













達(dá)觀數(shù)據(jù):NLP概述和文本自動(dòng)分類算法詳解

自然語(yǔ)言處理一直是人工智能領(lǐng)域的重要話題,更是2018年的熱度話題,為了在海量文本中及時(shí)準(zhǔn)確地獲得有效信息,文本分類技術(shù)獲得廣泛關(guān)注,也給大家?guī)?lái)了更多應(yīng)用和想象的空間。本文根據(jù)達(dá)觀數(shù)據(jù)聯(lián)合創(chuàng)始人張健的直播內(nèi)容《NLP概述及文本自動(dòng)分類算法詳解》整理而成。
一、NLP概述
1.文本挖掘任務(wù)類型的劃分
文本挖掘任務(wù)大致分為四個(gè)類型:類別到序列、序列到類別、同步的(每個(gè)輸入位置都要產(chǎn)生輸出)序列到序列、異步的序列到序列。
同步的序列到序列的例子包括中文分詞,命名實(shí)體識(shí)別和詞性標(biāo)注。一部的序列到序列包括機(jī)器翻譯和自動(dòng)摘要。序列到類別的例子包括文本分類和情感分析。類別(對(duì)象)到序列的例子包括文本生成和形象描述。
2.文本挖掘系統(tǒng)整體方案
達(dá)觀數(shù)據(jù)一直專注于文本語(yǔ)義,文本挖掘系統(tǒng)整體方案包含了NLP處理的各個(gè)環(huán)節(jié),從處理的文本粒度上來(lái)分,可以分為篇章級(jí)應(yīng)用、短串級(jí)應(yīng)用和詞匯級(jí)應(yīng)用。
篇章級(jí)應(yīng)用有六個(gè)方面,已經(jīng)有成熟的產(chǎn)品支持企業(yè)在不同方面的文本挖掘需求:
垃圾評(píng)論:精準(zhǔn)識(shí)別廣告、不文明用語(yǔ)及低質(zhì)量文本。
黃反識(shí)別:準(zhǔn)確定位文本中所含涉黃、涉政及反動(dòng)內(nèi)容。
標(biāo)簽提取:提取文本中的核心詞語(yǔ)生成標(biāo)簽。
文章分類:依據(jù)預(yù)設(shè)分類體系對(duì)文本進(jìn)行自動(dòng)歸類。
情感分析:準(zhǔn)確分析用戶透過(guò)文本表達(dá)出的情感傾向。
文章主題模型:抽取出文章的隱含主題。
為了實(shí)現(xiàn)這些頂層應(yīng)用,達(dá)觀數(shù)據(jù)掌握從詞語(yǔ)短串分析層面的分析技術(shù),開(kāi)發(fā)了包括中文分詞、專名識(shí)別、語(yǔ)義分析和詞串分析等模塊。
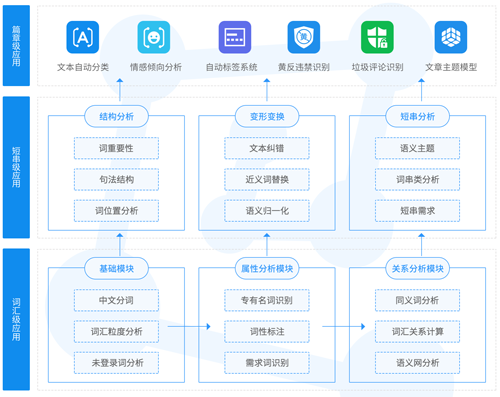
達(dá)觀數(shù)據(jù)文本挖掘架構(gòu)圖
3.序列標(biāo)注應(yīng)用:中文分詞
同步的序列到序列,其實(shí)就是序列標(biāo)注問(wèn)題,應(yīng)該說(shuō)是自然語(yǔ)言處理中最常見(jiàn)的問(wèn)題。序列標(biāo)注的應(yīng)用包括中文分詞、命名實(shí)體識(shí)別和詞性標(biāo)注等。序列標(biāo)注問(wèn)題的輸入是一個(gè)觀測(cè)序列,輸出的是一個(gè)標(biāo)記序列或狀態(tài)序列。
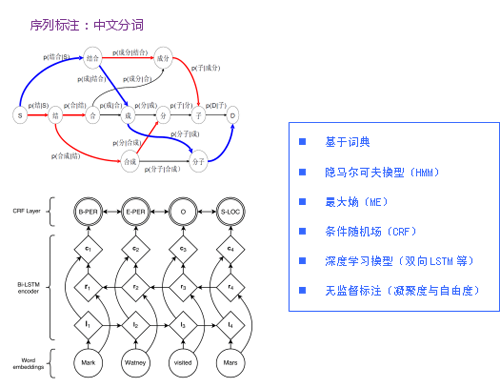
舉中文分詞為例,處理“結(jié)合成分子”的觀測(cè)序列,輸出“結(jié)合/成/分子”的分詞標(biāo)記序列。針對(duì)中文分詞的這個(gè)應(yīng)用,有多種處理方法,包括基于詞典的方法、隱馬爾可夫模型 (HMM)、最大熵模型、條件隨機(jī)場(chǎng)(CRF)、深度學(xué)習(xí)模型(雙向LSTM等)和一些無(wú)監(jiān)督學(xué)習(xí)的方法(基于凝聚度與自由度)。
