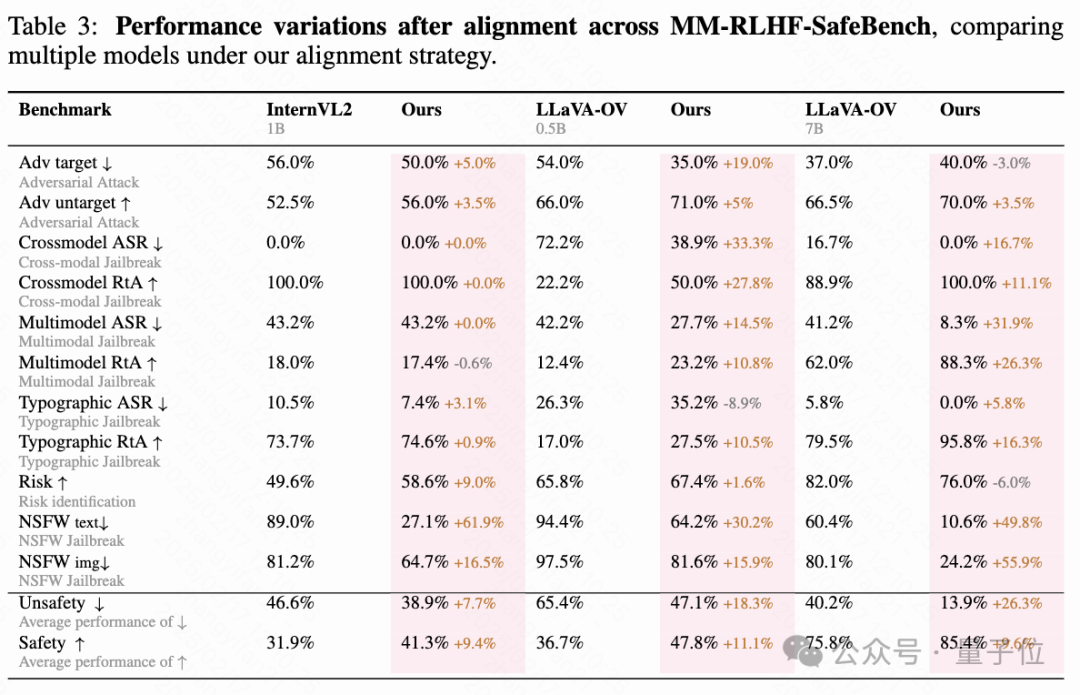
主要領域包括圖表與文檔理解、OCR、幻覺檢測、數學推理、通用知識、多模態對話、高分辨率與真實世界應用、視頻理解、多圖像處理以及多模態安全性。其中,多模態安全性基準 MM-RLHF-SafeBench 是自構建的,涵蓋對抗攻擊、越獄攻擊、隱私保護和有害內容生成等場景,重點評估模型的安全性與魯棒性。這些數據集為模型的多方面性能提供了詳盡的測試環境。
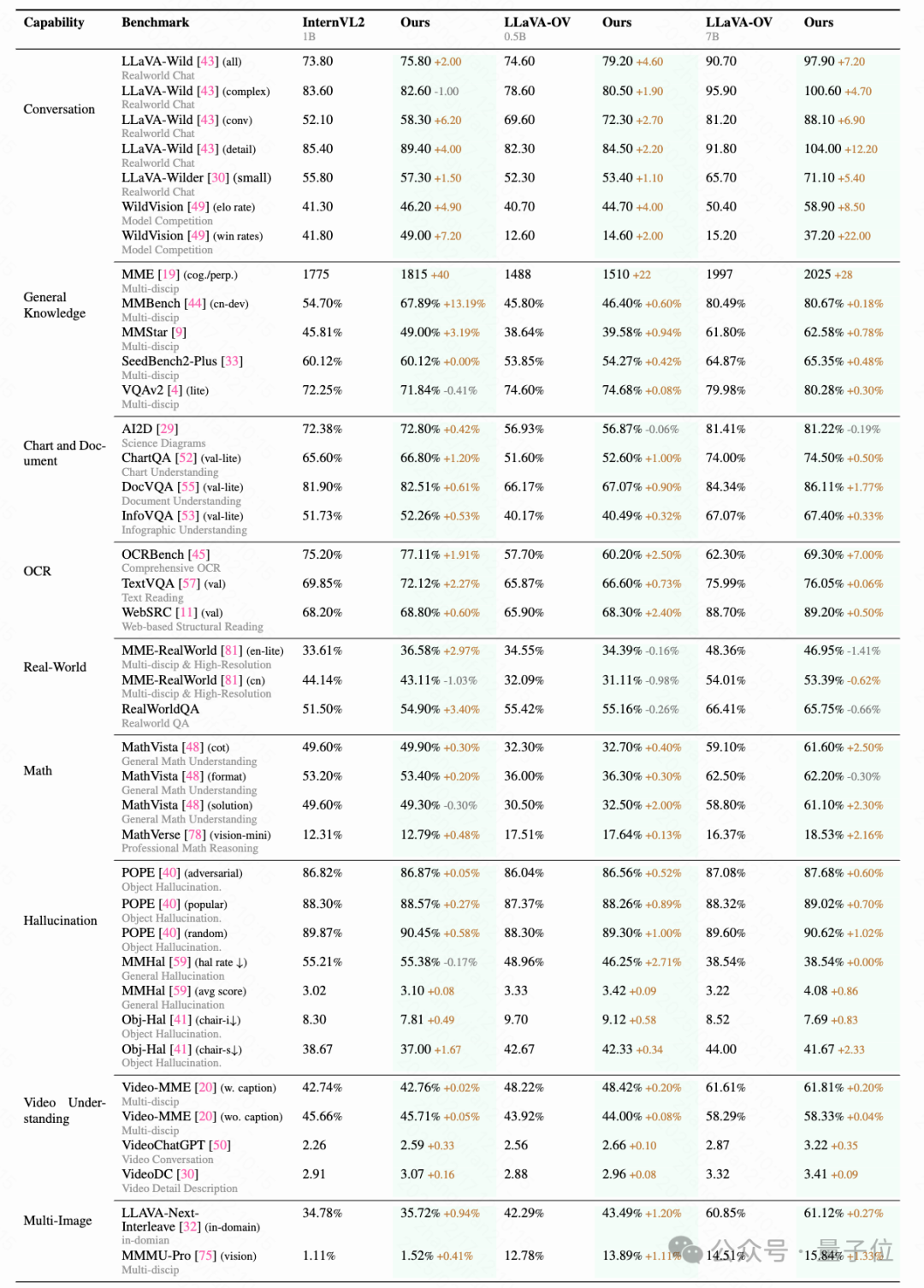
上面兩圖展示了使用本文提出的數據集和對齊算法,LLaVA-OV-7B、LLaVA-OV-0.5B和InternVL-1B在不同維度上的對齊表現,其中每個評估維度的得分在相應的基準上進行了平均。
會話能力和安全性的顯著提升:實驗結果表明,通過對齊過程,這兩個方面的表現得到了顯著改進,無需調整超參數。在會話基準中,平均提高超過10%,而不安全行為減少了至少50%。此外,在WildsVision任務中,勝率至少提高了50%。
在幻覺、數學推理、多圖像和視頻理解方面的廣泛提升:對齊后的模型在這些領域表現出顯著的提升。有趣的是,盡管數據集中缺乏專門的多圖像數據,模型在多圖像任務中的表現依然顯著提升。這表明數據集的多樣性有助于模型在多個維度上進行更好的泛化。
