用Python寫(xiě)一個(gè)小白也能懂的分布式知乎爬蟲(chóng)
很早就有采集知乎用戶數(shù)據(jù)的想法,要實(shí)現(xiàn)這個(gè)想法,需要寫(xiě)一個(gè)網(wǎng)絡(luò)爬蟲(chóng)(Web Spider)。因?yàn)樵趯W(xué)習(xí) python,正好 python 寫(xiě)爬蟲(chóng)也是極好的選擇,于是就寫(xiě)了一個(gè)基于 python 的網(wǎng)絡(luò)爬蟲(chóng)。
幾個(gè)月前寫(xiě)了爬蟲(chóng)的初版,后來(lái)因?yàn)橐恍┰颍瑫簳r(shí)擱置了下來(lái),最近重新拾起這個(gè)想法。首先優(yōu)化了代碼的結(jié)構(gòu),然后在學(xué)弟的提醒下,從多線程改成了多進(jìn)程,一臺(tái)機(jī)器上運(yùn)行一個(gè)爬蟲(chóng)程序,會(huì)啟動(dòng)幾百個(gè)子進(jìn)程加速抓取。
但是一臺(tái)機(jī)器的性能是有極限的,所以后來(lái)我使用 MongoDB 和 Redis 搭建了一個(gè)主從結(jié)構(gòu)的分布式爬取系統(tǒng),來(lái)進(jìn)一步加快抓取的速度。
然后我就去好幾個(gè)服務(wù)器廠商申請(qǐng)免費(fèi)的試用,比如百度云、騰訊云、Ucloud…… 加上自己的筆記本,斷斷續(xù)續(xù)抓取了一個(gè)多周,才采集到300萬(wàn)知乎用戶數(shù)據(jù)。中間還跑壞了運(yùn)行網(wǎng)站的云主機(jī),還好 自動(dòng)備份 起作用,數(shù)據(jù)沒(méi)有丟失,但那又是另外一個(gè)故事了……
廢話不多說(shuō),下面我介紹一下如何寫(xiě)一個(gè)簡(jiǎn)單的分布式知乎爬蟲(chóng)。
抓取知乎用戶的個(gè)人信息
給大家推薦一個(gè)學(xué)習(xí)交流的地方,想要學(xué)習(xí)Python的小伙伴可以一起來(lái)學(xué)習(xí),719+139+688,入坑需謹(jǐn)慎,對(duì)Python沒(méi)啥興趣的就不要來(lái)湊熱鬧啦。我們要抓取知乎用戶數(shù)據(jù),首先要知道在哪個(gè)頁(yè)面可以抓取到用戶的數(shù)據(jù)。知乎用戶的個(gè)人信息在哪里呢,當(dāng)然是在用戶的主頁(yè)啦,我們以輪子哥為例 ~
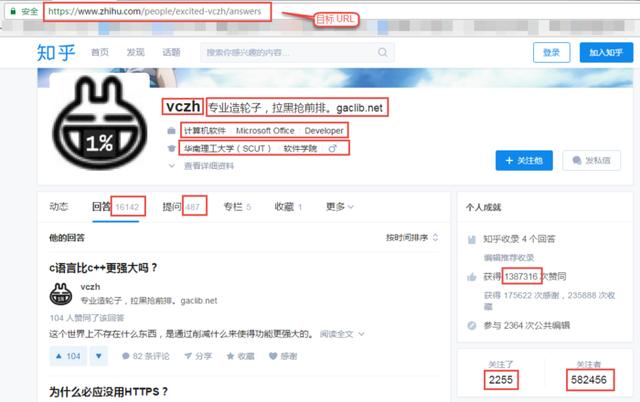
紅框里的便我們要抓取的用戶關(guān)鍵信息(的一部分)。
最上面是我們的目標(biāo)URL:https://www.zhihu.com/people/excited-vczh/answers。
觀察一下這個(gè)URL的組成:
- http://www.zhihu.com + /people + /excited-vczh + /answer
可以發(fā)現(xiàn)只有 excited-vczh 這部分是會(huì)變化的,它代表著知乎用戶的唯一ID,在知乎的數(shù)據(jù)格式中,它的鍵名叫做 urlToken。
所以我們可以用拼接字符串的形式,得到我們待抓取頁(yè)面的URL:
- url = '%s/people/%s/answers'%(host,urlToken)
頁(yè)面URL有了,而且從上圖我們可以發(fā)現(xiàn) 不登錄 也可以訪問(wèn)用戶主頁(yè),這說(shuō)明我們可以不用考慮模擬登陸的問(wèn)題,可以自由的獲取用戶主頁(yè)面源碼。
