使用深度學習模型在 Java 中執行文本情感分析
積極的? 消極的? 中性的? 使用斯坦福 CoreNLP 組件以及幾行代碼便可對句子進行分析。
本文介紹如何使用集成到斯坦福 CoreNLP(一個用于自然語言處理的開源庫)中的情感工具在 Java 中實現此類任務。
斯坦福 CoreNLP 情感分類器
要執行情感分析,您需要一個情感分類器,這是一種可以根據從訓練數據集中學習的預測來識別情感信息的工具。
在斯坦福 CoreNLP 中,情感分類器建立在遞歸神經網絡 (RNN) 深度學習模型之上,該模型在斯坦福情感樹庫 (SST) 上進行訓練。
SST 數據集是一個帶有情感標簽的語料庫,從數千個使用的句子中推導出每個句法上可能的短語,從而允許捕獲文本中情感的構成效果。簡單來說,這允許模型根據單詞如何構成短語的含義來識別情緒,而不僅僅是通過孤立地評估單詞。
為了更好地了解 SST 數據集的結構,您可從斯坦福 CoreNLP 情感分析頁面下載數據集文件。
在 Java 代碼中,Stanford CoreNLP 情感分類器使用如下。
首先,您通過添加執行情感分析所需的注釋器(例如標記化、拆分、解析和情感)來構建文本處理管道。 就斯坦福 CoreNLP 而言,注釋器是一個對注釋對象進行操作的接口,其中后者表示文檔中的一段文本。 例如,需要使用 ssplit 注釋器將標記序列拆分為句子。
斯坦福 CoreNLP 以每個句子為基礎計算情緒。 因此,將文本分割成句子的過程始終遵循應用情感注釋器。
一旦文本被分成句子,解析注釋器就會執行句法依賴解析,為每個句子生成一個依賴表示。 然后,情感注釋器處理這些依賴表示,將它們與底層模型進行比較,以構建帶有每個句子的情感標簽(注釋)的二值化樹。
簡單來說,樹的節點由輸入句子的標記確定,并包含注釋,指示從句子導出的所有短語的從非常消極到非常積極的五個情感類別中的預測類別。 基于這些預測,情感注釋器計算整個句子的情感。
設置斯坦福 CoreNLP
在開始使用斯坦福 CoreNLP 之前,您需要進行以下設置:
要運行斯坦福 CoreNLP,您需要 Java 1.8 或更高版本。
下載 Stanford CoreNLP 包并將該包解壓縮到您機器上的本地文件夾中。
下載地址:
https://nlp.stanford.edu/software/stanford-corenlp-latest.zip
本文以將上述代碼解壓到如下目錄為例:
c:/softwareInstall/corenlp/stanford-corenlp-4.3.2
完成上述步驟后,您就可以創建運行斯坦福 CoreNLP 管道來處理文本的 Java 程序了。
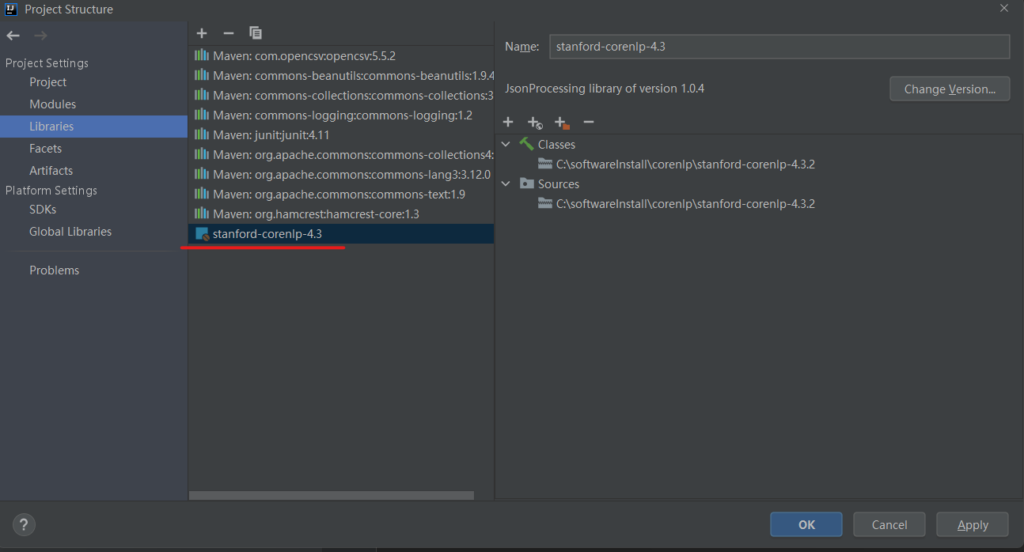
首先新建一個maven項目,并手動將stanford-corenlp-4.3.2添加到Libraries中:
在以下示例中,您將實現一個簡單的 Java 程序,該程序運行斯坦福 CoreNLP 管道,以對包含多個句子的文本進行情感分析。
首先,實現一個NlpPipeline類,該類提供初始化管道的方法和使用此管道將提交的文本拆分為句子然后對每個句子的情感進行分類的方法。 下面是NlpPipeline類代碼:
- package com.zh.ch.corenlp;
- import edu.stanford.nlp.ling.CoreAnnotations;
- import edu.stanford.nlp.neural.rnn.RNNCoreAnnotations;
- import edu.stanford.nlp.pipeline.Annotation;
- import edu.stanford.nlp.pipeline.StanfordCoreNLP;
- import edu.stanford.nlp.sentiment.SentimentCoreAnnotations;
- import edu.stanford.nlp.trees.Tree;
- import edu.stanford.nlp.util.CoreMap;
- import java.util.Properties;
- public class NlpPipeline {
- StanfordCoreNLP pipeline = null;
- public void init()
- {
- Properties props = new Properties();
- props.setProperty("annotators", "tokenize, ssplit, parse, sentiment");
- pipeline = new StanfordCoreNLP(props);
- }
- public void estimatingSentiment(String text)
- {
- int sentimentInt;
- String sentimentName;