4.序列標(biāo)注應(yīng)用:NER
命名實(shí)體識(shí)別:Named Entity Recognition,簡(jiǎn)稱NER,又稱作“專名識(shí)別”,是指識(shí)別文本中具有特定意義的實(shí)體,主要包括人名、地名、機(jī)構(gòu)名、專有名詞等。通常包括實(shí)體邊界識(shí)別和確定實(shí)體類別。

對(duì)于命名實(shí)體識(shí)別,采取不同的標(biāo)記方式,常見(jiàn)的標(biāo)簽方式包括IO、BIO、BMEWO和BMEWO+。其中一些標(biāo)簽含義是:
B:begin
I:一個(gè)詞的后續(xù)成分
M:中間
E:結(jié)束
W:?jiǎn)蝹€(gè)詞作為實(shí)體
大部分情況下,標(biāo)簽體系越復(fù)雜準(zhǔn)確度也越高,但相應(yīng)的訓(xùn)練時(shí)間也會(huì)增加。因此需要根據(jù)實(shí)際情況選擇合適的標(biāo)簽體系。通常我們實(shí)際應(yīng)用過(guò)程中,最難解決的還是標(biāo)注問(wèn)題。所以在做命名實(shí)體識(shí)別時(shí),要考慮人工成本問(wèn)題。
5.英文處理
在NLP領(lǐng)域,中文和英文的處理在大的方面都是相通的,不過(guò)在細(xì)節(jié)方面會(huì)有所差別。其中一個(gè)方面,就是中文需要解決分詞的問(wèn)題,而英文天然的就沒(méi)有這個(gè)煩惱;另外一個(gè)方面,英文處理會(huì)面臨詞形還原和詞根提取的問(wèn)題,英文中會(huì)有時(shí)態(tài)變換(made==>make),單復(fù)數(shù)變換(cats==>cat),詞根提取(arabic==>arab)。
在處理上面的問(wèn)題過(guò)程中,不得不提到的一個(gè)工具是WordNet。WordNet是一個(gè)由普林斯頓大學(xué)認(rèn)識(shí)科學(xué)實(shí)驗(yàn)室在心理學(xué)教授喬治·A·米勒的指導(dǎo)下建立和維護(hù)的英語(yǔ)字典。在WordNet中,名詞、動(dòng)詞、形容詞和副詞各自被組織成一個(gè)同義詞的網(wǎng)絡(luò),每個(gè)同義詞集合都代表一個(gè)基本的語(yǔ)義概念,并且這些集合之間也由各種關(guān)系連接。我們可以通過(guò)WordNet來(lái)獲取同義詞和上位詞。
6.詞嵌入
在處理文本過(guò)程中,我們需要將文本轉(zhuǎn)化成數(shù)字可表示的方式。詞向量要做的事就是將語(yǔ)言數(shù)學(xué)化表示。詞向量有兩種實(shí)現(xiàn)方式:One-hot 表示,即通過(guò)向量中的一維0/1值來(lái)表示某個(gè)詞;詞嵌入,將詞轉(zhuǎn)變?yōu)楣潭ňS數(shù)的向量。
word2vec 是使用淺層和雙層神經(jīng)網(wǎng)絡(luò)產(chǎn)生生詞向量的模型,產(chǎn)生的詞嵌入實(shí)際上是語(yǔ)言模型的一個(gè)副產(chǎn)品,網(wǎng)絡(luò)以詞表現(xiàn),并且需猜測(cè)相鄰位置的輸入詞。word2vec中詞向量的訓(xùn)練方式有兩種,cbow(continuous bags of word)和skip-gram。cbow和skip-gram的區(qū)別在于,cbow是通過(guò)輸入單詞的上下文(周圍的詞的向量和)來(lái)預(yù)測(cè)中間的單詞,而skip-gram是輸入中間的單詞來(lái)預(yù)測(cè)它周圍的詞。