那么我們?nèi)绾螐挠脩糁黜?yè)的源碼中獲取用戶的數(shù)據(jù)呢?一開(kāi)始我以為需要挨個(gè)匹配頁(yè)面中對(duì)應(yīng)的部分,但我查看源碼的時(shí)候發(fā)現(xiàn)知乎把用戶數(shù)據(jù)集集中放到了源碼的一個(gè)地方,那就是 id="data" 的 div 的 data-state 屬性的值中,看下圖:

從上圖我們可以發(fā)現(xiàn),date-state 的屬性值中藏有用戶的信息,比如我們可以依次找到用戶的教育經(jīng)歷(educations)、簡(jiǎn)介(headline)、參與的 Live 數(shù)量(participatedLiveCount)、關(guān)注的收藏夾數(shù)量(followingFavlistsCount)、被收藏的次數(shù)(favoritedCount)、關(guān)注他的用戶數(shù)(followerCount)、關(guān)注的話題數(shù)量(followingTopicCount)、用戶描述(description)等信息。通過(guò)觀察我們也可以發(fā)現(xiàn),數(shù)據(jù)應(yīng)該是以 JSON 格式存儲(chǔ)。
知道了用戶數(shù)據(jù)都藏在 date-state 中,我們 用 BeautifulSoup 把該屬性的值取出來(lái),然后作為 JSON 格式讀取,再把數(shù)據(jù)集中存儲(chǔ)用戶數(shù)據(jù)的部分提取出來(lái)即可,看代碼:
- # 解析htmls = BS(html,'html.parser')# 獲得該用戶藏在主頁(yè)面中的json格式數(shù)據(jù)集data = s.find('div',attrs={'id':'data'})['data-state']
- data = json.loads(data)
- data = data['entities']['users'][urlToken]
如此,我們便得到了某一個(gè)用戶的個(gè)人信息。
抓取知乎用戶的關(guān)注者列表
剛剛我們討論到可以通過(guò)抓取用戶主頁(yè)面源碼來(lái)獲取個(gè)人信息,而用戶主頁(yè)面可以通過(guò)拼接字符串的形式得到 URL,其中拼接的關(guān)鍵是 如何獲取用戶唯一ID —— urlToken?
我采用的方法是 抓取用戶的關(guān)注者列表。
每個(gè)用戶都會(huì)有關(guān)注者列表,比如輪子哥的:
和獲取個(gè)人信息同樣的方法,我們可以在該頁(yè)面源碼的 date-state 屬性值中找到關(guān)注他的用戶(一部分):

名為 ids 的鍵值中存儲(chǔ)有當(dāng)前列表頁(yè)的所有用戶的 urlToken,默認(rèn)列表的每一頁(yè)顯示20個(gè)用戶,所以我們寫(xiě)一個(gè)循環(huán)便可以獲取當(dāng)前頁(yè)該用戶的所有關(guān)注者的 urlToken。
- # 解析當(dāng)前頁(yè)的 html url = '%s/people/%s/followers?page=%d'%(host,urlToken,page)
- html = c.get_html(url)
- s = BS(html,'html.parser')# 獲得當(dāng)前頁(yè)的所有關(guān)注用戶data = s.find('div',attrs={'id':'data'})['data-state']
