從文本挖掘綜述分類、聚類和信息提取等算法
文本挖掘一直是十分重要的信息處理領域,因為不論是推薦系統、搜索系統還是其它廣泛性應用,我們都需要借助文本挖掘的力量。本文先簡述文本挖掘包括 NLP、信息檢索和自動文本摘要等幾種主要的方法,再從文本表征、分類方法、聚類方法、信息提取方法等幾大部分概述各類機器學習算法的應用。機器之心對本論文進行簡要的概述。
論文地址:https://arxiv.org/abs/1707.02919

摘要:每天所產生的信息量正在迅猛增加,而這些信息基本都是非結構化的海量文本,它們無法輕易由計算機處理與感知。因此,我們需要一些高效的技術和算法來發現有用的模式。文本挖掘近年來頗受大眾關注,是一項從文本文件中提取有效信息的任務。本文將對一些最基本的文本挖掘任務與技術(包括文本預處理、分類以及聚類)做出闡述,此外還會簡要介紹其在生物制藥以及醫療領域的應用。
一、簡介
由于以各種形式(如社交網絡、病歷、醫療保障數據、新聞出版等)出現的文本數據數量驚人,文本挖掘(TM)近年來頗受關注。IDC 在一份報告中預測道:截至到 2020 年,數據量將會增長至 400 億 TB(4*(10^22) 字節),即從 2010 年初開始增長了 50 倍 [50]。
文本數據是典型的非結構化信息,它是在大多數情況下可產生的最簡單的數據形式之一。人類可以輕松處理與感知非結構化文本,但機器顯然很難理解。不用說,這些文本定然是信息和知識的一個寶貴來源。因此,設計出能有效處理各類應用中非結構化文本的方法就顯得便迫在眉睫。
1. 知識發現 vs 數據挖掘(略)
2. 文本挖掘方法
- 信息檢索(Information Retrieval,IR):信息檢索是從滿足信息需求的非結構化數據集合中查找信息資源(通常指文檔)的行為。
- 自然語言處理(Natural Language Processing,NLP):自然語言處理是計算機科學、人工智能和語言學的子領域,旨在通過運用計算機理解自然語言。
- 文本信息提取(Information Extraction from text,IE):信息提取是從非結構化或半結構化文檔中自動提取信息或事實的任務。
- 文本摘要:許多文本挖掘應用程序需要總結文本文檔,以便對大型文檔或某一主題的文檔集合做出簡要概述。
- 無監督學習方法(文本):無監督學習方法是嘗試從未標注文本中獲取隱藏數據結構的技術,例如使用聚類方法將相似文本分為同一類。
- 監督學習方法(文本):監督學習方法從標注訓練數據中學習分類器或推斷功能,以對未知數據執行預測的機器學習技術。
- 文本挖掘的概率方法:有許多種概率技術,包括無監督主題模型(如概率潛在語義分析模型(pLSA)[64] 與文檔主題生成模型(LDA)[16])和監督學習方法(如可在文本挖掘語境中使用的條件隨機場)[83]。
- 文本流與社交媒體挖掘:網絡上存在許多不同的應用程序,它們可以生成大量的文本數據流。
- 觀點挖掘與情感分析:隨著電子商務和網絡購物的問世,產生了大量的文本,并在不同的產品評論或用戶意見上不斷增長。
- 生物醫學文本挖掘:生物醫學文本挖掘是指對生物醫學科學領域的文本進行文本挖掘的任務。
二、文本表征和編碼
1. 文本預處理
- 標記化(Tokenization):標記化是將字符序列分解成標記(token/單詞或短語)的任務,同時它可能會去掉某些字符(如標點符號)。
- 過濾:過濾通常在文檔上完成,用于刪除某些單詞。一種常見過濾是停用詞刪除。
- 詞形還原:詞形還原是有關單詞形態分析的任務,即對單詞的各種變形形式進行分組,以便將它們作為單個項目進行分析。
- 詞干提取:詞干提取方法旨在獲取派生詞的詞干(詞根)。詞干提取算法比較依賴于語言。
2. 向量空間模型(略)
三、分類
1. 樸素貝葉斯分類器