7.文檔建模
要使計(jì)算機(jī)能夠高效地處理真實(shí)文本,就必須找到一種理想的形式化表示方法,這個(gè)過(guò)程就是文檔建模。文檔建模一方面要能夠真實(shí)地反映文檔的內(nèi)容,另一方面又要對(duì)不同文檔具有區(qū)分能力。文檔建模比較通用的方法包括布爾模型、向量空間模型(VSM)和概率模型。其中最為廣泛使用的是向量空間模型。
二、文本分類的關(guān)鍵技術(shù)與重要方法
1.利用機(jī)器學(xué)習(xí)進(jìn)行模型訓(xùn)練
文本分類的流程包括訓(xùn)練、文本語(yǔ)義、文本特征處理、訓(xùn)練模型、模型評(píng)估和輸出模型等幾個(gè)主要環(huán)節(jié)。其中介紹一下一些主要的概念。
文檔建模:概率模型,布爾模型,VSM;
文本語(yǔ)義:分詞,命名實(shí)體識(shí)別,詞性標(biāo)注等;
文本特征處理:特征降維,包括使用評(píng)估函數(shù)(TF-IDF,互信息方法,期望交叉熵,QEMI,統(tǒng)計(jì)量方法,遺傳算法等);特征向量權(quán)值計(jì)算;
樣本分類訓(xùn)練:樸素貝葉斯分類器,SVM,神經(jīng)網(wǎng)絡(luò)算法,決策樹(shù),Ensemble算法等;
模型評(píng)估:召回率,正確率,F(xiàn)-測(cè)度值;
輸出模型。
2.向量空間模型
向量空間模型是常用來(lái)處理文本挖掘的文檔建模方法。VSM概念非常直觀——把對(duì)文本內(nèi)容的處理簡(jiǎn)化為向量空間中的向量運(yùn)算,并且它以空間上的相似度表達(dá)語(yǔ)義的相似度,直觀易懂。
當(dāng)文檔被表示為文檔空間的向量時(shí),就可以通過(guò)計(jì)算向量之間的相似性來(lái)度量文檔間的相似性。它的一些實(shí)現(xiàn)方式包括:
1)N-gram模型:基于一定的語(yǔ)料庫(kù),可以利用N-Gram來(lái)預(yù)計(jì)或者評(píng)估一個(gè)句子是否合理;
2)TF-IDF模型:若某個(gè)詞在一篇文檔中出現(xiàn)頻率TF高,卻在其他文章中很少出現(xiàn),則認(rèn)為此詞具有很好的類別區(qū)分能力;
3)Paragraph Vector模型:其實(shí)是word vector的一種擴(kuò)展。Gensim中的Doc2Vec 以及Facebook開(kāi)源的Fasttext工具也是采取了這么一種思路,它們將文本的詞向量進(jìn)行相加/求平均的結(jié)果作為Paragraph Vector。
3.文本特征提取算法
目前大多數(shù)中文文本分類系統(tǒng)都采用詞作為特征項(xiàng),作為特征項(xiàng)的詞稱作特征詞。這些特征詞作為文檔的中間表示形式,用來(lái)實(shí)現(xiàn)文檔與文檔、文檔與用戶目標(biāo)之間的相似度計(jì)算 。如果把所有的詞都作為特征項(xiàng),那么特征向量的維數(shù)將過(guò)于巨大。有效的特征提取算法,不僅能降低運(yùn)算復(fù)雜度,還能提高分類的效率和精度。
文本特征提取的算法包含下面三個(gè)方面:
1)從原始特征中挑選出一些最具代表文本信息的特征,例如詞頻、TF-IDF方法;
2)基于數(shù)學(xué)方法找出對(duì)分類信息貢獻(xiàn)比較大的特征,主要例子包括互信息法、信息增益、期望交叉熵和統(tǒng)計(jì)量方法;
