海量日志中,如何實時在線檢測未知異常行為?看瀚思的序列異常算法
1. 背景
隨著互聯網、移動互聯網的發展,企業的傳統網絡邊界在逐漸消失,工業界的企業,特別是大型互聯網公司,平均每日活躍用戶上千萬,每個應用系統的日志都會高達幾百G字節,甚至達到T數量級,同時,以灰產,黑產為代表的惡意訪問占比依然居高不下,因此,不夸張的說,針對大型互聯網公司,特別是金融、電信等行業的惡意攻擊每天各個時段都在發生,并且攻擊手段在不斷推陳出新。
反觀,傳統的被動防御技術,無論是Firewall、Web應用防火墻(WAF)、入侵防御系統、入侵防御系統(IPS)還是入侵檢測系統(IDS),本質上的工作原理,不是依據白名單,就是基于已發現攻擊總結出的規則,換句話說,傳統防御技術僅限于防御已知威脅。所以,傳統的防御技術,由于不知道何為未知的威脅,既無法檢測到,也就更談不上有效的阻斷。
瀚思以將機器學習應用于信息安全的新角度,重新審視日志信息挖掘,提出了基于日志的實時在線檢測序列異常算法。該算法能夠在線檢測出未知異常行為,并已在國內某Top10券商處上線使用。
2. 何為序列異常
序列異常是對離散異常時序事件的檢測,常應用于工業設備檢測,生物界中的氨基酸序列或基因組序列檢測,用戶行為分析等方面。舉個栗子,一個冰箱的操作日志里,如果存在“冰箱柜門打開,冰箱內物品被取走,冰箱柜門關閉”的序列,認為是正常的。而出現了“冰箱柜門關閉,冰箱內物品被取走,冰箱柜門打開”則是異常的。
簡單來說,序列異常分為兩類。第一類為位置異常,即序列是否異常取決于位置上的實際值與模型預測值間的偏差。第二類是組合異常,以符號組合為考量,對整個序列進行判斷,如果其與絕大多數不同,則被作為異常找出來。
在信息安全領域中,序列異常有很多表現形式。從傳統的SQL注入,XSS攻擊,到撞庫,灰產/黑產的薅羊毛刷單等等。
在用戶行為分析(UBA)中,異常序列一方面能夠找出異常用戶行為序列,另一方面,能更直觀地表現出其為何異常的異常點。
3. 如何找序列異常
無論是找位置異常,還是組合異常,都是找離散類型的時序異常。馬爾科夫鏈模型應用到這類應用中是十分合適的。我們使用了一種變階馬爾科夫鏈模型——Probabilistic Suffix Tree概率后綴樹來查找序列異常。
1) 馬爾科夫鏈模型
馬爾可夫鏈,又稱離散時間馬爾可夫鏈,因俄國數學家安德烈·馬爾可夫得名,為狀態空間中經過從一個狀態到另一個狀態的轉換的隨機過程。該過程要求具備“無記憶”的性質:下一狀態的概率分布只能由當前狀態決定,在時間序列中它前面的事件均與之無關。這種特定類型的“無記憶性”稱作馬爾可夫性質。馬爾科夫鏈作為實際過程的統計模型具有許多應用。
在馬爾可夫鏈的每一步,系統根據概率分布,可以從一個狀態變到另一個狀態,也可以保持當前狀態。狀態的改變叫做轉移,與不同的狀態改變相關的概率叫做轉移概率。隨機漫步就是馬爾可夫鏈的例子。隨機漫步中每一步的狀態是在圖形中的點,每一步可以移動到任何一個相鄰的點,在這里移動到每一個點的概率都是相同的(無論之前漫步路徑是如何的)。
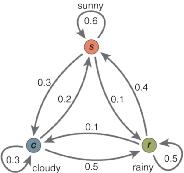
舉個栗子,假設天氣在晴朗sunny,下雨rainy和多云cloudy間互相轉換。
其馬爾科夫狀態圖見下圖。可見每個狀態都可遷移到其它狀態,且概率皆不同。
其對應的一階遷移矩陣,即為下圖。