- data = json.loads(data)
- items = data['people']['followersByUser'][urlToken]['ids']for item in items: if item!=None and item!=False and item!=True and item!='知乎用戶'.decode('utf8'):
- node = item.encode('utf8')
- follower_list.append(node)
再寫(xiě)一個(gè)循環(huán)遍歷關(guān)注者列表的所有頁(yè),便可以獲取用戶的所有關(guān)注者的 urlToken。
有了每個(gè)用戶在知乎的唯一ID,我們便可以通過(guò)拼接這個(gè)ID得到每個(gè)用戶的主頁(yè)面URL,進(jìn)一步獲取到每個(gè)用戶的個(gè)人信息。
我選擇抓取的是用戶的關(guān)注者列表,即關(guān)注這個(gè)用戶的所有用戶(follower)的列表,其實(shí)你也可以選擇抓取用戶的關(guān)注列表(following)。我希望抓取更多知乎非典型用戶(潛水用戶),于是選擇了抓取關(guān)注者列表。當(dāng)時(shí)抓取的時(shí)候有這樣的擔(dān)心,萬(wàn)一這樣抓不到主流用戶怎么辦?畢竟很多知乎大V雖然關(guān)注者很多,但是主動(dòng)關(guān)注的人相對(duì)都很少,而且關(guān)注的很可能也是大V。但事實(shí)證明,主流用戶基本都抓取到了,看來(lái)基數(shù)提上來(lái)后,總有縫隙出現(xiàn)。
反爬蟲(chóng)機(jī)制
頻繁抓取會(huì)被知乎封IP,也就是常說(shuō)的反爬蟲(chóng)手段之一,不過(guò)俗話說(shuō)“道高一尺,魔高一丈”,既然有反爬蟲(chóng)手段,那么就一定有反反爬蟲(chóng)手段,咳,我自己起的名……
言歸正傳,如果知乎封了你的IP,那么怎么辦呢?很簡(jiǎn)單,換一個(gè)IP。這樣的思想催生了 代理IP池 的誕生。所謂代理IP池,是一個(gè)代理IP的集合,使用代理IP可以偽裝你的訪問(wèn)請(qǐng)求,讓服務(wù)器以為你來(lái)自不同的機(jī)器。
于是我的 應(yīng)對(duì)知乎反爬蟲(chóng)機(jī)制的策略 就很簡(jiǎn)單了:全力抓取知乎頁(yè)面 --> 被知乎封IP --> 換代理IP --> 繼續(xù)抓 --> 知乎繼續(xù)封 --> 繼續(xù)換 IP..... (手動(dòng)斜眼)
使用 代理IP池,你可以選擇用付費(fèi)的服務(wù),也可以選擇自己寫(xiě)一個(gè),或者選擇用現(xiàn)成的輪子。我選擇用七夜寫(xiě)的 qiyeboy/IPProxyPool 搭建代理池服務(wù),部署好之后,修改了一下代碼讓它只保存https協(xié)議的代理IP,因?yàn)?使用http協(xié)議的IP訪問(wèn)知乎會(huì)被拒絕。
搭建好代理池服務(wù)后,我們便可以隨時(shí)在代碼中獲取以及使用代理 IP 來(lái)偽裝我們的訪問(wèn)請(qǐng)求啦!
(其實(shí)反爬手段有很多,代理池只是其中一種)
簡(jiǎn)單的分布式架構(gòu)
多線程/多進(jìn)程只是***限度的利用了單臺(tái)機(jī)器的性能,如果要利用多臺(tái)機(jī)器的性能,便需要分布式的支持。
如何搭建一個(gè)簡(jiǎn)單的分布式爬蟲(chóng)?