3)以特征量分析多元統(tǒng)計(jì)分布,例如主成分分析(PCA)。
4.文本權(quán)重計(jì)算方法
特征權(quán)重用于衡量某個(gè)特征項(xiàng)在文檔表示中的重要程度或區(qū)分能力的強(qiáng)弱。選擇合適的權(quán)重計(jì)算方法,對(duì)文本分類系統(tǒng)的分類效果能有較大的提升作用。
特征權(quán)重的計(jì)算方法包括:
1)TF-IDF;
2)詞性;
3)標(biāo)題;
4)位置;
5)句法結(jié)構(gòu);
6)專業(yè)詞庫(kù);
7)信息熵;
8)文檔、詞語(yǔ)長(zhǎng)度;
9)詞語(yǔ)間關(guān)聯(lián);
10)詞語(yǔ)直徑;
11)詞語(yǔ)分布偏差。
其中提幾點(diǎn),詞語(yǔ)直徑是指詞語(yǔ)在文本中首次出現(xiàn)的位置和末次出現(xiàn)的位置之間的距離。詞語(yǔ)分布偏差所考慮的是詞語(yǔ)在文章中的統(tǒng)計(jì)分布。在整篇文章中分布均勻的詞語(yǔ)通常是重要的詞匯。
5.分類器設(shè)計(jì)
由于文本分類本身是一個(gè)分類問(wèn)題,所以一般的模式分類方法都可以用于文本分類應(yīng)用中。
常用分類算法的思路包括下面四種:
1)樸素貝葉斯分類器:利用特征項(xiàng)和類別的聯(lián)合概率來(lái)估計(jì)文本的類別概率;
2)支持向量機(jī)分類器:在向量空間中找到一個(gè)決策平面,這個(gè)平面能夠最好的切割兩個(gè)分類的數(shù)據(jù)點(diǎn),主要用于解決二分類問(wèn)題;
3)KNN方法:在訓(xùn)練集中找到離它最近的k個(gè)臨近文本,并根據(jù)這些文本的分類來(lái)給測(cè)試文檔分類;
4)決策樹(shù)方法:將文本處理過(guò)程看作是一個(gè)等級(jí)分層且分解完成的復(fù)雜任務(wù)。
6.分類算法融合
聚合多個(gè)分類器,提高分類準(zhǔn)確率稱為Ensemble方法。
利用不同分類器的優(yōu)勢(shì),取長(zhǎng)補(bǔ)短,最后綜合多個(gè)分類器的結(jié)果。Ensemble可設(shè)定目標(biāo)函數(shù)(組合多個(gè)分類器),通過(guò)訓(xùn)練得到多個(gè)分類器的組合參數(shù)(并非簡(jiǎn)單的累加或者多數(shù))。
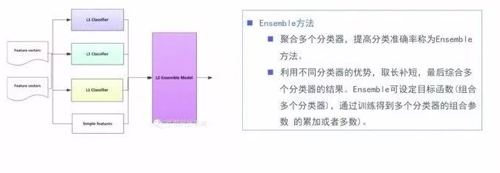
我們這里提到的ensemble可能跟通常說(shuō)的ensemble learning有區(qū)別。主要應(yīng)該是指stacking。
Stacking是指訓(xùn)練一個(gè)模型用于組合其他各個(gè)模型。即首先我們先訓(xùn)練多個(gè)不同的模型,然后再以之前訓(xùn)練的各個(gè)模型的輸出為輸入來(lái)訓(xùn)練一個(gè)模型,以得到一個(gè)最終的輸出。在處理ensemble方法的時(shí)候,需要注意幾個(gè)點(diǎn)。基礎(chǔ)模型之間的相關(guān)性要盡可能的小,并且它們的性能表現(xiàn)不能差距太大。
多個(gè)模型分類結(jié)果如果差別不大,那么疊加效果也不明顯;或者如果單個(gè)模型的效果距離其他模型比較差,也是會(huì)對(duì)整體效果拖后腿。
三、文本分類在深度學(xué)習(xí)中的應(yīng)用
1.CNN文本分類
采取CNN方法進(jìn)行文本分類,相比傳統(tǒng)方法會(huì)在一些方面有優(yōu)勢(shì)。
