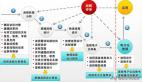
不做保姆式運維,從容接手新業務運維工作
如何接手一個新業務的運維工作?有些東西我們還是要把話說在前面,以免前期不明確造成后期工作的混亂。
1、前期溝通
首先,我們要先跟研發Leader溝通,灌輸運維理念,把丑話說在前頭,我們不做保姆式運維,我們要致力于線上服務安全、穩定、低成本、快速迭代,從運維視角提高產品力。
開發機、測試環境,研發自己搞,我們可以協助幫忙,做專業的咨詢服務,但不可能讓我們直接操刀開發環境的變更。
2、業務概要了解
了解業務相關的人:對應的研發同學、研發Leader、測試同學、測試Leader、產品經理分別是誰,聯系方式存下來,拉個群,出了問題可以找到對應的人。
了解服務是干什么的:解決了什么問題,業界有對標的開源產品嗎……方便我們快速認識這個產品。
了解服務的上下游:依賴哪些服務、哪些服務依賴我、對應的接口人是誰……這里先簡單了解一下即可。
了解服務部署情況:部署在哪些機房、用什么語言編寫、基礎網絡、專線帶寬、機房出口是否靠譜、是否曾因基礎設施導致過問題,當前主要痛點是什么。
3、業務串講
要求研發同學(或者上一任運維同學)準備PPT,做一個業務串講,講解一些研發同學希望傳達給運維同學的信息,同事也講解一些運維同學希望從研發這得到的信息。
比如:詳細部署拓撲、服務整體架構、數據流、提測變更流程、監控方式、部署到了哪些機器、機器登錄方式、每個機器上是什么模塊、OS參數是否有調優,考量是什么、用到了哪些第三方軟件,考量是什么,再比如為什么用了Tomcat而不是Resin、相關Wiki、故障處理預案、常見故障、當前線上問題……
如果業務有單點,不接,讓研發改造。如果運維的老板的老板強制要求,丑話說前頭:因單點導致的問題,運維不背鍋。
4、資產梳理
正式準備接手前,第一步,梳理資產。
比如用到了哪些域名,這些域名對應哪些業務、哪些虛IP,分別是提供了什么服務、哪些機器,分別部署了什么模塊、業務在哪些機房、用了多少帶寬、總帶寬情況、是否有其它業務共用爭搶等。
機器需要拿到更詳盡的信息,比如機器配置、機架位、IP、管理卡IP等等,公司應該有個CMDB供查詢。如果沒有,運維同學,需要你去構建這個CMDB。
后面要考慮機器是否需要有備機、備件,機型是否可以統一。
5、基礎監控
知道有哪些資產了,就可以對這些資產做監控了,比如域名連通性監控/延遲監控、虛IP的連通性監控/延遲監控、機器宕機監控、機器硬件監控、sshd/crond等系統進程監控、系統運行的進程總數監控、系統參數配置監控。
6、服務梳理
吃透之前串講時給的架構圖、數據流圖、部署拓撲圖。從運維層面,最好還要知道公司網絡拓撲圖。
了解每個模塊的情況,部署在哪些機器上、部署在哪個目錄,用什么賬號啟動的、日志打到哪里了、用什么語言編寫的、怎么上線的、主要吃CPU資源還是內存還是磁盤還是IO、需要預留多少資源、平時利用率是多少、應該配置多大的閾值做監控、是否需要watchdog自動拉起、日志里出現哪些關鍵字需要報警以及其他各種需要注意的問題。
7、業務監控
基本的進程、端口存活性監控,機器利用率監控、日志關鍵字監控、日志不滾動監控、關聯的服務的監控等等,后面會做API粒度的監控,來推動業務優化。
8、標準化改造
機器命名方式、操作系統發行版、OS版本、第三方軟件,比如JDK、Tomcat、Nginx,都要統一,要做標準化方案。
服務擴容、變更、下線做一鍵化,每次升級只需要給個版本號即可,此時研發操作還是運維操作效果一樣,故而可以交給研發上線,釋放運維人力,權限要控制好。
重復的常規操作也要固化成腳本,一鍵完成。
梳理故障自愈場景,看平時有哪些故障的處理方式是固定的,抽象為腳本,報警之后自動觸發,無人值守處理。
公司如果有一些基礎設施,比如名字服務、MQ、日志平臺,推動研發改造,將新服務接入。如果公司還沒有這些基礎設施,作為運維這個角色,可以著手搞起。
9、SOP梳理
故障預案是一個非常重要的事情,線上沒出故障之前,就應該提前去想,服務可能會出什么故障;如果真出了,應該如何處理,要把處理步驟提前記錄下來。畢竟,線上出故障的時候,人都比較緊張,直接看著預案處理,就踏實不少,不容易出錯。
10、故障演練
光有預案沒有演練,是不靠譜的,沒有經過驗證的預案是不可信任的。所以,搞個放火演習,把模塊搞掛試一把,把機器搞掛試一把,對線上穩定性絕對會有提升。
特別是研發說這個模塊掛掉,可用性肯定沒影響,OK,先搞掛試試,結果很可能會打他臉。
有些場景演練是會有損的。那這種場景還要不要演練?