- Annotation annotation = pipeline.process(text);
- for(CoreMap sentence : annotation.get(CoreAnnotations.SentencesAnnotation.class))
- {
- Tree tree = sentence.get(SentimentCoreAnnotations.SentimentAnnotatedTree.class);
- sentimentInt = RNNCoreAnnotations.getPredictedClass(tree);
- sentimentName = sentence.get(SentimentCoreAnnotations.SentimentClass.class);
- System.out.println(sentimentName + "\t" + sentimentInt + "\t" + sentence);
- }
- }
- }
init() 方法初始化StanfordCoreNLP 管道,它還初始化使用該情感工具所需的分詞器、依賴解析器和句子拆分器。 要初始化管道,請將帶有相應注釋器列表的 Properties 對象傳遞給 StanfordCoreNLP() 構造函數。 這將創建一個定制的管道,準備好對文本執行情感分析。
在NlpPipeline類的estimatingSentiment()方法中,調用之前創建的管道對象的process()方法,傳入文本進行處理。 process() 方法返回一個注釋對象,該對象存儲對提交的文本的分析。
接下來,迭代注釋對象,在每次迭代中獲得一個句子級 CoreMap 對象。對于這些對象中的每一個,獲取一個包含用于確定底層句子情緒的情緒注釋的 Tree 對象。
將 Tree 對象傳遞給 RNNCoreAnnotations 類的 getPredictedClass() 方法,以提取對應句子的預測情緒的編號代碼。然后,獲取預測情緒的名稱并打印結果。
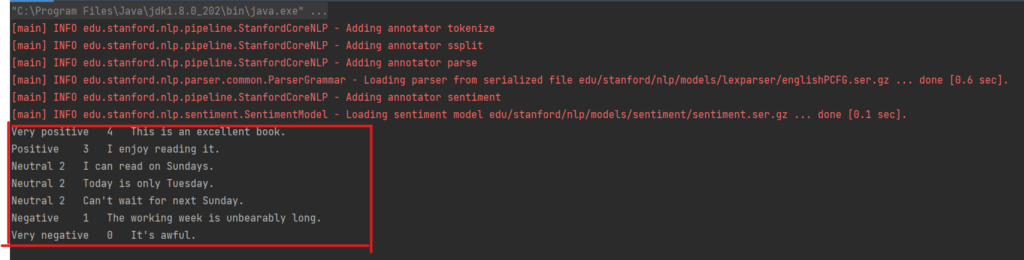
要測試上述功能,請使用調用 init() 方法的 main() 方法實現一個類,然后調用 nlpPipeline 類的 estimatingSentiment() 方法,將示例文本傳遞給后者。
在以下實現中,為了簡單起見,直接指定text文本。示例句子旨在涵蓋斯坦福 CoreNLP 可用的整個情緒評分范圍:非常積極、積極、中立、消極和非常消極。
- package com.zh.ch.corenlp;
- import java.io.FileReader;
- import java.io.IOException;
- public class Main {
- static NlpPipeline nlpPipeline = null;
- public static void processText(String text) {
- nlpPipeline.estimatingSentiment(text);
- }
- public static void main(String[] args) {
- String text = "This is an excellent book. I enjoy reading it. I can read on Sundays. Today is only Tuesday. Can't wait for next Sunday. The working week is unbearably long. It's awful.";
- nlpPipeline = new NlpPipeline();
- nlpPipeline.init();
- processText(text);
- }
- }
執行結果:
分析在線客戶評論
正如您從前面的示例中了解到的,Stanford CoreNLP 可以返回句子的情緒。 然而,有許多用例需要分析多段文本的情緒,每段文本可能包含不止一個句子。 例如,您可能想要分析來自電子商務網站的推文或客戶評論的情緒。
要使用斯坦福 CoreNLP 計算多句文本樣本的情緒,您可能會使用幾種不同的技術。
在處理推文時,您可能會分析推文中每個句子的情緒,如果有一些正面或負面的句子,您可以分別對整個推文進行排名,忽略帶有中性情緒的句子。 如果推文中的所有(或幾乎所有)句子都是中性的,則該推文可以被列為中性。
然而,有時您甚至不必分析每個句子來估計整個文本的情緒。 例如,在分析客戶評論時,您可以依賴他們的標題,標題通常由一個句子組成。
要完成以下示例,您需要一組客戶評論。 您可以使用本文隨附的 NlpBookReviews.csv 文件中的評論。 該文件包含在 Amazon Review Export 的幫助下從 Amazon 網頁下載的一組實際評論,這是一個 Google Chrome 瀏覽器擴展程序,允許您將產品評論及其標題和評級下載到逗號分隔值 (CSV) 文件中 . (您可以使用該工具探索一組不同的評論以進行分析。)
