社會化海量數據采集爬蟲框架搭建
隨著BIG DATA大數據概念逐漸升溫,如何搭建一個能夠采集海量數據的架構體系擺在大家眼前。如何能夠做到所見即所得的無阻攔式采集、如何快速把不規則頁面結構化并存儲、如何滿足越來越多的數據采集還要在有限時間內采集。這篇文章結合我們自身項目經驗談一下。
我們來看一下作為人是怎么獲取網頁數據的呢?
- 打開瀏覽器,輸入網址url訪問頁面內容。
- 復制頁面內容的標題、作者、內容。
- 存儲到文本文件或者excel。
從技術角度來說整個過程主要為 網絡訪問、扣取結構化數據、存儲。我們看一下用java程序如何來實現這一過程。
- import java.io.IOException;
- import org.apache.commons.httpclient.HttpClient;
- import org.apache.commons.httpclient.HttpException;
- import org.apache.commons.httpclient.HttpStatus;
- import org.apache.commons.httpclient.methods.GetMethod;
- import org.apache.commons.lang.StringUtils;
- public class HttpCrawler {
- public static void main(String[] args) {
- String content = null ;
- try {
- HttpClient httpClient = new HttpClient();
- //1、網絡請求
- GetMethod method = new GetMethod("http://www.baidu.com" );
- int statusCode = httpClient.executeMethod(method);
- if (statusCode == HttpStatus. SC_OK) {
- content = method.getResponseBodyAsString();
- //結構化扣取
- String title = StringUtils.substringBetween(content, "<title>" , "</title>" );
- //存儲
- System. out .println(title);
- }
- } catch (HttpException e) {
- e.printStackTrace();
- } catch (IOException e) {
- e.printStackTrace();
- } finally {
- }
- }
- }
通過這個例子,我們看到通過httpclient獲取數據,通過字符串操作扣取標題內容,然后通過system.out輸出內容。大家是不是感覺做 一個爬蟲也還是蠻簡單呢。這是一個基本的入門例子,我們再詳細介紹怎么一步一步構建一個分布式的適用于海量數據采集的爬蟲框架。
整個框架應該包含以下部分,資源管理、反監控管理、抓取管理、監控管理。看一下整個框架的架構圖:
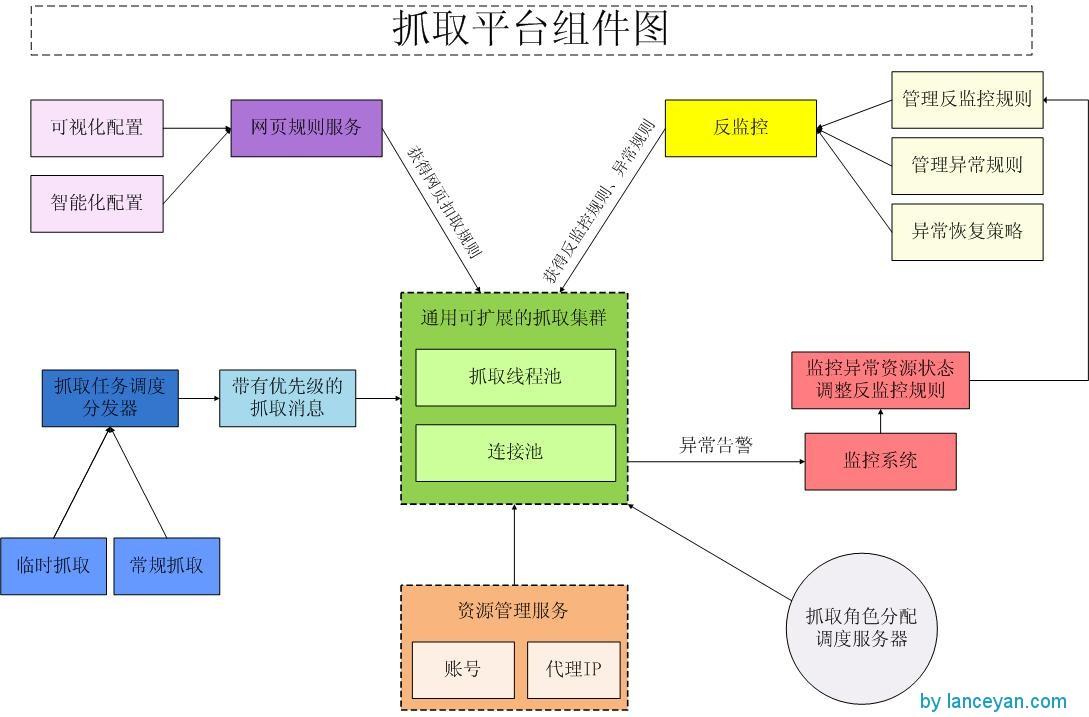
- 資源管理指網站分類體系、網站、網站訪問url等基本資源的管理維護;
- 反監控管理指被訪問網站(特別是社會化媒體)會禁止爬蟲訪問,怎么讓他們不能監控到我們的訪問時爬蟲軟件,這就是反監控機制了
一個好的采集框架,不管我們的目標數據在哪兒,只要用戶能夠看到都應該能采集到。所見即所得的無阻攔式采集,無論是否需要登錄的數據都能夠順利采 集。現在大部分社交網站都需要登錄,為了應對登錄的網站要有模擬用戶登錄的爬蟲系統,才能正常獲取數據。不過社會化網站都希望自己形成一個閉環,不愿意把 數據放到站外,這種系統也不會像新聞等內容那么開放的讓人獲取。這些社會化網站大部分會采取一些限制防止機器人爬蟲系統爬取數據,一般一個賬號爬取不了多 久就會被檢測出來被禁止訪問了。那是不是我們就不能爬取這些網站的數據呢?肯定不是這樣的,只要社會化網站不關閉網頁訪問,正常人能夠訪問的數據,我們也 能訪問。說到底就是模擬人的正常行為操作,專業一點叫“反監控”。
那一般網站會有什么限制呢?
