在Hadoop上運行SQL:程序員需知曉的13種數據工具
在GigaOM安排Structure: Data的日程的時候,就意識到很有必要討論在Hadoop上運行SQL查詢,然而卻未認識到Hadoop上運行SQL查詢竟然變的這么重要。本文是Gigaom的資深編輯Derrick Harris 撰寫的一篇文章 ,編譯如下:
其實,對SQL支持并不是Hadoop的最終目標,但是這一特性將會幫助Hadoop找尋自己的生存方式,讓Hadoop在那些已經明白下一代分析的重要性但又不想邁向MapReduce專家之路的公司中取得一席之地。
當然,Facebook發起了整場運動 ——在2009年創造了Hive,它把類似數據庫SQL查詢功能引向了Hadoop 。Hive現在已經是Apache的一個開源項目,包括數據管理層以及類SQL的結構化查詢語言HiveQL。在過去的數年里,Hive的確是非常有用而且很流行,但是由于Hive對MapReduce依賴,查詢速度有著“先天性不足”,因為在查詢的過程中,MapReduce需要掃描整個數據集,而且在Job的處理過程中還需要把大量的數據傳輸到網絡。對主流用戶而言,難以有很大的吸引力。
請記住,下一代的SQL-on-Hadoop工具并不僅僅只是商業智能,也不是僅僅只能讀取存儲在Hadoop上數據的數據庫產品, EMC Greenplum, HP Vertica, IBM Netezza, ParAccel, Microsoft SQL Server以及Teradata/Aster Data全部都允許某些方式的Hadoop數據查詢。而且這些是應用,框架以及可以讓用戶從內部進行Hadoop數據查詢的引擎,有時候也會重構底層計算以及數據基礎設施。這種方式的優點在于:可以利用已有存儲形式的數據,從理論上講,對數據的分析應用就不需要再訪問兩個獨立的數據存儲。
數據倉庫和BI:The Structure: Data set
Apache Drill: Drill是由MapR主導、基于Hadoop之上的類似于谷歌的Demel(或者說BigQuery)交互式查詢引擎。***公布在8月份,不過該項目正處在開發階段,也是Apache的孵化器計劃,根據其網站所言:“(Drill)明確的目標就是擴展到10000臺服務器,而且能夠在幾秒鐘之內處理PB級的數據和數萬億條的記錄。”
MapR的產品管理總監Tomer Shiran表示:“Drill與MapReduce相輔相成。在谷歌,數以千計的工程師每天都在使用Dremel和MapReduce,未來也將有著更多的人來使用Drill與MapReduce。 ”
Hadapt:Hadapt實際上在2011年的Structure: Data大會上發布,它也是***批SQL-on-Hadoop的廠商之一,其獨特之處在于,在市場上已經有了真正的產品,而且已經培育了自己的客戶群。其***的架構包括先進的SQL分析工具,為MapReduce以及相關任務打造的split-execution引擎,也包含HDFS和相關的存儲。
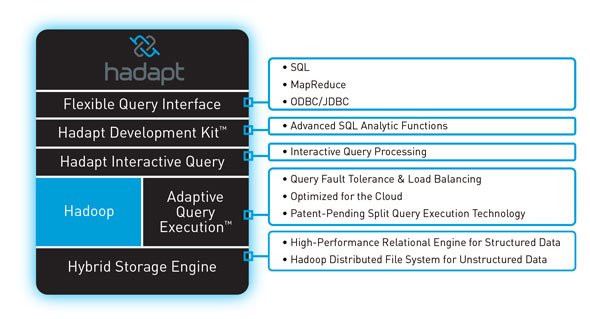
Hadapt提供了一體化的分析環境,旨在對Hadoop里面的數據執行分析操作,還能對SQL環境中傳統的結構化數據進行分析。而Hadapt的平臺設計成了可以在私有云或公共云環境上運行,提供了從一個環境就能訪問所有數據的優點,所以除了MapReduce流程和大數據分析工具外,現有的基于SQL的工具也可以使用。Hadapt可以在Hadoop層和關系數據庫層之間自動劃分查詢執行任務,提供了Hadapt所謂的優化環境,這種環境可以充分利用Hadoop的可擴展性和關系數據庫技術的快速度。