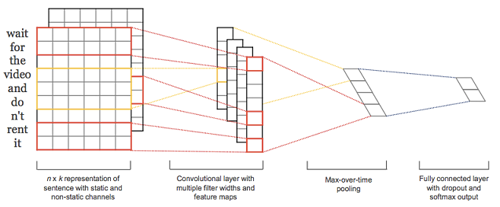
基于詞袋模型的文本分類方法,沒(méi)有考慮到詞的順序。
基于卷積神經(jīng)網(wǎng)絡(luò)(CNN)來(lái)做文本分類,可以利用到詞的順序包含的信息。如圖展示了比較基礎(chǔ)的一個(gè)用CNN進(jìn)行文本分類的網(wǎng)絡(luò)結(jié)構(gòu)。CNN模型把原始文本作為輸入,不需要太多的人工特征。CNN模型的一個(gè)實(shí)現(xiàn),共分四層:
第一層是詞向量層,doc中的每個(gè)詞,都將其映射到詞向量空間,假設(shè)詞向量為k維,則n個(gè)詞映射后,相當(dāng)于生成一張n*k維的圖像;
第二層是卷積層,多個(gè)濾波器作用于詞向量層,不同濾波器生成不同的feature map;
第三層是pooling層,取每個(gè)feature map的最大值,這樣操作可以處理變長(zhǎng)文檔,因?yàn)榈谌龑虞敵鲋灰蕾囉跒V波器的個(gè)數(shù);
第四層是一個(gè)全連接的softmax層,輸出是每個(gè)類目的概率,中間一般加個(gè)dropout,防止過(guò)擬合。
有關(guān)CNN的方法一般都圍繞這個(gè)基礎(chǔ)模型進(jìn)行,再加上不同層的創(chuàng)新。
比如第一個(gè)模型在輸入層換成RNN,去獲得文本通過(guò)RNN處理之后的輸出作為卷積層的輸入。比如說(shuō)第二個(gè)是在pooling層使用了動(dòng)態(tài)kmax pooling,來(lái)解決樣本集合文本長(zhǎng)度變化較大的問(wèn)題。比如說(shuō)第三種是極深網(wǎng)絡(luò),在卷積層做多層卷積,以獲得長(zhǎng)距離的依賴信息。
CNN能夠提取不同長(zhǎng)度范圍的特征,網(wǎng)絡(luò)的層數(shù)越多,意味著能夠提取到不同范圍的特征越豐富。不過(guò)CNN層數(shù)太多會(huì)有梯度彌散、梯度爆炸或者退化等一系列問(wèn)題。
為了解決這些問(wèn)題,極深網(wǎng)絡(luò)就通過(guò)shortcut連接。殘差網(wǎng)絡(luò)其實(shí)是由多種路徑組合的一個(gè)網(wǎng)絡(luò),殘差網(wǎng)絡(luò)其實(shí)是很多并行子網(wǎng)絡(luò)的組合,有些點(diǎn)評(píng)評(píng)殘差網(wǎng)絡(luò)就說(shuō)它其實(shí)相當(dāng)于一個(gè)Ensembling。
2.RNN與LSTM文本分類
CNN有個(gè)問(wèn)題是卷積時(shí)候是固定 filter_size ,就是無(wú)法建模更長(zhǎng)的序列信息,雖然這個(gè)可以通過(guò)多次卷積獲得不同范圍的特征,不過(guò)要付出增加網(wǎng)絡(luò)深度的代價(jià)。
RNN的出現(xiàn)是解決變長(zhǎng)序列信息建模的問(wèn)題,它會(huì)將每一步中產(chǎn)生的信息都傳遞到下一步中。
首先我們?cè)谳斎雽又希咨弦粚与p向LSTM層,LSTM是RNN的改進(jìn)模型,相比RNN,能夠更有效地處理句子中單詞間的長(zhǎng)距離影響;而雙向LSTM就是在隱層同時(shí)有一個(gè)正向LSTM和反向LSTM,正向LSTM捕獲了上文的特征信息,而反向LSTM捕獲了下文的特征信息,這樣相對(duì)單向LSTM來(lái)說(shuō)能夠捕獲更多的特征信息,所以通常情況下雙向LSTM表現(xiàn)比單向LSTM或者單向RNN要好。
