出品 | 51CTO技術棧(微信號:blog51cto)
26日凌晨,OpenAI推出了GPT4o圖像生成,可以說解決了此前Midjourney等擴散模型很難解決的問題,業內為之大為贊嘆。

這是用手機拍攝的玻璃白板的廣角圖像,拍攝地點是一間俯瞰海灣大橋的房間。視野中可以看到一位女士正在寫字,她身穿一件印有大型 OpenAI 標志的 T 恤。筆跡看起來很自然,但有點凌亂,我們可以看到攝影師的倒影。
現在,用戶創建和自定義圖像就像使用 GPT?4o 聊天一樣簡單 - 只需描述需求,包括任何細節,例如縱橫比、使用十六進制代碼的精確顏色或透明背景。
 攝影師的自拍照,她轉身和他擊掌
攝影師的自拍照,她轉身和他擊掌
不過,OpenAI表示,由于此模型可以創建更詳細的圖片,因此圖像渲染時間更長,通常長達一分鐘。
有用的圖像生成
當今的生成模型可以呈現超現實、令人驚嘆的場景,但卻無法處理人們用來分享和創建信息的主要圖像。從徽標到圖表,圖像在添加指代共同語言和經驗的符號后,可以傳達精確的含義。
GPT?4o 圖像生成擅長準確渲染文本、精確遵循提示以及利用 4o 固有的知識庫和聊天上下文(包括轉換上傳的圖像或將其用作視覺靈感)。這些功能讓您可以更輕松地創建您設想的圖像,幫助您通過視覺效果更有效地進行交流,并將圖像生成推進為一種精確而強大的實用工具。
增強功能:一圖勝千言生成準確的文字,可代碼編輯,強大的情景感知
據OpenAI官網介紹,根據在線圖像和文本的聯合分布訓練模型,不僅學習圖像與語言之間的關系,還學習圖像與語言之間的關系。結合積極的后期訓練,生成的模型具有令人驚訝的視覺流暢性,能夠生成有用、一致且具有情境感知能力的圖像。
文本渲染
一張圖片勝過千言萬語,但有時在正確的位置生成幾個文字可以提升圖像的含義。4o 將精確的符號與圖像融合的能力將圖像生成轉變為視覺交流的工具。
多輪生成
由于圖像生成現在是 GPT-4o 的原生功能,您可以通過自然對話來優化圖像。GPT-4o 可以在聊天環境中基于圖像和文本進行構建,從而確保始終保持一致性。例如,如果您正在設計視頻游戲角色,那么在您進行優化和實驗的過程中,該角色的外觀在多次迭代中保持一致。
 原始圖像
原始圖像
 圖給這只貓一頂偵探帽和一副單片眼鏡
圖給這只貓一頂偵探帽和一副單片眼鏡

將其變成使用 4k 游戲引擎制作的 3A 視頻游戲,并添加一些用戶界面作為神秘 RPG 的覆蓋,我們可以在頂部看到健康欄和小地圖,在底部看到具有一致圖像的咒語

更新為 16:9 比例的橫向圖像,在 UI 中添加更多咒語,并縮小視覺效果,以便我們以第三人稱視角看到貓穿過蒸汽朋克曼哈頓,創造出美麗的對比度和燈光,就像在最好的三 A 游戲中一樣,配以冷色調