Platfora:從技術來講,這并不是一個SQL產品,Platfora現在是“紅的發紫”,而且意圖打造大數據商業智能(BI)的新藍圖。大家都知道,如何能夠把冗雜的數據(不管是郵件、文檔、音頻等)進行有效處理、視覺化,讓它變成普通的用戶都能看得懂的東西,“數據”才能真正變得有價值。但是Hadpoop只有一小部分開發者(相對而言)在使用,而Platfora卻想把它變成一個任何人都可以理解、使用的工具。雖然也有其他的創業者在做類似的事情,但是Platfora在數據處理速度上有明顯的優勢,同時非常直觀,并且他們在用HTML5的canvas來做解決方案,既可以保證操作簡便又能兼容不同設備上的數據,公司在10月份進行的產品發布。
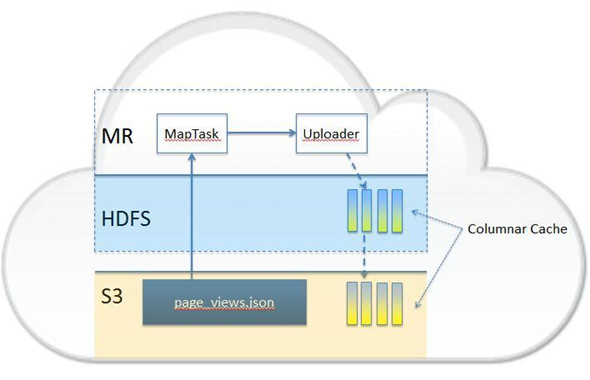
Qubole:Qubole是一個建設云平臺進行數據分析和處理的創業公司。聯合創始人兼CEO是Ashishi Thusoo,在創辦Qubole之前,Ashishi負責Facebook數據基礎設施團隊。在他的領導下,團隊創造了世界上***的數據分析與處理平臺。他也是Apache Hive項目的聯合創始人,并作為該項目的Apache軟件基金會的創始副總裁。Qubole聲稱具有自動擴展能力,并且對Hadoop代碼做過優化,高速的列數據緩存可以讓其服務比單獨運行Hive時要快很多。Qubole運行在AWS上,相對而言,這比維護一個物理集群要容易得多。
 #p#
#p#
數據倉庫和BI:續篇
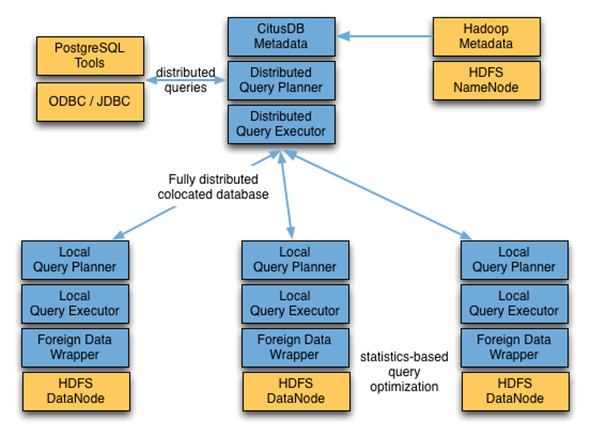
Citus Data: Citus Data的CitusDB并不僅僅只關注于Hadoop,而是想把其分布式的Postgres能力擴展到所有的數據類型中。其中的一項功能“foreign data wrappers”,它能夠把多種數據類型(像CSV, log以及JSON files,而且這些數據類型在原生的Postgres上是并不匹配的)轉化成數據庫的原生類型,接下來在幾秒鐘之內就能使用其特有的分布式處理技術來完成查詢。由于其Postgres的功能,CitusDB也能連接不同的數據源(比如Postgres-Hadoop),這樣就不需要用戶進行獨立的查詢,然后再手動地連接數據。
Cloudera Impala:Cloudera Impala可能是SQL-on-Hadoop上最重要的成果,這是一個大規模的并行處理引擎,成功避開了MapReduce進行交互式地查詢部署在HDFS或者Hbase中的數據。不過,因為Cloudera并不構建應用程序,它依賴更高層次的BI和分析合作伙伴為用戶提供接口。
在2012年紐約進行的大數據技術會議Strata Conference + Hadoop World上,Cloudera發布了實時查詢開源項目Impala 1.0 beta版,稱 比原來基于MapReduce的Hive SQL查詢速度提升3~90倍,而且更加靈活易用。Impala不再使用緩慢的Hive+MapReduce批處理,而是通過與商用并行關系數據庫中類似的分布式查詢引擎(由Query Planner、Query Coordinator和Query Exec Engine三部分組成),可以直接從HDFS或者HBase中用SELECT、JOIN和統計函數查詢數據,從而大大降低了延遲。其架構如下圖所示。
