深度學習要多深,才能讀懂人話?
研究背景
阿里小蜜是阿里巴巴推出的圍繞電商服務、導購以及任務助理為核心的智能人機交互產品,在去年雙十一期間,阿里小蜜整體智能服務量達到643萬,其中智能解決率達到95%,成為了雙十一期間服務的絕對主力。阿里小蜜所使用的問答技術也在經歷著飛速的發展,從最初基于檢索的知識庫問答演進到了***的語義深度建模。
近期,阿里小蜜正在開展新的探索,讓機器具有如同人一般的閱讀理解能力,這將使得問答產品體現出真正的智能,進一步提升服務效率。
在問答技術中,最常見的是檢索式問答,但存在很多的限制,例如,需要人工進行知識提煉,讓機器在事先準備好的問答對基礎之上進行檢索。而我們經常需要對這樣一段話進行提問:
- 5月18日,阿里巴巴集團發布了2017財年Q4財報和2017財年全年的業績報告。財報顯示,阿里巴巴集團2017財年的收入為1582.73億元人民幣,同比增長56%;經調整后凈利為578.71億元人民幣。Q4集團收入為385.79億元,同比增長60%;非美國通用會計準則下的凈利同比增長38%至104.4億元人民幣。
- Q:阿里巴巴2017財年收入是多少呢?
- A:1582.73億人民幣
其中包含很多的數字、日期、金額以及一些客觀事實描述,如果對每個提問點都設置一個問答對,將會是非常繁瑣的過程,同時,由于真實場景中問題的長尾性,人工提煉也無法窮盡所有可能的問題,知識往往覆蓋率比較低。如果能脫離人工提煉知識的過程,直接讓機器在非結構化文本內容中進行閱讀理解,并回答用戶的問題,將是一個里程碑式的進步。
深度學習近年來在自然語言處理領域中廣泛應用,在機器閱讀理解領域也是如此,深度學習技術的引入使得機器閱讀理解能力在最近一年內有了大幅提高,因此我們嘗試結合深度學習與真實業務場景,探索機器閱讀在電商領域的創新與落地場景。
電商領域的應用場景
那么機器閱讀理解及問答技術在電商領域會有哪些合適的應用場景呢?
阿里小蜜的交易規則解讀類場景
首先是電商交易規則解讀類場景,例如在每次雙11等活動時,都會有大量的用戶對活動規則進行咨詢。以往,阿里小蜜的知識運營同學都需要提前研究淘寶和天貓上的活動規則,從一堆規則描述、活動介紹文本中提煉可能的問題。而通過機器閱讀理解的運用,則可以讓機器直接對規則進行閱讀,為用戶提供規則解讀服務,是最自然的交互方式。
2016年淘寶雙十一消費者交易規則
發貨時間說明:
- 2016年11月11日00:00:00-2016年11月17日23:59:59期間付款成果的訂單,確認收到時間如下:
- (1)如果選擇的物流方式為快遞與貨運,自“賣家已發貨”狀態起的15天后,系統會自動確認收貨。
- (2)如果選擇物流方式為平郵,自“賣家已發貨”狀態起的30天后,系統會自動確認收貨。
- 示例提問:我雙十一買的東西什么時候會自動確認收貨?
店小蜜的商品售前咨詢場景
店小蜜是一款面向淘系千萬商家的智能客服。用戶在淘寶和天貓上購物時,往往會對較為關注的商品信息進行詢問確認后才會下單購買,例如“榮耀5c的雙攝像頭拍照效果有什么特點?” 而這些信息往往已經存在于商品的詳情描述頁,通過機器閱讀理解技術,可以讓機器對詳情頁中的商品描述文本進行更為智能地閱讀和回答,降低服務成本的同時提高購買轉化率。
相關工作調研
基于知識庫自動構建的機器閱讀
用傳統的自然語言處理方式完成基于機器閱讀理解的問答,一般需要先在文本中進行實體和屬性的解析,構建出結構化的知識圖譜,并在知識圖譜基礎上進行問答。 主要涉及以下幾個過程:
· 實體檢測:識別文本中提及的實體,對實體進行分類。
· 實體鏈接:將檢測出來的實體與知識庫中現有實體進行匹配和鏈接。
· 屬性填充:從文檔中檢測實體的各類預先定義好的屬性,補充到知識庫中。
· 知識檢索:在知識庫中根據實體和屬性找到最相關的答案作為回答。
顯然,用傳統的知識庫構建方式來進行機器閱讀,雖然其可控性和可解釋性較好,但領域垂直特點較強,難以適應多變的領域場景,且技術上需要分別解決多個傳統NLP中的難點,如命名實體識別、指代消解、新詞發現、同義詞歸一等,而每個環節都可能引入誤差,使得整體誤差逐漸擴大。
