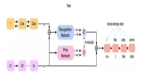
模態編碼器 | 超強開源CLIP模型OpenCLIP

來自LAION、UC伯克利、HuggingFace等的工作,這篇工作的研究動機也很簡單,CLIP 模型在多模態領域展現出了巨大潛力,但原始 CLIP 模型未完全開源,限制了其更廣泛的應用和深入研究。OpenCLIP 旨在通過開源的方式,讓更多開發者能夠無門檻地利用這一先進模型,推動多模態技術在各個領域的應用和發展。

模型架構和原始CLIP無異,下面簡單介紹這篇工作中的一些研究規律和實驗結果。
01、方法介紹
這篇工作最大的貢獻是CLIP中擴展規律研究:通過訓練包含數十億圖像文本對的數據集上的CLIP模型,識別出多個下游任務(如零樣本分類、檢索、線性探測和端到端微調)中的冪律擴展規律。

- 冪律關系:在兩個任務中,模型性能隨計算量的增加都遵循冪律關系。這意味著性能的提升并不是線性的,而是隨著計算量的增加而逐漸減緩。
- 數據量的影響:增加數據量對性能提升有顯著影響。特別是在數據量較小的情況下,增加數據量可以顯著提高性能。
- 模型規模的影響:更大的模型通常能夠從更多的數據中受益,表現出更好的性能。然而,當數據量達到一定規模后,模型規模的增加對性能提升的效果會逐漸減弱。
- 任務差異:在零樣本分類任務中,OpenAI的CLIP模型表現更好;而在零樣本檢索任務中,OpenCLIP模型表現更優。這表明不同的任務可能對模型和數據有不同的需求。
02、模型訓練
- 模型規模:選擇了幾種不同規模的CLIP架構,包括ViT-B/32、ViT-B/16、ViT-L/14、ViT-H/14和ViT-g/14作為視覺編碼器。
- 數據規模:使用了LAION-80M(LAION-400M的子集)、LAION-400M和LAION-2B三個不同的數據集。
- 訓練樣本數量:訓練過程中使用的樣本數量分別為30億、130億和340億。
03、實驗結果
零樣本遷移和魯棒性
模型規模的影響:隨著模型規模的增加,零樣本分類性能持續提升。下圖顯示了不同模型規模下的零樣本分類準確率,可以看到,模型規模越大,準確率越高。
隨著模型規模和數據量的增加,模型在這些魯棒性基準數據集上的性能也有所提升,尤其是在復雜的噪聲和擾動條件下。

- 數據量的影響:增加訓練數據量也能顯著提高零樣本分類性能。表16展示了不同數據量下的VTAB零樣本分類結果,可以看出,使用更大的數據集(如LAION-2B)可以顯著提升模型在多個任務上的表現。
圖像檢索
模型規模的影響:隨著模型規模的增加,圖像檢索性能持續提升。下圖顯示了不同模型規模下的圖像檢索性能,可以看到,模型規模越大,檢索效果越好。

數據量的影響:增加訓練數據量也能顯著提高圖像檢索性能。下表展示了不同數據量下的MS-COCO和Flickr30K圖像檢索結果,可以看出,使用更大的數據集(如LAION-2B)可以顯著提升模型的檢索性能。



linear probing
模型規模的影響:隨著模型規模的增加,線性探測的性能持續提升。圖2和圖3展示了不同模型規模下的線性探測結果,可以看到,模型規模越大,線性探測的準確率越高。

- 數據量的影響:增加訓練數據量也能顯著提高線性探測性能。表5展示了不同數據量下的線性探測結果,可以看出,使用更大的數據集(如LAION-2B)可以顯著提升模型的線性探測性能。

微調
使用預訓練的CLIP模型作為初始化,然后在ImageNet數據集上進行端到端微調
模型規模的影響:隨著模型規模的增加,端到端微調的性能持續提升。下圖展示了不同模型規模下的端到端微調結果,可以看到,模型規模越大,微調后的準確率越高。

數據量的影響:增加訓練數據量也能顯著提高端到端微調性能。使用更大的數據集(如LAION-2B)可以顯著提升模型的微調性能。
04、總結
作為 CLIP 模型的開源實現,在更大的數據集上進行了訓練,具有更多的模型參數,并且提供了更多的模型架構選擇,總結出對比圖像語言模型的縮放定律,為多模態領域的研究和開發提供了重要資源。其基于 Transformer 架構和對比學習方法,讓模型能夠有效學習圖像與文本之間的關聯,推動了多模態技術的發展。