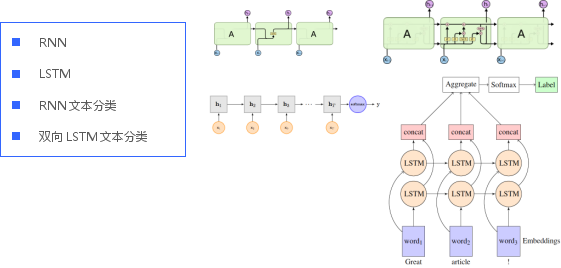
如何從物理意義上來(lái)理解求平均呢?這其實(shí)可以理解為在這一層,兩個(gè)句子中每個(gè)單詞都對(duì)最終分類結(jié)果進(jìn)行投票,因?yàn)槊總€(gè)BLSTM的輸出可以理解為這個(gè)輸入單詞看到了所有上文和所有下文(包含兩個(gè)句子)后作出的兩者是否語(yǔ)義相同的判斷,而通過(guò)Mean Pooling層投出自己寶貴的一票。
3.Attention Model與seq2seq
注意力模型Attention Model是傳統(tǒng)自編碼器的一個(gè)升級(jí)版本。傳統(tǒng)RNN的Encoder-Decoder模型,它的缺點(diǎn)是不管之前的context有多長(zhǎng),包含多少信息量,最終都要被壓縮成固定的vector,而且各個(gè)維度收到每個(gè)輸入維度的影響都是一致的。為了解決這個(gè)問(wèn)題,它的idea其實(shí)是賦予不同位置的context不同的權(quán)重,越大的權(quán)重表示對(duì)應(yīng)位置的context更加重要。
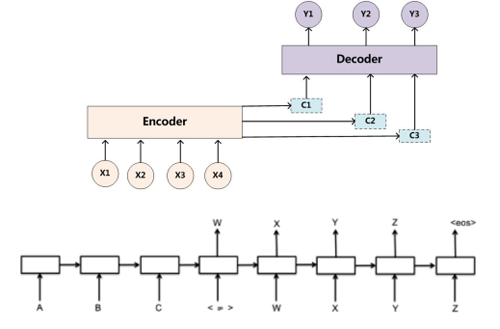
現(xiàn)實(shí)中,舉一個(gè)翻譯問(wèn)題:jack ma dances very well 翻譯成中文是馬云跳舞很好。其中,馬云應(yīng)該是和jack ma關(guān)聯(lián)的。
Attention Model是當(dāng)前的研究熱點(diǎn),它廣泛應(yīng)用于文本生成、機(jī)器翻譯和語(yǔ)言模型等方面。
4.Hierarchical Attention Network
下面介紹層次化注意力網(wǎng)絡(luò)。
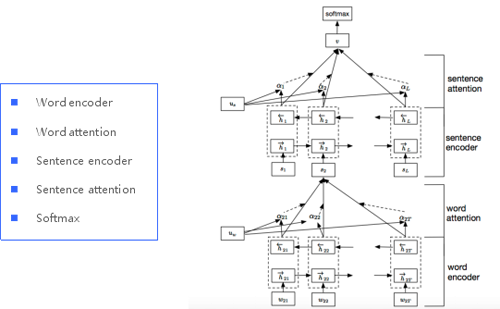
詞編碼層是首先把詞轉(zhuǎn)化成詞向量,然后用雙向的GRU層,可以將正向和反向的上下文信息結(jié)合起來(lái),獲得隱藏層輸出。第二層是word attention層。attention機(jī)制的目的是要把一個(gè)句子中,對(duì)句子的含義最重要,貢獻(xiàn)最大的詞語(yǔ)找出來(lái)。
為了衡量單詞的重要性,我們用u_it和一個(gè)隨機(jī)初始化的上下文向量u_w的相似度來(lái)表示,然后經(jīng)過(guò)softmax操作獲得了一個(gè)歸一化的attention權(quán)重矩陣a_it,代表句子i中第t個(gè)詞的權(quán)重。結(jié)合詞的權(quán)重,句子向量s_i看作組成這些句子的詞向量的加權(quán)求和。
第三層是句子編碼層,也是通過(guò)雙向GRU層,可以將正向和反向的上下文信息結(jié)合起來(lái),獲得隱藏層輸出。
到了第四層是句子的注意力層,同詞的注意力層差不多,也是提出了一個(gè)句子級(jí)別的上下文向量u_s,來(lái)衡量句子在文中的重要性。輸出也是結(jié)合句子的權(quán)重,全文的向量表示看做是句子向量的加權(quán)求和。
到了最后,有了全文的向量表示,我們就直接通過(guò)全連接softmax來(lái)進(jìn)行分類。
四、案例介紹
1.新聞分類
新聞分類是最常見(jiàn)的一種分類。其處理方法包括:
1)定制行業(yè)專業(yè)語(yǔ)料,定期更新語(yǔ)料知識(shí)庫(kù),構(gòu)建行業(yè)垂直語(yǔ)義模型。
