如何用Python編寫信息收集之子域名收集腳本?

0×00 前言
任務(wù):
使用腳本借助搜索引擎搜集網(wǎng)站子域名信息。
準(zhǔn)備工具:
python安裝包、pip、http請(qǐng)求庫(kù):requests庫(kù)、正則庫(kù):re庫(kù)。
子域名是相對(duì)于網(wǎng)站的主域名的。比如百度的主域名為:baidu.com,這是一個(gè)***域名,而在***域名前由"."隔開加上不同的字符,比如zhidao.baidu.com,那么這就是一個(gè)二級(jí)域名,同理,繼續(xù)擴(kuò)展主域名的主機(jī)名,如club.user.baidu.com,這就是一個(gè)三級(jí)域名,依次類推。
0X00 正文
手動(dòng)收集子域名是怎樣的一種過(guò)程?
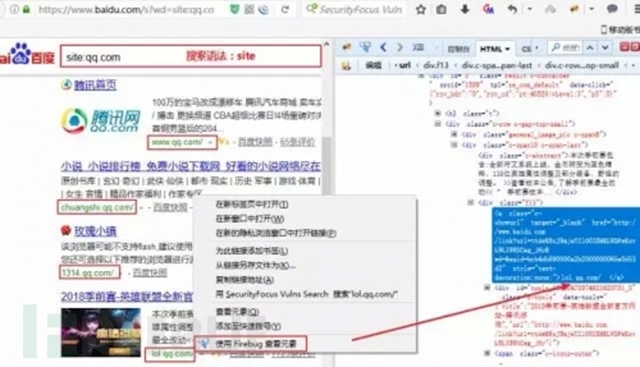
舉個(gè)例子,比如我們要收集qq.com這個(gè)主域名,在百度搜索引擎能夠搜索到的所有子域名。
首先,使用搜索域名的語(yǔ)法搜索~
搜索域名語(yǔ)法:site:qq.com
然后,在搜索結(jié)果中存在我們要的子域名信息,我們可以右鍵,查看元素,復(fù)制出來(lái)。
如何用python替代手工的繁瑣操作?
其實(shí)就是將手工收集用代碼來(lái)實(shí)現(xiàn)自動(dòng)化,手工收集的步驟:
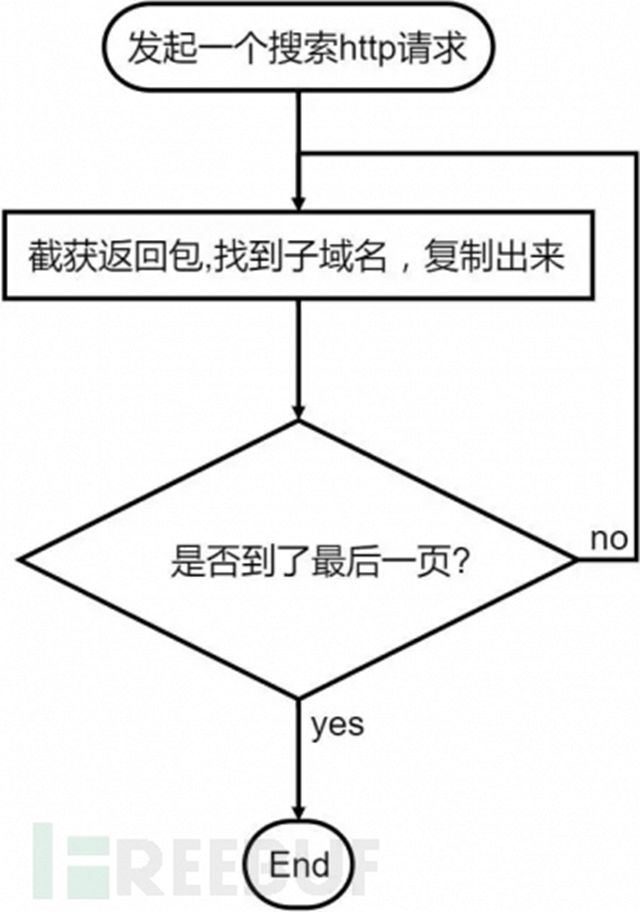
收集器制作開始:
1.發(fā)起一個(gè)搜索的http請(qǐng)求
請(qǐng)求我們使用python的第三方http庫(kù),requests
需要額外安裝,可以使用pip進(jìn)行安裝pipinstallrequests
requests基本使用-example:
help(requests)查看requests的幫助手冊(cè)。
dir(requests)查看requests這個(gè)對(duì)象的所有屬性和方法。
requests.get('http://www.baidu.com'
發(fā)起一個(gè)GET請(qǐng)求。
好了,補(bǔ)充基礎(chǔ)知識(shí),我們來(lái)發(fā)起一個(gè)請(qǐng)求,并獲得返回包的內(nèi)容。
- #-*-coding:utf-8-*-
- import requests #導(dǎo)入requests庫(kù)
- url='http://www.baidu.com/s?wd=site:qq.com' #設(shè)定url請(qǐng)求
- response=requests.get(url).content #get請(qǐng)求,content是獲得返回包正文
- print response
返回包的內(nèi)容實(shí)在太多,我們需要找到我們想要的子域名,然后復(fù)制出來(lái)。
從查看元素我們可以發(fā)現(xiàn),子域名被一段代碼包裹著,如下:
- style="text-decoration:none;">chuangshi.qq.com/ </a>
2.正則表達(dá)式——(.*?) 閃亮登場(chǎng):
正則 規(guī)則:style=”text-decoration:none;”>(.*?)/
正則表達(dá)式難嗎?難。復(fù)雜嗎?挺復(fù)雜的。
然而最簡(jiǎn)單的正則表達(dá)式,我們把想要的數(shù)據(jù)用(.*?)來(lái)表示即可。
re 基本使用-example:
假設(shè)我們要從一串字符串'123xxIxx123xxLikexx123xxStudyxx'取出ILike Study,我們可以這么寫:
- eg='123xxIxx123xxLikexx123xxStudyxx'
- printre.findall('xx(.*?)xx',eg)
- #打印結(jié)果
- ['I','Like','Study']
基于上述例子,依葫蘆畫瓢也可以獲取子域名了。
- #-*-coding:utf-8-*-
- importrequests#導(dǎo)入requests庫(kù)
- importre#導(dǎo)入re庫(kù)