基于End-to-end的機器閱讀
近年來,一些高質量的公開數據集為機器閱讀領域的研究帶來了革命性的變化,推動了基于End-to-end方法的高速進步,基于不同的數據集可以解決一些特定的機器閱讀理解任務。以下首先介紹每一類中具有代表性的數據集。
- Facebook的bAbI推理型問答數據集
bAbI數據集是由人工構造的由若干簡單事實形成的英文文章,給出文章和對應問題后,要求機器閱讀理解文章內容并作出一定的推理,從而得出正確答案,往往是文章中的某個(或幾個)關鍵詞或者實體。
數據集包含對20個具體任務的評測,包括Supporting Fact、Yes/No Question、Counting、Time Reasoning、Position Reasoning、Path Finding等等。數據集規模相對比較小,僅由1000個訓練數據和1000個測試數據構成,每個任務150個詞。

- Microsoft的MCTest選擇題數據集
MCTest數據集用于回答選擇題,由真實的英文兒童讀物構成。給出一篇150-300詞的故事文章,并對故事內容進行提問,要求機器在幾個候選答案中選出正確的答案。數據集的數據量較小,分為160篇和500篇兩種。

- DeepMind的CNN\DailyMail完形填空數據集
該數據集來自于真實的新聞數據,但由自動標注而得,并非人工標注。給出一篇新聞和一個問句,把問句中的某個實體抽掉,要求能正確預測被抽掉的實體。這個實體必須是在文中出現過的。該數據集的數據量相對比較大,CNN9有萬篇,DailyMail有22萬篇。

- Facebook的CBT完形填空數據集
該數據集也是由真實的兒童讀物,由自動標注方式構成,其形式是給出21個句子,前20個是完整的供機器閱讀的句子,將第21個句子中的實體抽掉,要求能正確預測出來。

- 訊飛和哈工大的中文完形填空數據集
這是一份中文數據集,和CBT類似,這份數據集是根據真實的新聞數據由自動標注的方式獲得的完形填空數據集,數據集較大,共有87萬篇。

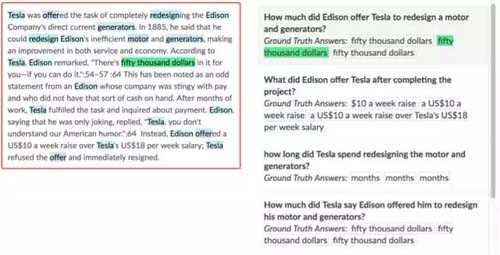
- Stanford的SQuAD可變長答案數據集
SQuAD是斯坦福發布的英文可變長答案數據集。問題和答案由大量眾包人力來標注。內容主要以Wiki文章為主,涵蓋了體育、政治、商業等各種領域的內容。數據集包含500多篇文章(在1000篇文章中隨機選取,保證數據分布廣泛),再將500多篇文章拆成了2萬多個小段落,再對段落進行提問,共10萬個問題(每個段落提5個以上的問題)。
每個問題需要由3位標注者進行標注,其中***位標注者需要提問和回答,后兩位標注者只需回答***位標注者的提問。取第二位標注者的答案作為Human Predict, 取***、三位標注者的答案作為Ground Truth,以此獲得多個Ground Truth來降低標注誤差。且鼓勵標注者用自己的語言來提問,不要去抄原文中的話。
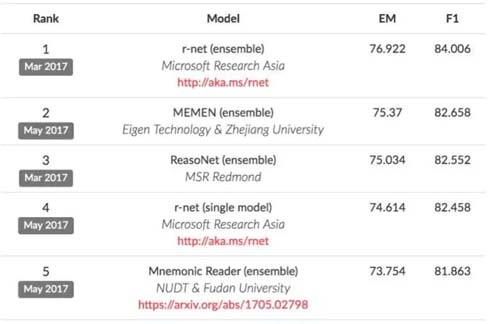
該數據集一經推出便引發學術界的持續關注,在SQuAD的Leadeboard上不斷有新的模型提出一遍遍刷新benchmark,截止目前(2017年6月),***的方法已經獲得超過84的F1值。值得一提的是,Standford在推出該數據集時,基于傳統Lexical特征工程的方式構造了Baseline(考慮Word/POS/Dependency..),作為白盒模型有較好的比較意義,同時也提供了人工評測的Acc作參照,方便衡量問題上界。
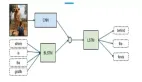
幾乎所有圍繞SQuAD的模型都可以概括為類似的結構:
(1)Embedding層:將原文和問題中的詞匯映射為向量表示。
(2)Encoding層:用RNN對原文和問題進行編碼,使得每個詞蘊含上下文語義信息。