樸素貝葉斯分類器可能會是最簡單,用途也最廣泛的分類器。在假設不同項相互獨立且服從相同分布的情況下,它通過概率模型對文檔的類別分布進行建模。樸素貝葉斯發對條件概率分布作了條件獨立性假設,由于這是一個較強的假設,樸素貝葉斯法由此得名。雖然在很多實際應用中,這種所謂的「樸素貝葉斯」的假設明顯有錯誤,但它的表現仍舊令人驚訝。
用于樸素貝葉斯分類 [94] 的通常有兩個主要模型,它們都以根據文檔中的單詞分布進而得出每一類的后驗概率為目標。
- 多變量伯努利模型:該模型中,每篇文檔會由一個二進制特征向量來表征文檔中某單詞是否存在,因而忽略了單詞出現的頻率。原論文可在 [86] 中找到。
- 多項式模型:通過將文檔表示為詞袋(Bag Of Words),因此它能夠捕捉文檔中單詞(項)出現的頻率。在 [74,95,99,104] 中則介紹了多項式模型的許多不同變體。McCallum 等人在伯努利和多項式模型之間進行了廣泛對比,并得出結論:若詞匯的數量很少,伯努利模型可能會優于多項式模型;若詞匯數量很多,多項式模型則總會優于伯努利模型;而當詞匯數量對兩種模型而言都處于***狀態時,多項式模型總會更勝一籌。
2. 最近鄰分類器
最近鄰分類器是一種基于臨近數據的分類器,并且基于距離度量來執行分類。其主要思想為,屬于同一類的文檔更可能「相似」或者基于相似度計算彼此更為接近,如在(2.2)中定義的余弦相似度。測試文檔的分類根據訓練集中相似文檔的類別標簽推斷而出。如果我們考慮訓練集中 K 個最鄰近的值為一個標簽,那么該方法被稱為 k 近鄰分類并且這 k 個鄰近值最常見的類就可以作為整個集群的類,請查看 [59, 91, 113, 122] 了解更多 K 近鄰方法。
3. 決策樹分類器
基本上說,決策樹是一種訓練樣本的層次樹,其中樣本的特征值可用于分離數據的層次,特征分離的順序一般是通過信息熵和信息增益來確定。換句話說,基于定義在每個節點或者分支的分割標準,決策樹能遞歸地將訓練數據集劃分為更小的子樹。
樹的每個節點都是對訓練樣本一些特征的判定,且從該節點往下的每個分支或子分支對應于這個特征值。從根節點開始對實例進行分類,首先需要確定信息增益***的特征并排序,然后通過該節點判定樣本是否具有某種特定的特征,并將樣本分到其以下的分支中,直到完成***一次分類到達葉節點。這個過程被遞歸性地重復 [99]。查看 [19, 40, 69, 109] 獲取決策樹的詳細信息。
決策樹已經與提升算法結合使用,例如梯度提升樹。[47,121] 討論了提高決策樹分類的準確性的增強技術。
4. 支持向量機
支持向量機(SVM)是受監督的學習分類算法,它廣泛應用于文本分類問題中。不帶核函數的支持向量機是線性分類器的一種形式。在文本文檔中,線性分類器是一種線性結合文檔特征而做出分類決策的模型。因此,線性預測的輸出可定義為 y = a · x + b,其中 x = (x1, x2, . . . , xn) 是歸一化的文檔詞頻向量,a = (a1, a2, . . . , an) 是系數向量,b 是標量。我們可以將類別分類標簽中的預測器 y = a · x + b 可理解為不同類別中的分離超平面,不帶核函數的硬間隔支持向量機只能分割線性可分數據。
支持向量機最初在 [34, 137] 被引入。支持向量機嘗試在不同的類中找到一個「不錯的」線性分離器 [34, 138]。一個單獨的支持向量機只能分離兩個類別,即正類和負類 [65]。支持向量機試圖找到離正樣本和負樣本間有***距離 ξ(也被稱為***間隔)的超平面。而確定超平面與樣本見距離 ξ 的文檔被稱為支持向量,支持向量實際上指定了超平面的實際位置。如果兩類文檔不是線性可分的,那么一定有樣本是超平面分類錯誤的。這種線性不可分的數據是無法使用線性支持向量機的,而支持向量機的強大之處在于它的核函數,軟間隔支持向量機應用核函數就能夠成為十分強大的非線性分類器,并且擁有極其強大的魯棒性。
四、聚類