將下述代碼添加到NlpPipeline中
- public String findSentiment(String text) {
- int sentimentInt = 2;
- String sentimentName = "NULL";
- if (text != null && text.length() > 0) {
- Annotation annotation = pipeline.process(text);
- CoreMap sentence = annotation
- .get(CoreAnnotations.SentencesAnnotation.class).get(0);
- Tree tree = sentence
- .get(SentimentCoreAnnotations.SentimentAnnotatedTree.class);
- sentimentInt = RNNCoreAnnotations.getPredictedClass(tree);
- sentimentName = sentence.get(SentimentCoreAnnotations.SentimentClass.class);
- }
- return sentimentName;
- }
您可能會注意到,上面的代碼類似于上一節中定義的 estimatingSentiment() 方法中的代碼。 唯一的顯著區別是這次您沒有迭代輸入文本中的句子。 相反,您只會得到第一句話,因為在大多數情況下,評論的標題由一個句子組成。
下述代碼將從 CSV 文件中讀取評論并將它們傳遞給新創建的 findSentiment() 進行處理,如下所示:
- public static void processCsvComment(String csvCommentFilePath) {
- try (CSVReader reader = new CSVReaderBuilder(new FileReader(csvCommentFilePath)).withSkipLines(1).build())
- {
- String[] row;
- while ((row = reader.readNext()) != null) {
- System.out.println("Review: " + row[1] + "\t" + " Amazon rating: " + row[4] + "\t" + " Sentiment: " + nlpPipeline.findSentiment(row[1]));
- }
- }
- catch (IOException | CsvValidationException e) {
- e.printStackTrace();
- }
- }
執行結果:

完整代碼:
NlpPipeline.java
- package com.zh.ch.corenlp;
- import edu.stanford.nlp.ling.CoreAnnotations;
- import edu.stanford.nlp.neural.rnn.RNNCoreAnnotations;
- import edu.stanford.nlp.pipeline.Annotation;
- import edu.stanford.nlp.pipeline.StanfordCoreNLP;
- import edu.stanford.nlp.sentiment.SentimentCoreAnnotations;
- import edu.stanford.nlp.trees.Tree;
- import edu.stanford.nlp.util.CoreMap;
- import java.util.Properties;
- public class NlpPipeline {
- StanfordCoreNLP pipeline = null;
- public void init() {
- Properties props = new Properties();
- props.setProperty("annotators", "tokenize, ssplit, parse, sentiment");
- pipeline = new StanfordCoreNLP(props);
- }
- public void estimatingSentiment(String text) {
- int sentimentInt;
- String sentimentName;
- Annotation annotation = pipeline.process(text);
- for(CoreMap sentence : annotation.get(CoreAnnotations.SentencesAnnotation.class))