模型對數據和超參數的偏好差異:不同模型在對齊過程中表現出不同的性能趨勢,并且在不同基準上對超參數設置的偏好也各不相同。例如,在對InternVL-1B的訓練中,發現排除SFT損失函數反而帶來了更好的結果。此外,雖然InternVL-1B在常識知識任務中表現出顯著改進,但在OCR任務中的相對提升不如LLaVA-OV系列。這些差異主要源自模型預訓練數據集和策略的不同,因此需要根據具體模型對超參數進行定制化調整以獲得最佳對齊效果。
小規模的MLLMs很難自我提升
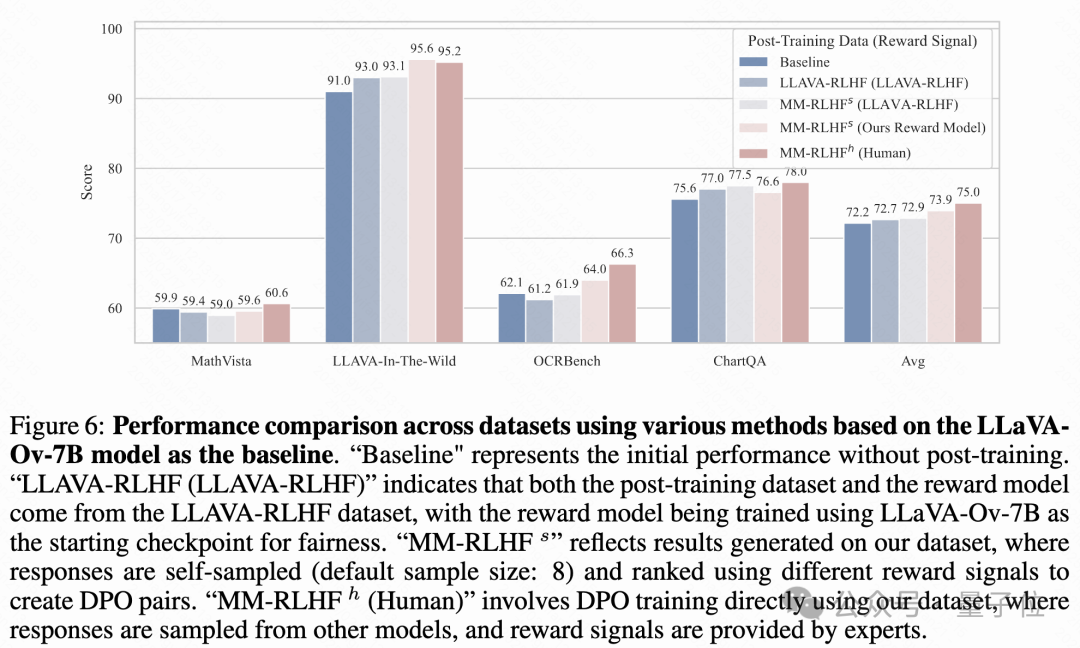
盡管近年來有研究探索了MLLM的自我提升概念,但這些努力主要集中在特定領域,比如對話系統。在這一部分,團隊提出了與LLM領域不同的觀點,認為小規模的MLLM(參數少于7B)目前在通過自我提升實現全面性能提升方面面臨重大挑戰。實驗結果,如上所示,可能有兩個主要原因:
模型容量的限制: 對于涉及長文本或對話數據的任務,采樣多個響應通常會生成至少一個相對較好的答案,從而進行DPO有可能導致性能明顯提高。然而,對于更具挑戰性的任務,如多項選擇題或科學推理任務,小模型即使經過大量采樣,也難以生成正確答案。在實驗中,當最大采樣數量達到八時,觀察到在某些具有挑戰性的多項選擇題中,模型生成了相同的錯誤答案,或者在所有樣本中一致地產生錯誤輸出。