- url='http://www.baidu.com/s?wd=site:qq.com'#設(shè)定url請(qǐng)求
- response=requests.get(url).content#get請(qǐng)求,content是獲得返回包正文
- #重點(diǎn),重點(diǎn),下面這段代碼~
- subdomain=re.findall('style="text-decoration:none;">(.*?)/',response)
- printsubdomain
結(jié)果:
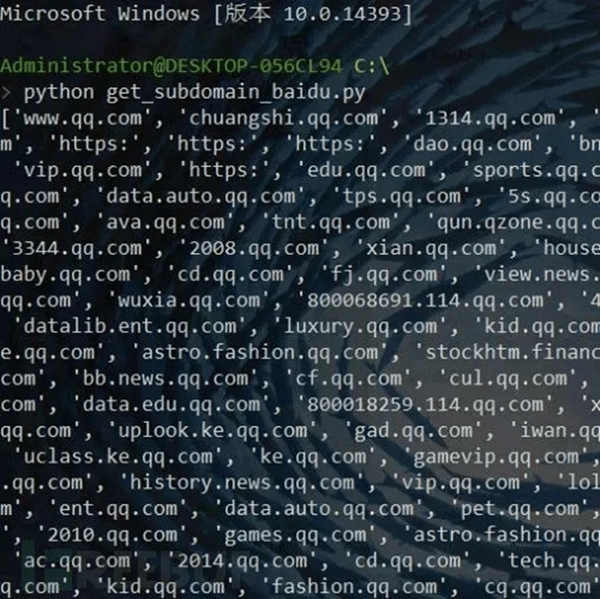
- ['www.qq.com','chuangshi.qq.com','1314.qq.com','lol.qq.com','tgp.qq.com','open.qq.com','https:','ac.qq.com']
3.翻頁(yè)的處理
上面獲得的子域名,僅僅只是返回結(jié)果的***頁(yè)內(nèi)容,如何獲取所有頁(yè)面的結(jié)果?
- key=qq.com
- #為url添加頁(yè)碼:
- url="http://www.baidu.com.cn/s?wd=site:"+key+"&cl=3&pn=0"
- url="http://www.baidu.com.cn/s?wd=site:"+key+"&cl=3&pn=10"
- url="http://www.baidu.com.cn/s?wd=site:"+key+"&cl=3&pn=20"
- #pn=0為***頁(yè),pn=10為第2頁(yè),pn=20為第3頁(yè)…
天啊,100頁(yè)我要寫100個(gè)url嗎?當(dāng)然不是,循環(huán)語(yǔ)句解決你的困擾。
- foriinrange(100):#假設(shè)有100頁(yè)
- i=i*10
- url="http://www.baidu.com.cn/s?wd=site:"+key+"&cl=3&pn=%s"%i
4.重復(fù)項(xiàng)太多?想去重?
基礎(chǔ)知識(shí):
python的數(shù)據(jù)類型:set
set持有一系列的元素,但是set的元素沒(méi)有重復(fù)項(xiàng),且是無(wú)序的。
創(chuàng)建set的方式是調(diào)用set()并傳入一個(gè)list,list的元素將作為set的元素。
sites=list(set(sites))#用set實(shí)現(xiàn)去重
正則表達(dá)式匹配得到的是一個(gè)列表list,我們調(diào)用set()方法即可實(shí)現(xiàn)去重。
5.完整代碼&&總結(jié)
下面是百度搜索引擎爬取子域名的完整代碼。
- #-*-coding:utf-8-*-
- importrequests
- importre
- key="qq.com"
- sites=[]
- match='style="text-decoration:none;">(.*?)/'
- foriinrange(48):
- i=i*10
- url="http://www.baidu.com.cn/s?wd=site:"+key+"&cl=3&pn=%s"%i
- response=requests.get(url).content
- subdomains=re.findall(match,response)
- sites+=list(subdomains)
- site=list(set(sites))#set()實(shí)現(xiàn)去重
- printsite
- print"Thenumberofsitesis%d"%len(site)
- foriinsite:
- printi
結(jié)果截圖:
0X02 總結(jié)
其實(shí)子域名挖掘就是一個(gè)小小的爬蟲,只不過(guò)我們是用百度的引擎來(lái)爬取,不過(guò)呢,用bing引擎爬去的數(shù)據(jù)量會(huì)比百度更多,所以建議大家使用bing的引擎,代碼的編寫方法和百度的大同小異就不放代碼了,給個(gè)小tip,bing搜索域名用的是domain:qq.com這個(gè)的語(yǔ)法哦。