- {
- Tree tree = sentence.get(SentimentCoreAnnotations.SentimentAnnotatedTree.class);
- sentimentInt = RNNCoreAnnotations.getPredictedClass(tree);
- sentimentName = sentence.get(SentimentCoreAnnotations.SentimentClass.class);
- System.out.println(sentimentName + "\t" + sentimentInt + "\t" + sentence);
- }
- }
- public String findSentiment(String text) {
- int sentimentInt = 2;
- String sentimentName = "NULL";
- if (text != null && text.length() > 0) {
- Annotation annotation = pipeline.process(text);
- CoreMap sentence = annotation
- .get(CoreAnnotations.SentencesAnnotation.class).get(0);
- Tree tree = sentence
- .get(SentimentCoreAnnotations.SentimentAnnotatedTree.class);
- sentimentInt = RNNCoreAnnotations.getPredictedClass(tree);
- sentimentName = sentence.get(SentimentCoreAnnotations.SentimentClass.class);
- }
- return sentimentName;
- }
- }
Main.java
- package com.zh.ch.corenlp;
- import com.opencsv.CSVReader;
- import com.opencsv.CSVReaderBuilder;
- import com.opencsv.exceptions.CsvValidationException;
- import java.io.FileReader;
- import java.io.IOException;
- public class Main {
- static NlpPipeline nlpPipeline = null;
- public static void processCsvComment(String csvCommentFilePath) {
- try (CSVReader reader = new CSVReaderBuilder(new FileReader(csvCommentFilePath)).withSkipLines(1).build())
- {
- String[] row;
- while ((row = reader.readNext()) != null) {
- System.out.println("Review: " + row[1] + "\t" + " Amazon rating: " + row[4] + "\t" + " Sentiment: " + nlpPipeline.findSentiment(row[1]));
- }
- }
- catch (IOException | CsvValidationException e) {
- e.printStackTrace();
- }
- }
- public static void processText(String text) {
- nlpPipeline.estimatingSentiment(text);
- }
- public static void main(String[] args) {
- String text = "This is an excellent book. I enjoy reading it. I can read on Sundays. Today is only Tuesday. Can't wait for next Sunday. The working week is unbearably long. It's awful.";
- nlpPipeline = new NlpPipeline();
- nlpPipeline.init();
- // processText(text);
- processCsvComment("src/main/resources/NlpBookReviews.csv");
- }
- }