RAG中基于圖的重排序:利用圖神經網絡革新信息檢索(含代碼)
一、信息檢索的演進與圖重排序的崛起
在大數據與人工智能技術爆發的時代,信息檢索(IR)系統面臨著前所未有的挑戰:用戶查詢日益復雜,跨領域知識需求激增,傳統基于詞法匹配或單一語義向量的檢索模型逐漸暴露局限性。兩階段檢索架構——初始檢索與重排序——雖已成為主流,但第一階段的快速檢索常因忽略文檔間關聯而引入噪聲,第二階段的傳統重排序器(如交叉編碼器)又難以捕捉結構化知識與全局語義關系。在此背景下,基于圖的重排序(Graph-Based Re-ranking)技術應運而生,通過圖神經網絡(GNN)建模文檔、實體與查詢間的復雜關系,為信息檢索領域注入了全新的活力。
 圖片
圖片
(一)傳統檢索架構的瓶頸
傳統兩階段檢索中,初始檢索依賴BM25等詞法模型或稠密向量檢索器快速返回候選集,但這類方法僅能捕獲局部語義匹配,無法感知文檔間的潛在關聯。例如,在醫學檢索中,“心肌梗死”與“心臟病發作”的同義關系可能因詞法差異被忽略。重排序階段雖引入Transformer等模型提升語義理解,但逐點評分模式導致其難以利用文檔集群效應或外部知識,如多篇相關文獻通過共同研究主題形成的關聯網絡。
(二)圖重排序的核心突破
基于圖的重排序技術通過構建查詢-文檔-實體的關聯圖,將檢索問題轉化為圖結構中的信息傳播與推理任務。其核心優勢在于:
- 全局語義建模:通過圖結構顯式表示文檔間的相似性、實體間的語義關系(如知識圖中的“癥狀-疾病”關聯),使重排序器能捕獲傳統模型忽略的全局模式,如相關文檔簇或多跳推理鏈。
- 結構化知識注入:融合外部知識圖(如Wikidata、Freebase)中的實體關系,彌補文本語義的歧義性,尤其適用于醫療、金融等需要領域知識的場景。
- 動態關聯推理:利用GNN的消息傳遞機制,迭代更新節點表示,使文檔評分不僅基于自身內容,還包含鄰居節點的上下文信息,實現“相關文檔互增強”的效應。
二、圖重排序的技術架構與關鍵流程
(一)標準技術流程解析
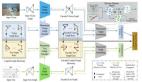
基于圖的重排序在傳統檢索流程中嵌入“圖構建”與“GNN推理”環節,形成五階段技術棧:
- 初始檢索:通過BM25或稠密向量檢索器(如ColBERT)獲取初始候選集,例如返回前1000篇與查詢語義相關的文檔。
- 語義編碼:利用BERT、Sentence-BERT等模型將查詢與文檔編碼為高維向量,捕獲文本語義特征。
- 圖構建:根據節點類型不同,構建文檔級圖或實體級圖:
文檔級圖:節點為文檔,邊為文檔間余弦相似性、共現關鍵詞或預計算的語料庫全局相似性(如GAR模型中的鄰接圖)。
實體級圖:節點為從文本中提取的實體(如人名、疾病名),邊為知識圖中的語義關系(如“治療關系”“同義關系”),典型案例如KGPR模型通過Freebase構建查詢-文檔實體關聯子圖。
- GNN推理:將圖結構與節點特征輸入GCN、GAT等圖神經網絡,通過多層消息傳遞聚合鄰居信息,生成融合上下文關系的文檔表示。例如,GNRR模型通過GNN傳播使相似文檔的相關性分數相互增強。
- 重排序:結合GNN輸出的圖特征與原始語義特征(如查詢-文檔對的交叉編碼分數),通過線性層或神經網絡生成最終相關性分數,實現候選集的重排序。
(二)圖構建的兩類核心范式
- 文檔級圖:捕捉檢索結果的局部關聯
- 相似性圖:基于文檔嵌入的余弦相似性構建無向圖,邊權重反映語義相似度。例如PassageRank模型通過PageRank算法計算圖中節點的重要性分數,假設與多篇相關文檔連接的節點更可能相關。
- 全局預構圖:預先為整個語料庫構建相似性圖(如GAR模型),檢索時動態裁剪為查詢相關的子圖,既能降低在線計算成本,又能利用全局結構信息召回初始檢索遺漏的文檔。
- 實體級圖:注入外部知識的語義橋梁
- 知識圖融合:從查詢與文檔中提取實體(如“阿爾茨海默病”“β-淀粉樣蛋白”),并從知識圖中檢索相關實體及其關系,構建包含領域知識的子圖。例如KGPR模型通過Freebase獲取實體間“發病機制”關系,輔助判斷文檔與查詢的相關性。
- 二分圖建模:構建“文檔-實體”二分圖,節點分別為文檔與實體,邊表示文檔包含該實體。這種結構便于分析文檔的主題一致性,如Document Cohesion Graphs模型通過段落間實體共現評估文檔內聚性。
三、圖神經網絡重排序器的核心類型與典型模型
(一)逐點重排序:個體評分的圖增強
逐點模型為每個文檔獨立生成相關性分數,但通過圖結構豐富其特征表示:
- PassageRank(2020):最早將圖結構引入重排序的模型之一,通過有向圖表示段落間的相似性,利用PageRank算法計算節點中心性,與BERT評分結合提升段落排名準確性。
- GNRR(2024):構建查詢誘導子圖,融合文檔嵌入與查詢嵌入的逐元素乘積作為初始特征,通過GCN聚合鄰居信息,并與獨立的MLP評分器結合,同時捕捉文檔局部相關性與全局上下文。實驗表明,其在多面查詢(如涉及多個子主題的問題)中顯著提升NDCG指標。