2)計(jì)算term權(quán)重,考慮到位置特征,網(wǎng)頁(yè)特征,以及結(jié)合離線統(tǒng)計(jì)結(jié)果獲取到核心的關(guān)鍵詞。
3)使用主題模型進(jìn)行語(yǔ)義擴(kuò)展
4)監(jiān)督與半監(jiān)督方式的文本分類

2.垃圾廣告黃反識(shí)別
垃圾廣告過(guò)濾作為文本分類的一個(gè)場(chǎng)景有其特殊之處,那就是它作為一種防攻擊手段,會(huì)經(jīng)常面臨攻擊用戶采取許多變換手段來(lái)繞過(guò)檢查。
處理這些變換手段有多重方法:
一是對(duì)變形詞進(jìn)行識(shí)別還原,包括要處理間雜特殊符號(hào),同音、簡(jiǎn)繁變換,和偏旁拆分、形近變換。
二是通過(guò)語(yǔ)言模型識(shí)別干擾文本,如果識(shí)別出文本是段不通順的“胡言亂語(yǔ)”,那么它很可能是一段用于規(guī)避關(guān)鍵字審查的垃圾文本。
三是通過(guò)計(jì)算主題和評(píng)論的相關(guān)度匹配來(lái)鑒別。
四是基于多種表達(dá)特征的分類器模型識(shí)別來(lái)提高分類的泛化能力。
3.情感分析
情感分析的處理辦法包括:
1)基于詞典的情感分析,主要是線設(shè)置情感詞典,然后基于規(guī)則匹配(情感詞對(duì)應(yīng)的權(quán)重進(jìn)行加權(quán))來(lái)識(shí)別樣本是否是正負(fù)面。
2)基于機(jī)器學(xué)習(xí)的情感分析,主要是采取詞袋模型作為基礎(chǔ)特征,并且將復(fù)雜的情感處理規(guī)則命中的結(jié)果作為一維或者多維特征,以一種更為“柔性”的方法融合到情感分析中,擴(kuò)充我們的詞袋模型。
3)使用DNN模型來(lái)進(jìn)行文本分類,解決傳統(tǒng)詞袋模型難以處理長(zhǎng)距離依賴的缺點(diǎn)。
4.NLP其他應(yīng)用
NLP在達(dá)觀的其他一些應(yīng)用包括:
1)標(biāo)簽抽取;
2)觀點(diǎn)挖掘;
3)應(yīng)用于推薦系統(tǒng);
4)應(yīng)用于搜索引擎。
標(biāo)簽抽取有多種方式:基于聚類的方法實(shí)現(xiàn)。此外,現(xiàn)在一些深度學(xué)習(xí)的算法,通過(guò)有監(jiān)督的手段實(shí)現(xiàn)標(biāo)簽抽取功能。
就觀點(diǎn)挖掘而言,舉例:床很破,睡得不好。我抽取的觀點(diǎn)是“床破”,其中涉及到語(yǔ)法句法分析,將有關(guān)聯(lián)成本提取出來(lái)。
搜索及推薦,使用到NLP的地方也很多,如搜索引擎處理用戶查詢的糾錯(cuò),就用到信道噪聲模型實(shí)行糾錯(cuò)處理。
最后,給喜愛(ài)NLP的朋友推薦一個(gè)賽事活動(dòng),也是達(dá)觀數(shù)據(jù)主辦的“達(dá)觀杯”文本智能處理挑戰(zhàn)賽,此次比賽以文本自動(dòng)分類為賽題,如果對(duì)上文講到的算法有想練習(xí)或者想深入實(shí)踐,可拿比賽來(lái)練習(xí)充實(shí)一下,目前賽事已有近1400人參賽。點(diǎn)擊閱讀原文可了解比賽詳情,本周四7月26日晚還為大家準(zhǔn)備了深度學(xué)習(xí)與文本智能處理的分享直播,感興趣可掃碼入群了解詳情。

【本文為51CTO專欄作者“達(dá)觀數(shù)據(jù)”的原創(chuàng)稿件,轉(zhuǎn)載可通過(guò)51CTO專欄獲取聯(lián)系】

