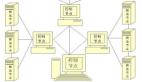
我采用了 主從結(jié)構(gòu),即一臺(tái)主機(jī)負(fù)責(zé)調(diào)度、管理待抓取節(jié)點(diǎn),多臺(tái)從機(jī)負(fù)責(zé)具體的抓取工作。
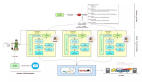
具體到這個(gè)知乎爬蟲(chóng)來(lái)說(shuō),主機(jī)上搭建了兩個(gè)數(shù)據(jù)庫(kù):MongoDB 和 Redis。MongoDB 負(fù)責(zé)存儲(chǔ)抓取到的知乎用戶數(shù)據(jù),Redis 負(fù)責(zé)維護(hù)待抓取節(jié)點(diǎn)集合。從機(jī)上可以運(yùn)行兩個(gè)不同的爬蟲(chóng)程序,一個(gè)是抓取用戶關(guān)注者列表的爬蟲(chóng)(list_crawler),一個(gè)是抓取用戶個(gè)人資料的爬蟲(chóng)(info_crawler),他們可以配合使用,但是互不影響。
我們重點(diǎn)講講主機(jī)上維護(hù)的集合,主機(jī)的 Redis 數(shù)據(jù)庫(kù)中一共維護(hù)了5個(gè)集合:
- waiting:待抓取節(jié)點(diǎn)集合
- info_success:個(gè)人信息抓取成功節(jié)點(diǎn)集合
- info_failed:個(gè)人信息抓取失敗節(jié)點(diǎn)集合
- list_success:關(guān)注列表抓取成功節(jié)點(diǎn)集合
- list_failed:關(guān)注列表抓取失敗節(jié)點(diǎn)集合
這里插一句,之所以采用集合(set),而不采用隊(duì)列(queue),是因?yàn)榧咸烊坏膸в形ㄒ恍裕簿褪钦f(shuō)可以加入集合的節(jié)點(diǎn)一定是集合中沒(méi)有出現(xiàn)過(guò)的節(jié)點(diǎn),這里在5個(gè)集合中流通的節(jié)點(diǎn)其實(shí)是 urlToken。
(其實(shí)集合可以縮減為3個(gè),省去失敗集合,失敗則重新投入原來(lái)的集合,但我為了測(cè)速所以保留了5個(gè)集合的結(jié)構(gòu))
他們的關(guān)系是:
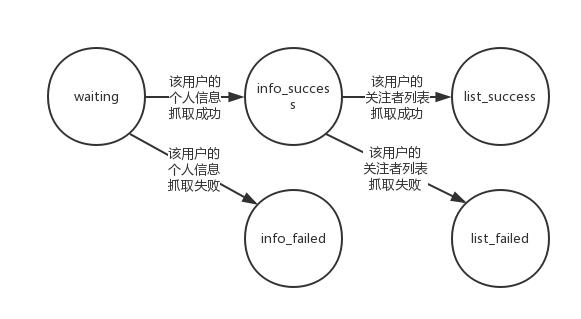
舉個(gè)具體的栗子:從一個(gè) urlToken 在 waiting 集合中出現(xiàn)開(kāi)始,經(jīng)過(guò)一段時(shí)間,它被 info_crawler 爬蟲(chóng)程序從 waiting 集合中隨機(jī)獲取到,然后在 info_crawler 爬蟲(chóng)程序中抓取個(gè)人信息,如果抓取成功將個(gè)人信息存儲(chǔ)到主機(jī)的 MongoDB 中,將該 urlToken 放到 info_success 集合中;如果抓取失敗則將該 urlToken 放置到 info_failed 集合中。下一個(gè)階段,經(jīng)過(guò)一段時(shí)間后,list_crawler 爬蟲(chóng)程序?qū)?info_success 集合中隨機(jī)獲取到該 urlToken,然后嘗試抓取該 urlToken 代表用戶的關(guān)注者列表,如果關(guān)注者列表抓取成功,則將抓取到的所有關(guān)注者放入到 waiting 集合中,將該 urlToken 放到 list_success 集合中;如果抓取失敗,將該 urlToken 放置到 list_failed 集合中。
如此,主機(jī)維護(hù)的數(shù)據(jù)庫(kù),配合從機(jī)的 info_crawler 和 list_crawler 爬蟲(chóng)程序,便可以循環(huán)起來(lái):info_crawler 不斷從 waiting 集合中獲取節(jié)點(diǎn),抓取個(gè)人信息,存入數(shù)據(jù)庫(kù);list_crawler 不斷的補(bǔ)充 waiting 集合。
主機(jī)和從機(jī)的關(guān)系如下圖:
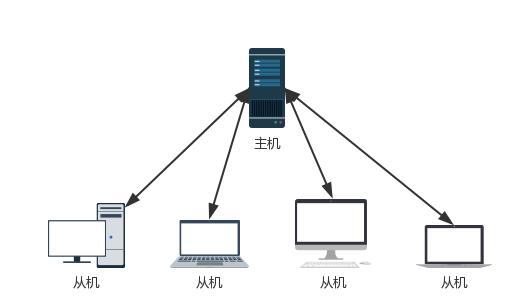
主機(jī)是一臺(tái)外網(wǎng)/局域網(wǎng)可以訪問(wèn)的“服務(wù)器”,從機(jī)可以是PC/筆記本/Mac/服務(wù)器,這個(gè)架構(gòu)可以部署在外網(wǎng)也可以部署在內(nèi)網(wǎng)。