- KGPR(2023):基于LUKE模型的知識增強重排序器,通過提取查詢-文檔實體的知識圖子圖,將實體關系嵌入與文本特征融合,在MSMARCO基準上較monoT5提升3.3% MRR,尤其在需要背景知識的“硬查詢”中優勢顯著。
(二)成對與列表式重排序:全局結構的顯式建模
- 成對重排序:基于偏好圖的相對排序
- DuoRank with PageRank(2022):通過采樣文檔對并利用duoT5模型預測偏好關系,構建有向偏好圖,再通過PageRank算法聚合成對判斷,生成全局一致的排序結果。該方法在部分成對比較場景下優于傳統投票法,提升排序魯棒性。
- PRP-Graph(2024):利用LLM直接生成文檔對偏好關系,構建初始偏好圖后通過迭代圖算法優化分數,解決LLM輸出的不一致性問題,實現零樣本場景下的穩定重排序。
- 列表式重排序:滑動窗口與圖擴展的聯合優化
- SlideGAR(2025):結合GAR的圖擴展機制與列表式評分模型(如RankT5),通過滑動窗口逐批重排序文檔,并動態引入相似性圖中的鄰居文檔。該方法既能捕捉文檔組內的交互(如主題多樣性),又能通過圖擴展提升召回率,是當前列表式重排序的代表性工作。
四、性能優勢與領域應用實踐
(一)基準測試中的顯著提升
圖重排序技術在主流IR基準中展現出顯著優勢:
- 通用領域:GNRR在MSMARCO文檔排名任務中,較BM25+交叉編碼器基線提升NDCG@10達8.2%,尤其在需要文檔間關聯推理的查詢中效果突出。
- 專業領域:GraphMonoT5在生物醫學文檔排名中,利用領域知識圖融合文本與實體關系,較原始T5模型提升MAP(平均準確率)12.5%,成功解決“EGFR”與“表皮生長因子受體”的同義匹配問題。
- 生成任務:Graph-RAG模型通過圖重排序優化檢索上下文的相關性與互連性,使生成答案的事實性提升15%,幻覺率降低22%,驗證了圖結構在檢索增強生成(RAG)中的關鍵作用。
(二)典型應用場景
- 多跳問答:通過實體級圖建模查詢與文檔中的實體鏈(如“藥物-靶點-疾病”關系),輔助定位跨文檔的答案片段,如IDR模型通過實體共現圖實現多文檔推理。
- 領域垂直搜索:在醫療檢索中,KGPR利用Freebase構建“癥狀-疾病-療法”子圖,提升罕見病查詢的召回率;在金融領域,KERM模型通過修剪知識圖冗余關系,聚焦“公司-高管-投資”關鍵路徑,提高財報檢索的準確性。
- 推薦系統重排序:借鑒文檔級圖的相似性傳播機制,在商品推薦中構建“用戶-商品-品類”圖,通過GNN捕捉商品間的關聯(如互補品、替代品),提升推薦列表的多樣性與相關性。
五、挑戰與未來發展方向
(一)現存挑戰
- 標準化缺失:缺乏統一的圖重排序基準,不同模型使用的圖構建方法、評估數據集差異較大,導致橫向比較困難。例如,部分模型依賴預計算的全局相似性圖,而 others 基于實時知識圖查詢,難以公平對比。
- 計算成本:構建大規模圖(如千萬級文檔的相似性圖)需要高昂的存儲與計算資源,在線推理時GNN的消息傳遞效率可能成為瓶頸,尤其在處理數千節點的復雜圖時。
- 模型復雜度:圖結構設計(如節點類型、邊權重計算)與GNN架構選擇(如GCN vs GAT)高度依賴經驗,缺乏自動化調優框架,增加了落地門檻。
(二)前沿探索方向
- 輕量級圖構建:研究動態圖生成技術,如基于注意力機制的自適應邊權重計算,或利用聚類算法壓縮圖結構,降低存儲與推理成本。例如,可探索基于對比學習的圖稀疏化方法,僅保留對排序最關鍵的邊。
- 神經符號融合:結合LLM與圖推理,利用大模型生成領域特定的圖構建規則(如生物醫學中的“基因-疾病”關系抽取),或通過圖約束優化LLM的推理路徑,提升復雜查詢的可解釋性。
- 多模態圖重排序:將圖像、視頻等非結構化數據轉換為圖節點,構建跨模態關聯圖。例如,在電商場景中,融合商品圖片的視覺特征與文本描述,通過圖結構建模“視覺相似-語義相關”的跨模態關系。
- 可解釋性增強:開發基于圖的歸因分析方法,如通過GNN的注意力權重可視化文檔間的關聯路徑,或利用知識圖中的三元組解釋排名決策,提升檢索系統的透明度與可信度。
六、圖視角下的檢索革命
基于圖的重排序技術通過將檢索問題轉化為圖結構中的關系推理,突破了傳統模型“孤立評分”的局限,為信息檢索帶來了三大核心價值:全局語義建模能力、結構化知識注入能力、動態關聯推理能力。從早期的PassageRank到最新的SlideGAR,該領域的發展始終圍繞“如何更高效地利用數據間的關聯關系”展開,且在通用搜索、垂直領域、生成式AI等場景中展現出巨大潛力。
盡管面臨標準化、計算效率等挑戰,但隨著GNN架構的優化、LLM與圖推理的深度融合,基于圖的重排序有望成為下一代智能檢索系統的核心組件。未來的信息檢索,或將不再是文檔的簡單羅列,而是通過圖結構編織的“知識網絡”,為用戶提供更精準、更具上下文感知的信息服務——這正是圖神經網絡為檢索領域帶來的革命性變革。