一定時間內單IP訪問次數,沒有哪個人會在一段持續時間內過快訪問,除非是隨意的點著玩,持續時間也不會太長。可以采用大量不規則代理IP來模擬。
一定時間內單賬號訪問次數,這個同上,正常人不會這么操作。可以采用大量行為正常的賬號,行為正常就是普通人怎么在社交網站上操作,如果一個人一天24小時都在訪問一個數據接口那就有可能是機器人了。
如果能把賬號和IP的訪問策略控制好了,基本可以解決這個問題了。當然對方網站也會有運維會調整策略,說到底這是一個戰爭,躲在電腦屏幕后的敵我雙 方,爬蟲必須要能感知到對方的反監控策略進行了調整,通知管理員及時處理。未來比較理想應該是通過機器學習算法自動完成策略調整,保證抓取不間斷。
- 抓取管理指通過url,結合資源、反監控抓取數據并存儲;我們現在大部分爬蟲系統,很多都需要自己設定正則表 達式,或者使用htmlparser、jsoup等軟件來硬編碼解決結構化抓取的問題。不過大家在做爬蟲也會發現,如果爬取一個網站就去開發一個類,在規 模小的時候還可以接受,如果需要抓取的網站成千上萬,那我們不是要開發成百上千的類。為此我們開發了一個通用的抓取類,可以通過參數驅動內部邏輯調度。比 如我們在參數里指定抓取新浪微博,抓取機器就會調度新浪微博網頁扣取規則抓取節點數據,調用存儲規則存儲數據,不管什么類型***都調用同一個類來處理。對 于我們用戶只需要設置抓取規則,相應的后續處理就交給抓取平臺了。
#p#
整個抓取使用了 xpath、正則表達式、消息中間件、多線程調度框架(參考)。xpath 是一種結構化網頁元素選擇器,支持列表和單節點數據獲取,他的好處可以支持規整網頁數據抓取。我們使用的是google插件 XPath Helper,這個玩意可以支持在網頁點擊元素生成xpath,就省去了自己去查找xpath的功夫,也便于未來做到所點即所得的功能。正則表達式補充xpath抓取不到的數據,還可以過濾一些特殊字符。消息中間件,起到抓取任務中間轉發的目的,避免抓取和各個需求方耦合。比如各個業務系統都可能抓取數據,只需要向消息中間件發送一個抓取指令,抓取平臺抓完了會返回一條消息給消息中間件,業務系統在從消息中間件收到消息反饋,整個抓取完成。多線程調度框架之前提到過,我們的抓取平臺不可能在同一時刻只抓一個消息的任務;也不可能無限制抓取,這樣資源會耗盡,導致惡性循環。這就需要使用多線程調度框架來調度多線程任務并行抓取,并且任務的數量,保證資源的消耗正常。
不管怎么模擬總還是會有異常的,這就需要有個異常處理模塊,有些網站訪問一段時間需要輸入驗證碼,如果不處理后續永遠返回不了正確數據。我們需要有機制能夠處理像驗證碼這類異常,簡單就是有驗證碼了人為去輸入,高級一些可以破解驗證碼識別算法實現自動輸入驗證碼的目的。
擴展一下 :所見即所得我們是不是真的做到?規則配置也是個重復的大任務?重復網頁如何不抓取?