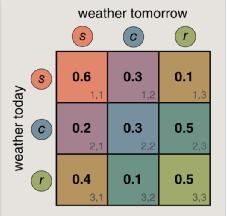
那么,今天是晴天,明天下雨的概率就是
PWeather2=rainy Weather1=sunny)=0.1
馬爾科夫鏈模型對應的異常則為遷移中概率最小的路徑。如
P( Weather1=sunny, Weather2=rainy, Weather3=cloudy, Weather4=sunny, Weather5=rainy )=0.1,就是5階序列中,概率最低,出現可能性最小的序列,被認為是異常。
2) Probabilistic Suffix Tree概率后綴樹
概率后綴樹是一種變階馬爾科夫鏈模型的緊湊形式,它將后綴樹作為索引結構使用。當序列集被組織在概率后綴樹中時,僅通過檢查與樹中根節點相近的點就能區分異常和非異常序列。
概率后綴樹簡單來說,就是將具有預測能力的子序列存儲在一顆后綴樹上。然后,根據序列各子序列在樹中的情況,計算整個序列的概率值。算法將歸一化后的低概率的序列,作為異常找出來。
PST樹例子
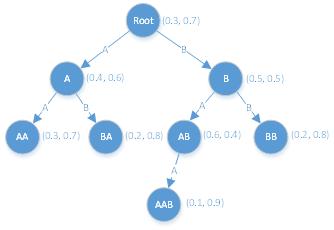
在概率后綴樹中,每個節點代表一個元素,每條邊代表一條從根節點到當前節點的路徑,換句話說,代表一個入樹的子序列。在每個節點上,均有一個概率分布。表示當前節點的下一個后綴子序列的概率。
在構建樹時,需要將沒有預測能力的的子序列和出現極少,本身就是異常的序列全部過濾掉。這樣從根節點開始,以后綴的方式逐步構建出概率后綴樹。建好樹之后,還可以自行設置更嚴格的條件對樹繼續剪枝,使得該樹具有更好的預測能力。
如何使用概率后綴樹計算序列概率值?概率后綴樹能夠利用中間條件概率,從而可以高效計算出概率值。詳細來說就是,某序列P(s)在概率后綴樹上的概率為:
PS= PS1PS2S1)…PSlS1S2…Sl-1)。
舉個栗子,P(BAAB) = P(B)P(A|B)P(A|BA)P(B|BAA)
= 0.7 * 0.5 * 0.2 * 0.7
如何利用概率后綴樹找異常?將測試序列的概率值歸一化后,低概率的序列就是異常序列。
4. 實例分析
1) 在某商業股份制銀行的Web日志中,使用序列異常檢測,發現了灰產/黑產自動化登錄攻擊實例。
在對其銀行手機銀行Web日志常規序列異常檢測中,發現存在一些登錄序列和正常序列區別很大。經過分析后發現,正常用戶登錄是無法產生該序列的。這些序列的出現,和其它證據指明,這些皆為灰產/黑產自動化登錄的產物。
2) 在某券商的Web日志中,通過使用序列異常檢測,發現了一個灰產/黑產可疑的用戶探測行為。
序列異常檢測程序發現,存在一些利用用戶檢存頁面,被惡意地作為用戶探測的手段利用了。經分析,正常用戶使用這些頁面很難產生這些序列。經過調查,以及和業務部門確認,該類序列皆為惡意用戶探測行為。
5. 結語
工業界面臨的現狀是,一方面,傳統的防護手段只能抵御“已知威脅”,迫切需要應對來自“未知威脅”的攻擊。另一方面,互聯網產品快速迭代更新,用戶行為千變萬化,攻擊手段不斷進化,急需可自學習,可實施的高效檢測手段出現。
瀚思的序列異常檢測算法,一來能夠檢測“未知威脅”,二來能夠面對快速變化的環境,進行優化后的在線學習,三來已經在一些公司實際上線,并有所斬獲。
【本文為51CTO專欄作者“瀚思 ”的原創稿件,轉載請通過作者獲取授權】