這個需要case by case地看。大部分情況都是要做演練會更好,畢竟,人在這盯著的時候出問題,比晚上睡著了出問題要強太多。當然,大規模基礎網絡故障這種演練,還是算了吧,通常的業務都是不具備機房級容災的。
上面做完了,基本工作就完成了。上面很多事情都是一次性的,那未來的大把時間運維做什么?
除了再花費部分時間做線上問題處理,我們應該把主要精力來提升業務產品力。做精細化運維,還記得運維九字真言么?“安全、穩定、高效、低成本”,這就是我們的工作方向。下面會舉幾個例子。
11、再談業務監控
上面談到過一次業務監控,主要是一些通用的監控指標。我們對產品了解足夠之后,應該做一些業務特有的監控,推動研發去做也可以,達到效果就好。
比如你運維了一個MQ,消息堆積量是需要監控的;比如你運維了一個RPC服務,提供了三個接口,這三個接口的響應時長、成功率是需要監控的;再比如你運維了一個S3服務,每個桶的短期帶寬增量你是需要監控的……
現在有那么點感覺了么?
12、API成功率、延遲統計
在流量入口的Nginx做所有業務線的所有API的成功率和延遲統計是非常有必要的。把成功率比較低的TopN找出來,把延遲比較大的TopN找出來,讓業務去優化。老板會喜歡這個的。
13、線上問題梳理
整理線上所有問題,挨個解決,運維可以搞定的運維搞定,運維搞不定的找研發要排期,弄清楚每周解決了多少問題、還有多少問題待解決,用周報的方式體現出來。
14、成本優化
通過服務混部、或者統一的資源調度平臺來節省機器資源,一臺機器便宜的也要好幾萬,這個事是比較容易有產出的。
15、容量規劃
容量規劃和成本優化實際是緊密相關的,容量規劃的重點是根據自然增量和運營需求,提前規劃準備相應的容量。容量可能包括帶寬、專線、網絡設備、機器等等。當業務量下來的時候,可以騰挪相關資源支持其它業務線,讓這些硬件盡量滿負荷運轉,物有所值。
業務精細化運維可以想出各種事情來搞,除了做這事,另一個需要長期投入的是構建運維基礎平臺,像監控系統、部署系統、產品庫、資源利用率平臺、域名管理、四七層接入配置平臺、日志平臺、Trace系統等等……
嗯,其實運維還是挺忙的。
16、關于溝通
最后說一點,接手一個新業務運維,勢必與研發有各種溝通,每次溝通都要寫會議紀要,發郵件出來,跟進人、時間點等都要寫明白。
郵件發送雙方團隊郵件組,cc各方老大。事后關鍵節點做Check,如未完成,線下溝通,達成一致后追此郵件給結論,說明延期原因以及新的時間點。如果溝通不暢,讓老大去協調。
我的看法基本就是這樣,如果大家有其它的觀點或是更好的建議,也歡迎在留言區一起交流。