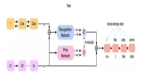
模態編碼器 | EVA探索掩碼視覺表征學習的極限

今天來看一篇經典的視覺表征學習的方法EVA,來自智源研究院發表在2023年CVPR的一篇工作。

項目地址:https://github.com/baaivision/EVA
研究動機:自然語言處理(NLP)領域通過擴展預訓練語言模型(PLMs)取得了革命性的成功,作者希望將這種成功從語言領域轉移到視覺領域,即擴展一個視覺中心的基礎模型,以便于視覺和多模態下游任務。
另外,視覺模型預訓練和擴展的方法主要依賴于監督或弱監督訓練,需要數百萬個(通常是不可公開訪問的)標注數據。作者指出,自然圖像是原始且信息稀疏的,理想的視覺預訓練任務需要抽象出低級幾何結構信息和高級語義信息,而像素級恢復任務很難捕獲這些信息。因此提出EVA。

CLIP 模型輸入為完整的圖像,而 EVA 模型的輸入為有遮蓋的圖像,訓練過程是讓 EVA 模型掩碼部分的輸出去重構 CLIP 模型對應位置的輸出,從而以簡單高效的方式讓 EVA 模型同時擁有了最強語義學習 CLIP 的能力和最強幾何結構學習 MIM 的能力。
01、MIM任務
為了找到一個合適的MIM預訓練任務,本文對比了兩種方法:
(i) 恢復被掩蓋的標記化語義視覺特征,(ii) 從強大的預訓練表示中進行特征蒸餾。這兩種方法都利用了預訓練的圖像-文本對齊視覺特征,即CLIP視覺特征。
EVA分別驗證了MIM中的tokenize和Feature Distillation中的蒸餾方式都不是必要的。不用toeknize和蒸餾的效果對比如下圖所示,圖a和b中第一行都是clip作為teacher模型在下游任務上fintune的效果,最后一行都是EVA模型的效果。區別在于圖a的二三行使用了tokenize的方式訓練了300和1600epoch,但效果都不如沒有使用tokenize訓練800epoch的EVA,證明了tokenize的方式并不必要;圖b中二三行使用Feature Distillation的蒸餾方式訓練了300和800epoch,驗證了蒸餾時間變長,并沒有帶來更大的收益,并且也不如同樣訓練800epoch的EVA,證明了Feature Distillation的蒸餾方式不是必要的。

最后得出結論:
- 選擇MIM任務:選擇了直接回歸被掩碼的CLIP視覺特征作為MIM預訓練任務,因為它能夠同時從圖像-文本對比學習的高級語義抽象和掩碼圖像建模中的幾何與結構的良好捕捉中受益。
- 預訓練任務的優勢:這種預訓練任務能夠覆蓋大多數視覺感知任務所需的信息,并且在大規模參數和未標記數據上具有良好的擴展性。
02、模型訓練
架構配置(Architecture):EVA是基于Vision Transformer(ViT)的模型,具有10億參數。其架構設計參考了ViT巨型模型和BEiT-3的視覺編碼器。在預訓練階段,EVA沒有使用相對位置嵌入和層縮放技術。
預訓練目標(Pre-training Objective)
- 掩碼圖像建模(MIM):EVA通過預測被掩蓋的圖像-文本對齊的視覺特征來進行預訓練,這些特征是基于可見圖像塊的條件。這種方法結合了圖像-文本對比學習的高級語義抽象和掩碼圖像建模中的幾何結構信息。
- 輸入掩碼:輸入圖像塊被[MASK]標記覆蓋,采用塊級掩碼,掩碼比率為40%。
- 目標特征:在EVA模型的預訓練中,這些從OpenAI CLIP-L/14模型提取的特征被用作目標特征。EVA模型通過預測被掩蓋(masked out)的圖像部分對應的CLIP特征來進行訓練。這意味著EVA模型的輸入包括可見的圖像塊和被掩蓋的圖像塊,而它的目標是預測那些被掩蓋塊的CLIP特征。
- 特征處理:EVA的輸出特征首先被標準化,然后通過一個線性層投影到與CLIP特征相同的維度。使用負余弦相似度作為損失函數。
預訓練數據(Pre-training Data):預訓練EVA使用的數據集包括ImageNet-21K、CC12M、CC3M、Object365、COCO和ADE,總共約有2960萬張圖像的。
網絡的整體架構比較簡單,確實相對于MIM是非常簡潔的結構:
- 輸入: 一張圖像,經過兩次增廣,分別作為teacher和student的輸入
- tracher: 一個訓練好的網絡,可以是CLIP或者DINO
- student: 隨機初始化的VIT模型或者swin transformer
- loss: 訓練目標是讓計算teacher網絡輸出的特征和strudent網絡經過projector head后的特征的L1 loss。期望讓student網絡的特征和teacher網絡的特征相似