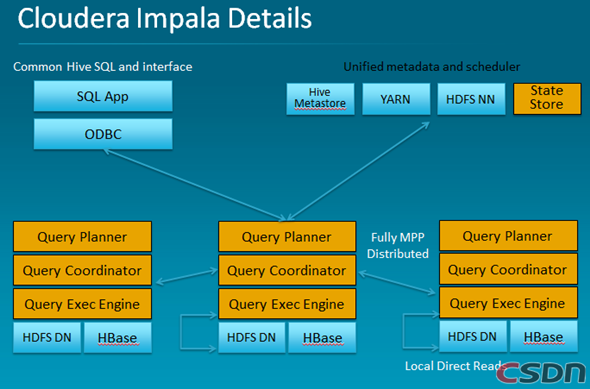
Impala的架構
Karmasphere:就像Hive一樣,Karmasphere也是依賴于MapReduce處理查詢,這也就意味著其速度要慢于其他的新途徑。與Hive不同的是,Karmasphere允許并行查詢,而且其包含一個可視化的界面,可以用于編寫查詢以及過濾查詢結果。
Karmasphere提供了直接訪問Hadoop里面結構化和非結構化數據的優點,它還可以運用SQL及其他語言,用于即席查詢和進一步的分析。使用SQL及其他語言,用戶就能創建即席查詢,然后處理結果。Karmasphere Studio為開發人員提供了一種圖形化環境,可以在里面開發自定義算法,為應用程序和可重復的生產流程創建實用的數據集。
Lingual:Lingual是來自Concurrent的一個新的開源項目,其母公司從事Hadoop Cascading框架設計。Lingual運行在Cascading之上,(Cascading是一個架構在Hadoop上的API,用來創建復雜和容錯數據處理工作流。它抽象了集群拓撲結構和配置來快速開發復雜分布式的應用,而不用考慮背后的MapReduce),并提供給開發者和分析師一個真正的ANSI SQL接口,在其之上可以運行分析或者是構建應用。Lingual兼容傳統的BI工具,JDBC以及Cascading系的API。
Phoenix:Phoenix是一個新的,相對來說并不為人知的一個開源項目,出自Salesforce.com,旨在打造一個更快的SQL查詢,面向的對象有HBase或者是部署在HDFS之上的NoSQL數據庫。用戶通過JDBC接口與其進行交互。
Shark:Shark雖然不是技術上的Hadoop,但是它們也有很深的淵源。Shark,從一定意義上 說代表了“Hive on Spark”,使用Hive也就意味著它與Hadoop也存在著密切的關系。使用Shark運行并行處理Job要比MapReduce快100倍,Shark宣稱對比傳統的Hive而言,這是一個巨大的提升。
Stinger Initiative:Stinger Initiative是由Hortonworks主導的
一個科研成果,可以讓Hive的速度提升高達100倍,而且引入了更多的功能。Stinger為Hive添加了更多的SQL分析能力,但是最關鍵的方面在于底層基礎設施的提升:一個優化的執行引擎,一個列式文件格式,能夠避免MapReduce的運行瓶頸。 #p#
Operational SQL
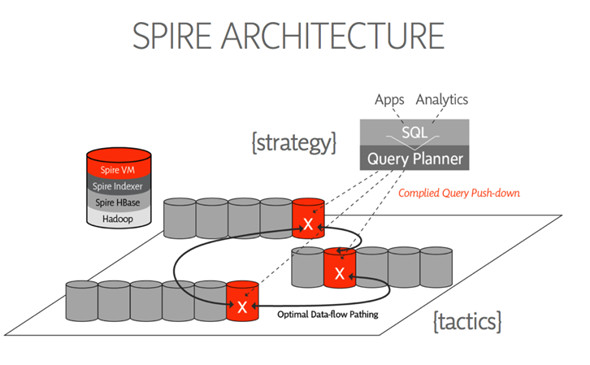
Drawn to Scale:Drawn to Scale也是一家初創公司,它在HBase之上構建了一個 SQL數據庫,這里的關鍵詞是“數據庫”。其產品稱之為Spire,它仿照了谷歌的F1設計。Spire擁有一個分布式索引,所有的查詢只發送給相關數據的存儲節點,所以其讀取和寫入的速度都很快,系統還能夠處理大量的并發用戶。
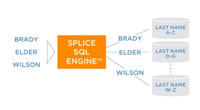
Splice Machine:Splice Machine(數據庫初創公司)也嘗試通過在原生的HBase分布式數據庫上建立其Splice SQL Engine來取得一席之地。Splice Machine關注的是事務完整性,這也是它區別于可擴展的NoSQL數據庫和分析類SQL-on-Hadoop產品的特色所在。它依賴于HBase的auto-sharding功能,這也是為了讓擴展變得更加容易。