文本聚類算法被分為很多不同的種類,比如凝聚聚類算法(agglomerative clustering algorithm)、分割算法(partitioning algorithm)和概率聚類算法。
1. 層次聚類算法
層次聚類算法構建了一組可被描述為層級集群的類。層級可以自上而下(被稱為分裂)或者自下而上(被稱為凝聚)的方式構建。層次聚類算法是一種基于距離的聚類算法,即使用相似函數計算文本文檔之間的緊密度。關于層次聚類算法文本數據的完整描述在 [101, 102, 140] 可以找到。
2. K 均值聚類
K 均值聚類是一種在數據挖掘中被廣泛使用的分割算法。k 均值聚類根據文本數據的語境將 n 個文檔劃分為 k 組。屬于某一類典型數據則圍繞在所構建的群集群中心周圍。k 均值聚類算法的基本形式如下:

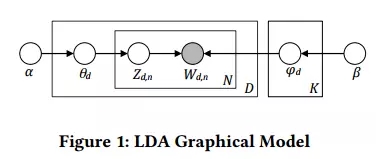
3. 概率聚類和主題模型
主題建模是***的一種概率聚類算法,近來受到廣泛關注。主題建模 [16, 53, 64] 的主要思想是為文本文檔的語料構建概率生成模型。在主題模型中,文檔是主題的混合體,而主題則是單詞的概率分布。
兩種主要的主題模型分別為:概率潛在語義分析(Probabilistic Latent Semantic Analysis/pLSA)[64] 和隱狄利克雷分布(LDA))[16]。pLSA 模型在文檔層面不提供任何概率模型,這使得很難泛化到新的沒見過的文檔。
隱狄利克雷分配模型是***的無監督技術,用于提取所收集文檔的專題信息(主題)[16, 54]。其基礎思想為文檔是潛在主題的隨機混合,每個主題為單詞的概率分布。
五、信息提取
信息提取(IE)是一種自動從非結構化或者半結構化文本中提取結構化信息的任務。換句話說,信息提取可被視做為一種完全自然語言理解的有限形式,其中我們會提前了解想要尋找的信息。
1. 命名實體識別(NER)
命名的實體是一個單詞序列,其可以識別一些現實實體,比如「谷歌公司(Google Inc)」、「美利堅合眾國(United States)」、「巴拉克奧巴馬(Barack Obama)」。命名實體識別的任務是在自定義文本中將找出命名實體的位置并將其區分為預先定義的類別(如人、組織、位置等)。NER 不能像字典一樣簡單地做一些字符串的匹配工作就行,因為 a) 字典通常是不全的且不會包含給定的實體類型的命名實體的所有形式。b) 命名實體經常取決于其語境,比如「大蘋果(big apple)」可以是一種水果,也可以是紐約的綽號。
2. 隱馬爾可夫模型
隱馬爾可夫模型假定產生標簽(狀態)或者觀察的馬爾可夫過程取決于一個或者多個之前的標簽(狀態)或者觀察。因此對于一個觀察序列 X = (x1, x2, . . . , xn),給定一個標簽序列 Y = (y1,y2, . . . ,yn),我們有
![]()
隱馬爾可夫模型已經成功地被用于命名實體識別任務和語音識別系統中。隱馬爾可夫的完整描述請查看 [110]。
3. 條件隨機場
條件隨機場(CRFs)是序列標注的概率模型。CRF 由 Lafferty 等人***引入。我們在如下的觀察(未被標注的數據序列)和 Y(標簽序列)中提到了與 [83] 中條件隨機場的相同概念。
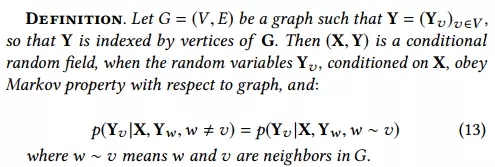
條件隨機場被廣泛用于信息提取和部分的語音標注任務中 [83]。
七、討論
在本文中,我們不僅嘗試對文本挖掘領域做一個簡短的介紹,同時我們對一些在該領域廣泛使用的基礎算法和技術做了一個概述。雖然本文主要從發展和脈絡上對文本挖掘領域進行大概的綜述,并且也很難更細致地描述這些算法或方法,但本文提供了大量的相關論文資源,希望能對想深入了解這一領域的讀者提供擴展。
【本文是51CTO專欄機構“機器之心”的原創譯文,微信公眾號“機器之心( id: almosthuman2014)”】