1、有些網站利用js生成網頁內容,直接查看源代碼是一堆js。 可以使用mozilla、webkit等可以解析瀏覽器的工具包解析js、ajax,不過速度會有點慢。
2、網頁里有一些css隱藏的文字。使用工具包把css隱藏文字去掉。
3、圖片flash信息。 如果是圖片中文字識別,這個比較好處理,能夠使用ocr識別文字就行,如果是flash目前只能存儲整個url。
4、一個網頁有多個網頁結構。如果只有一套抓取規則肯定不行的,需要多個規則配合抓取。
5、html不完整,不完整就不能按照正常模式去扣取。這個時候用xpath肯定解析不了,我們可以先用htmlcleaner清洗網頁后再解析。
6、 如果網站多起來,規則配置這個工作量也會非常大。如何幫助系統快速生成規則呢?首先可以配置規則可以通過可視化 配置,比如用戶在看到的網頁想對它抓取數據,只需要拉開插件點擊需要的地方,規則就自動生成好了。另在量比較大的時候可視化還是不夠的,可以先將類型相同 的網站歸類,再通過抓取的一些內容聚類,可以統計學、可視化抓取把內容扣取出幾個版本給用戶去糾正,***確認的規則就是新網站的規則。這些算法后續再講。 這塊再補充一下(多謝zicjin建議):
背景:如果我們需要抓取的網站很多,那如果靠可視化配置需要耗費大量的人力,這是個成本。并且這個交給不懂html的業務去配置 準確性值得考量,所以***還是需要技術做很多事情。那我們能否通過技術手段可以幫助生成規則減少人力成本,或者幫助不懂技術的業務準確的把數據扣取下來并 大量復制。
方案:先對網站分類,比如分為新聞、論壇、視頻等,這一類網站的網頁結構是類似的。在業務打開需要扣取的還沒有錄入我們規則庫的 網頁時,他先設定這個頁面的分類(當然這個也可以機器預先判斷,他們來選擇,這一步必須要人判斷下),有了分類后,我們會通過“統計學、可視化判斷”識別 這一分類的字段規則,但是這個是機器識別的規則,可能不準確,機器識別完后,還需要人在判斷一下。判斷完成后,***形成規則才是新網站的規則
7、對付重復的網頁,如果重復抓取會浪費資源,如果不抓需要一個海量的去重判斷緩存。判斷抓不抓,抓了后存不存,并且這個緩存需要快速讀寫。常見的做法有bloomfilter、相似度聚合、分類海明距離判斷。
- 監控管理指不管什么系統都可能出問題,如果對方服務器宕機、網頁改版、更換地址等我們需要***時間知道,這時監控系統就起到出現了問題及時發現并通知聯系人。
目前這樣的框架搭建起來基本可以解決大量的抓取需求了。通過界面可以管理資源、反監控規則、網頁扣取規則、消息中間件狀態、數據監控圖表,并且可以 通過后臺調整資源分配并能動態更新保證抓取不斷電。不過如果一個任務的處理特別大,可能需要抓取24個小時或者幾天。比如我們要抓取一條微博的轉發,這個 轉發是30w,那如果每頁線性去抓取耗時肯定是非常慢了,如果能把這30w拆分很多小任務,那我們的并行計算能力就會提高很多。不得不提的就是把大型的抓 取任務hadoop化,廢話不說直接上圖:
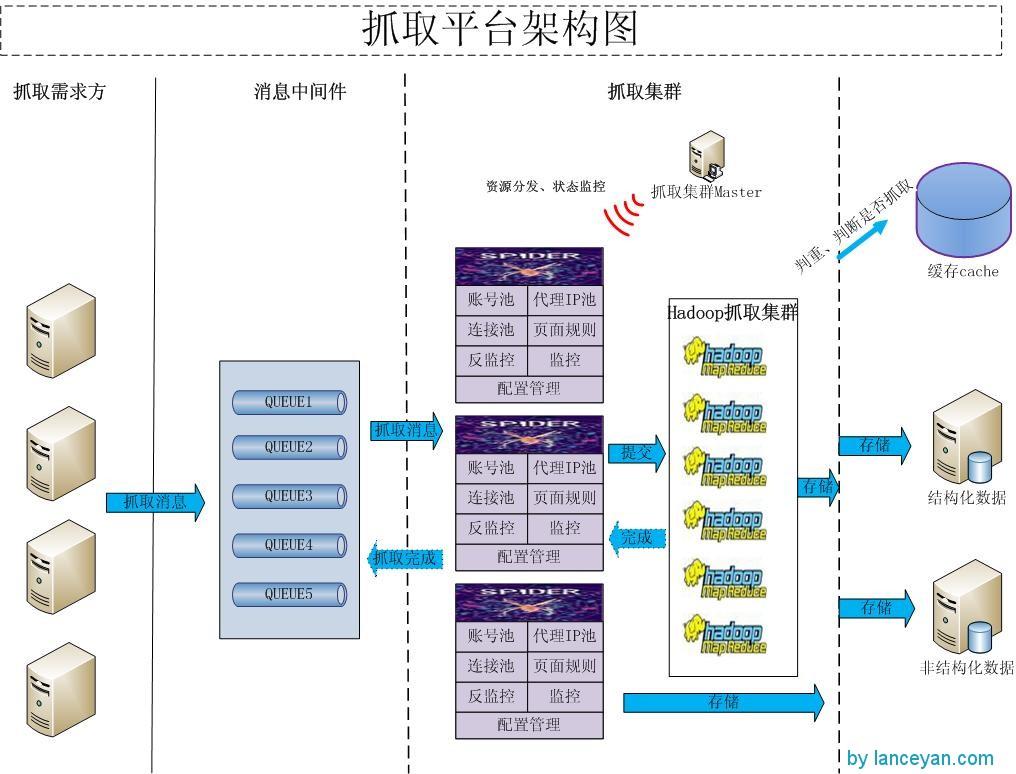
今天先寫到這里,后續再介紹下 日均千萬大型采集項目實戰。