獎勵信號質量的局限性: 目前大多數現有的多模態獎勵模型是在有限多樣性的訓練數據集上訓練的,如VLFeedback和LLaVA-RLHF。這些數據集主要關注自然圖像、人類對話或相關場景,容易引發過擬合問題。當偏好數據集包含更廣泛的領域(如數學推理、圖表理解或其他專業領域)時,在現有數據集上訓練的獎勵模型無法提供有效的獎勵信號。因此,識別和選擇更好的樣本變得困難。
這兩個局限性使得目前的MLLMs很難在多樣化的數據集上生成響應、使用獎勵模型對其進行注釋并通過自我提升循環進行迭代改進,盡管在LLM對齊中取得了類似的進展。實驗確認,更好的獎勵模型可以帶來邊際改進,但這些結果仍遠不如使用高質量人工注釋對比樣本進行訓練的效果。
未來可能的研究方向
本研究提出了MM-RLHF,一個高質量、細粒度的數據集,專門用于推動多模態大語言模型(MLLMs)的對齊工作。與以往專注于特定任務的研究不同,提出的數據集和對齊方法旨在全面提升多個維度的性能。即使在獎勵建模和優化算法方面僅進行了初步改進,在幾乎所有評估基準上都觀察到了顯著且持續的提升,強調了綜合性對齊策略的潛力。
展望未來,可以看到進一步挖掘本數據集價值的巨大機會。數據集的豐富注釋粒度,如每個維度的分數和排名理由,在當前的對齊算法中仍未得到充分利用。未來的工作將重點關注利用這些粒度信息與先進的優化技術,結合高分辨率數據來解決特定基準的局限性,并使用半自動化策略高效地擴展數據集。
團隊相信,這些努力不僅將推動MLLM對齊到新的高度,還將為更廣泛、更具普適性的多模態學習框架奠定基礎。