(3)Interaction層:用于捕捉問題和原文之間的交互關系,并輸出編碼了問題語義信息的query-aware的原文表示。
(4)Answer層:基于query-aware的原文表示來預測答案開始和結束的位置。
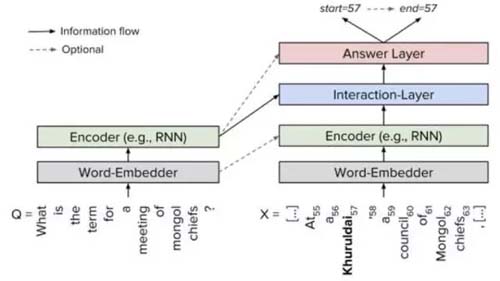
顯然,SQuAD數據集相比之前的完形填空、選擇題型數據集來說,數據量更大、數據質量更高、解決的問題也更復雜,同時也更接近于真實的業務場景,因為在大部分的真實問答場景中,答案都并非單個實體,很可能是一個短句,因此我們將主要圍繞SQuAD LeaderBoard上榜的模型來作一些具體的介紹。
基于SQuAD的機器閱讀模型
- Match-LSTM with AnswerPointer
Match-LSTMwith Answer Pointer模型是較早登上SQuAD LeaderBoard的模型,作者提出了融合 match-lstm 和 pointer-network 的機器閱讀框架,后續也被多篇相關工作所借鑒。其中的Boundary Model由于只預測答案開始和結束位置,極大地縮小了搜索答案的空間,使得整個預測過程得到了簡化。
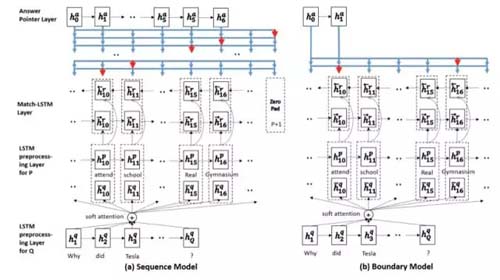
模型主要包括三個部分:
(1)用LSTM分別對question和passage進行encoding;
(2)用match-LSTM對question和passage進行match。這里將question當做premise,將
passage當做hypothesis,用標準的word-by-word attention得到attention向量,然后對question的隱層輸出進行加權,并將其跟passage的隱層輸出進行拼接,得到一個新的向量,然后輸入到LSTM;
(3)利用pointer net從passage中選擇tokens作為答案。包括Sequence Model和Boundary Model。其中Sequence Model是在passage中選擇不連續的word作為answer;BoundaryModel只需要passage的起始位置和中止位置得到連續的words作為answer。
Bidirectional AttentionFlow
BiDAF模型***的特點是在interaction層引入了雙向注意力機制,計算Query2Context和Context2Query兩種注意力,并基于注意力計算query-aware的原文表示。
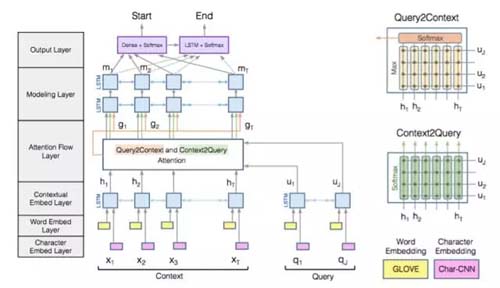
模型由這樣幾個層次組成:
(1)Character Embedding Layer使用char-CNN將word映射到固定維度的向量空間;
(2)Word Embedding Layer使用(pre-trained)word embedding將word映射到固定維度的向量空間;
(3)Contextual Embedding Layer將上面的到的兩個word vector拼接,然后輸入LSTM中進行context embedding;
(4)Attention Flow Layer將passage embedding和question embedding結合,使用Context-to-query Attention 和Query-to-contextAttention得到word-by-word attention;
(5)Modeling Layer將上一層的輸出作為bi-directional RNN的輸入,得到Modeling結果M;
(6)Output Layer使用M分類得到passage的起始位置,然后使用M輸入bi-directional LSTM得到M2,再使用M2分類得到passage的中止位置作為answer。
FastQAExt
FastQAExt***的特點在于其較為輕量級的網絡結構,在輸入的embedding層加入了兩個簡單的統計特征:
(1)文章中的詞是否出現在問題中,是一個binary特征。
(2)基于“問題中的詞如果在原文中很少出現,則對問題的回答影響更大”的原理,設計了一個weighted特征。
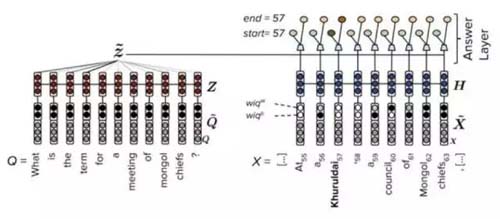
2個統計特征的引入相當于給模型提前提供了先驗知識,這將加快模型的收斂速度,整體上,FastQAExt由以下三個部分組成:
(1)Embedding層:word 和char 兩種embedding,且拼接上述的2種統計特征作為輸入向量。
(2)Encoding層:匯總原文和問題的總表示。
(3)Answer層:計算問題對總表示,將query-aware原文表示和問題總表示共同輸入兩個前饋網絡產生答案開始和結束位置概率。
r-net
r-net是目前在SQuAD LeaderBoard上排名領先的模型,r-net的特點是使用了雙interaction層架構。
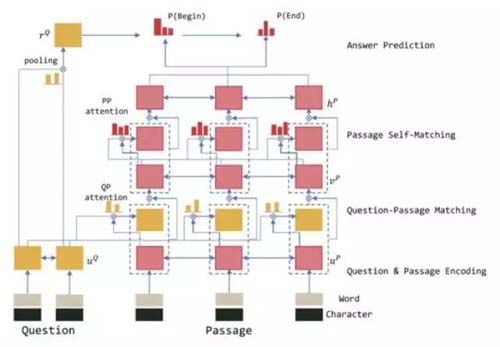
r-net由以下三個部分組成:
(1)Encoding層:使用word和char兩種Embedding作為輸入。
(2)Question-Passage Matching層:負責捕捉原文和問題之間的交互信息。
(3)Passage Self-Matching層:負責捕捉原文內部各詞之間的交互信息。
(4)Answer層:借鑒了match-lstm及pointer network的思路來預測答案的開始和結束位置,并在問題表示上用attention-pooling來生成pointer network的初始狀態。
業務場景下的挑戰與實踐
通過上述介紹可以看到,圍繞SQuAD數據集的機器閱讀理解模型已經在學術界取得了相當大的突破,其解決的問題是在一定長度的wiki內容中進行知識問答,然而阿里小蜜的實際電商業務場景與之相比篇章更長、答案粒度更粗(業務場景下句子粒度居多)、業務含義更復雜且用戶的提問更為隨意,因此SQuAD數據集及其相關模型還不能直接運用于解決我們實際的電商場景問題。
要將機器閱讀理解技術運用到實際業務場景中,還存在相當大到挑戰,我們在以下幾方面進行了探索和實踐:
- 中文數據集的構建
為了使得模型能解決特定的業務問題,標注一個高質量的業務數據集是必不可少的,然而人工標注的成本較高,因此在業務數據集之外,需要將公開的數據集進行結合利用。而目前公開的中文數據集較為缺乏,可以通過批量翻譯等方式快速構造中文數據集,翻譯得到的結果由于保持了詞匯及大致的上下文信息,也能取得一定的訓練效果。
- 模型的業務優化
需要改進模型的結構設計,使得模型可以支持電商文檔格式的輸入。電商規則文檔往往包含大量的文檔結構,如大小標題和文檔的層級結構等,將這些特定的篇章結構信息一起編碼輸入到網絡中,將大幅提升訓練的效果。
- 模型的簡化
學術成果中的模型一般都較為復雜,而工業界場景中由于對性能的要求,無法將這些模型直接在線上使用,需要做一些針對性的簡化,使得模型效果下降可控的情況下,盡可能提升線上預測性能。例如可以簡化模型中的各種bi-lstm結構。
- 多種模型的融合
當前這些模型都是純粹的end-to-end模型,其預測的可控性和可解釋性較低,要適用于業務場景的話,需要考慮將深度學習模型與傳統模型進行融合,達到智能程度和可控性的***平衡點。
- 總結
機器閱讀理解是當下自然語言處理領域的一個熱門任務。近年來,各類閱讀理解的數據集以及方法層出不窮,尤其是圍繞SQuAD數據集的模型正在快速的發展中,這些模型的研究在學術界非常活躍。總的來說,對于解決wiki類客觀知識問答已經取得比較好的結果,但對于復雜問題來說仍處于比較初級的階段。
學術界的思路和工業界實際場景相結合將能產生巨大的價值,阿里小蜜已經在這方面開展探索和落地的嘗試,在算法、模型和數據方面進行積累和沉淀,未來在更多的真實領域場景中,用戶將能感受到機器閱讀理解技術帶來的更為便利的智能服務。
【本文為51CTO專欄作者“阿里巴巴官方技術”原創稿件,轉載請聯系原作者】