論文的整體思路很簡單,當然里面也有很多消融實驗讓蒸餾的效果盡可能好。例如和對比學習的方法中一樣,student模型的輸出增加了projector head;為了更好的對比不同teacher模型指導蒸餾的差異,將teacher輸出的特征做了whitening處理將所有teacher模型的特征歸一化到同一量級;VIT中采用相對位置編碼,而不是原始的絕對位置編碼。
03、實驗結果
圖像分類

圖像分類上的結果如上圖所示,最上面三行灰色的部分,模型參數量都在10億以上,效果也是最好的,但使用了大量私有的數據集做訓練。下面的結果除了BEIT外基本都在14M的IN-21K數據集上訓練,但EVA在相同數據規模的情況下,參數量是最大的,且效果也是最好的。
不同數據集上的魯棒性

視頻動作識別

目標檢測和實例分割

語義分割

對比語言-圖像預訓練
實驗設置:使用預訓練的EVA模型作為視覺編碼器,并初始化一個語言編碼器,例如OpenAI CLIP-L模型。采用對比學習來訓練模型,使用大量的圖像-文本對來提供正負樣本。
通過對比語言-圖像預訓練,EVA模型在零樣本分類任務上表現出色,這表明模型能夠捕捉到豐富的視覺和語言特征,并有效地將它們關聯起來。這種方法增強了EVA模型的多模態能力,使其不僅在純視覺任務上表現出色,而且在涉及語言和視覺結合的任務上也具有強大的性能。

EVA-CLIP性能

EVA-CLIP模型在所有三個評估指標上都超過了之前的最佳模型,表明EVA-CLIP模型在自監督學習(SSL)領域具有顯著的性能優勢,特別是在微調和線性探測設置中,EVA-CLIP模型展現了其強大的遷移學習能力和適應性。
04、總結
很有意思的一篇文章,最近也了解了部分蒸餾學習的內容。蒸餾方向的論文,基本都是為了讓一個小的student網絡在不損失太多性能的前提下,學習到大的teacher網絡的特征。 而在大模型時代,EVA探索了student網絡能達到的規模上限,并且在測試集上效果略微超過了teacher網絡。 為什么EVA蒸餾后的網絡會比teacher網絡有更好的效果呢?個人感覺是CLIP確實足夠強大,而且EVA中student網絡的MIM訓練方式足夠的好。具體而言CLIP在4億的圖文對上做了預訓練,輸出的圖像特征和語言的特征做了對齊,是一種高維的語義信息,而VIT作為一個backbone,更利于提取到低維的結構特征,并且MIM的方式迫使VIT學習遮擋不變的特征,最終的特征具有了很好的魯棒性。
對于EVA和EVA-CLIP,
- EVA:主要是一個視覺表示學習模型,專注于通過掩碼圖像建模(MIM)任務來學習強大的視覺特征。EVA的目標是生成能夠有效捕捉圖像內容的視覺表示,通過MIM任務學習到的視覺特征可以用于各種下游視覺任務,如圖像分類、目標檢測和語義分割。
- EVA-CLIP:是一個視覺-語言模型,旨在通過聯合訓練圖像和文本數據來學習圖像和文本之間的對齊關系。EVA-CLIP不僅學習圖像特征,還學習這些特征與相應文本描述之間的關聯,從而支持跨模態任務,如零樣本圖像分類、圖像-文本檢索以及支撐多模態任務。