當玩家打開菜單時創建界面,我們會看到貓的角色資料及其裝備以及另一頁顯示活躍任務(并且它應該與我們在圖像中描述的宇宙世界構建有關系)
遵循指令
GPT?4o 的圖像生成遵循詳細的提示,注重細節。其他系統在處理約 5-8 個對象時會遇到困難,而 GPT?4o 可以處理多達 10-20 個不同的對象。對象與其特征和關系的更緊密綁定可以實現更好的控制。
一張正方形圖片,包含一個 4 行 4 列的網格,網格上有 16 個對象,背景為白色。從左到右,從上到下。列表如下:1. 一顆藍色的星星2. 紅色三角形3. 綠色正方形4. 粉色圓圈5. 橙色沙漏6. 紫色無限符號7. 黑白圓點領結8. 扎染“42”9. 一只戴著黑色棒球帽的橙色貓10. 一張帶有寶箱的地圖11. 一雙活動眼珠12. 一個豎起大拇指的表情符號13. 一把剪刀14. 一只藍白相間的長頸鹿15. 用草書寫的“OpenAI”一詞16. 一道彩虹色的閃電
 圖片
圖片
情境學習
GPT?4o 可以分析和學習用戶上傳的圖像,將其細節無縫集成到其上下文中以指導圖像生成。
 圖片
圖片
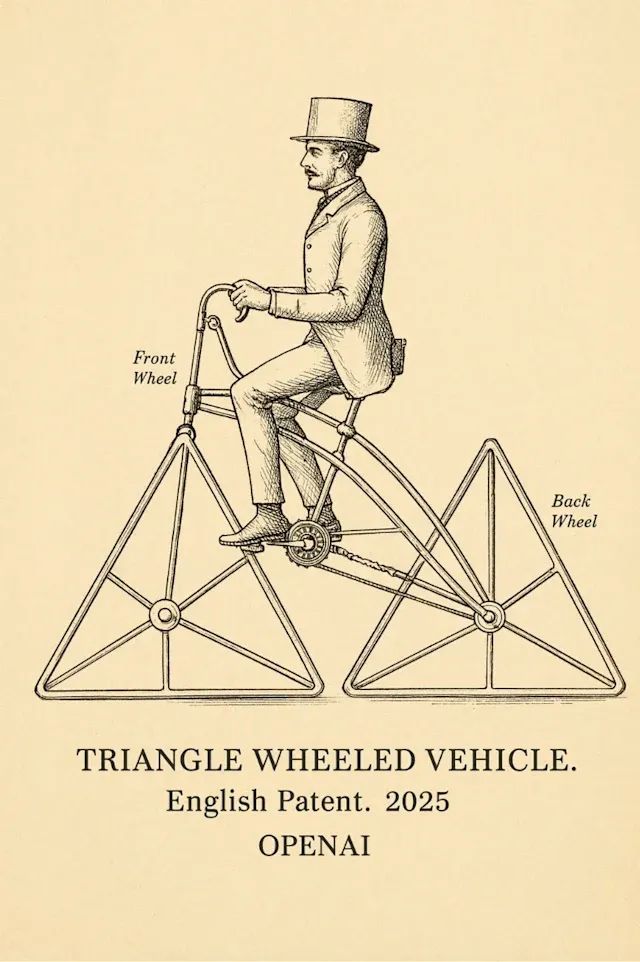
- 使用這些圖像作為參考,繪制帶有三角形車輪的車輛的設計圖。
- 標記前輪、后輪,并在圖表上寫上(小寫)
- 三角輪車輛。英文專利。2025. OPENAI。
現在把它放到一張在紐約市拍攝的照片中。
 圖片
圖片
世界知識原生圖像生成使 4o 能夠將其知識鏈接到文本和圖像之間,從而產生一個感覺更智能、更高效的模型。
示例:可以通過代碼來修改圖像。
 圖片
圖片

照片寫實主義和風格
通過對反映各種圖像風格的圖像進行訓練,模型可以令人信服地創建或轉換圖像。

一種新型的圖片生成方式
一位hackernews用戶表示:關于這種新型圖像生成方式,它通過代token而不是擴散來實現,重要的是它實際上是在像素空間中進行推理。例如:讓它畫一個帶有空白井字棋格的記事本,然后告訴它先走一步,接著你走一步,如此循環。
你還可以進行一些非常令人印象深刻的、保留信息的轉換,比如改變繪畫風格,或者像“將白天變為夜晚”,或者“給他戴上一頂帽子”之類的操作。
“我感覺這些模型在分辨率方面相當受限,但在這個領域進一步的研究將讓我們能夠做出一些真正瘋狂的事情,比如讓模型分步驟完全用圖像創建一個應用程序,本質上是用文字設計整個應用程序,包括文字內容等,然后生成代碼來重現它。這也意味著一個模型可以接替一個優秀的擴散模型,即使最初的生成效果不佳,它也可以在外部圖像上繼續“推理”。”
最后,一旦這些模型的速度提升,你可以想象一個真正的生成式用戶界面,模型根據發送給LLM的事件生成你正在使用的應用程序的下一幀(LLM可以像平時一樣使用工具、思考等)。然而,我也相信擴散模型可以以更快的方式完成其中的一些任務。
甚至有網友曬出了一張被倒滿的酒杯的生成圖像來證明OpenAI攻克了很多業界不能突破的難題。
 圖片
圖片
今日即可訪問和可用性
從今天開始,4o 圖像生成將作為 ChatGPT 中的默認圖像生成器向 Plus、Pro、Team 和 Free 用戶推出,Enterprise 和 Edu 即將推出。它也可以在 Sora 中使用。對于那些對 DALL·E 情有獨鐘的人來說,仍然可以通過專用的 DALL·E GPT 訪問它。
沒錯,免費用戶也可以用,小編也嘗鮮了一把。
同時,開發人員很快就能通過 API 使用 GPT-4o 生成圖像,并將在未來幾周內推出訪問權限。
OpenAI在圖片生成領域不是最早的,前有StableDifussion,后有Midjourney,但大模型的世界就是這么變幻莫測,OpenAI在圖片領域這次可以說是成功逆襲了。