近幾年來,興起了一股人工智能熱潮,讓人們見到了AI的能力和強大,比如圖像識別,語音識別,機器翻譯,無人駕駛等等。總體來說,AI的門檻還是比較高,不僅要學會使用框架實現,更重要的是,需要有一定的數學基礎,如線性代數,矩陣,微積分等。
幸慶的是,國內外許多大神都已經給我們造好“輪子”,我們可以直接來使用某些模型。今天就和大家交流下如何實現一個簡易版的人臉對比,非常有趣!
整體思路:
- 預先導入所需要的人臉識別模型
- 遍歷循環識別文件夾里面的圖片,讓模型“記住”人物的樣子
- 輸入一張新的圖像,與前一步文件夾里面的圖片比對,返回最接近的結果
使用到的第三方模塊和模型:
模塊:os,dlib,glob,numpy
模型:人臉關鍵點檢測器,人臉識別模型
1.導入需要的模塊和模型
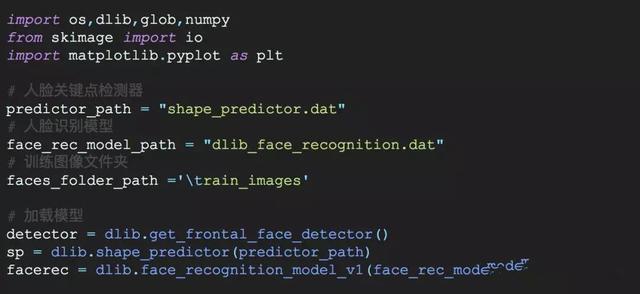
這里解釋一下兩個dat文件:
它們的本質是參數值(即神經網絡的權重)。人臉識別算是深度學習的一個應用,事先需要經過大量的人臉圖像來訓練。所以一開始我們需要去設計一個神經網絡結構,來“記住”人類的臉。
對于神經網絡來說,即便是同樣的結構,不同的參數也會導致識別的東西不一樣。在這里,這兩個參數文件就對應了不同的功能(它們對應的神經網絡結構也不同):
shape_predictor.dat這個是為了檢測人臉的關鍵點,比如眼睛,嘴巴等等;dlib_face_recognition.dat是在前面檢測關鍵點的基礎上,生成人臉的特征值。
所以后面使用dlib模塊的時候,其實就是相當于,調用了某個神經網絡結構,再把預先訓練好的參數傳給我們調用的神經網絡。順便提一下,在深度學習領域中,往往動不動會訓練出一個上百M的參數模型出來,是很正常的事。
2.對訓練集進行識別
在這一步中,我們要完成的是,對圖片文件夾里面的人物圖像,計算他們的人臉特征,并放到一個列表里面,為了后面可以和新的圖像進行一個距離計算。關鍵地方會加上注釋,應該不難理解,具體實現為:
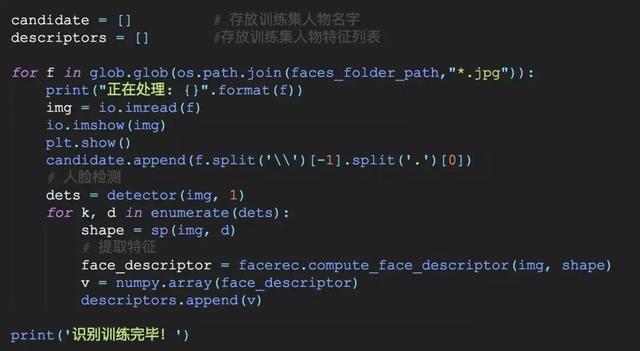
當你做完這一步之后,輸出列表descriptors看一下,可以看到類似這樣的數組,每一個數組代表的就是每一張圖片的特征量(128維)。然后我們可以使用L2范式(歐式距離),來計算兩者間的距離。
舉個例子,比如經過計算后,A的特征值是[x1,x2,x3],B的特征值是[y1,y2,y3], C的特征值是[z1,z2,z3],
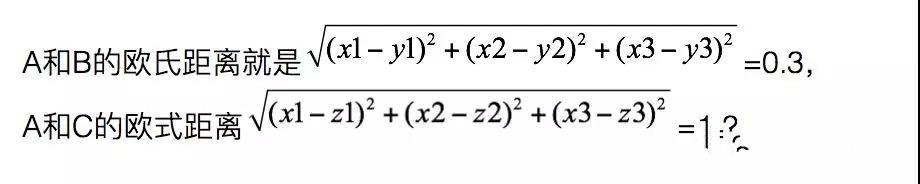
那么由于A和B更接近,所以會認為A和B更像。想象一下極端情況,如果是同一個人的兩張不同照片,那么它們的特征值是不是應該會幾乎接近呢?知道了這一點,就可以繼續往下走了。

3.處理待對比的圖片
其實是同樣的道理,如法炮制,目的就是算出一個特征值出來,所以和第二步差不多。然后再順便計算出新圖片和第二步中每一張圖片的距離,再合成一個字典類型,排個序,選出最小值,搞定收工!
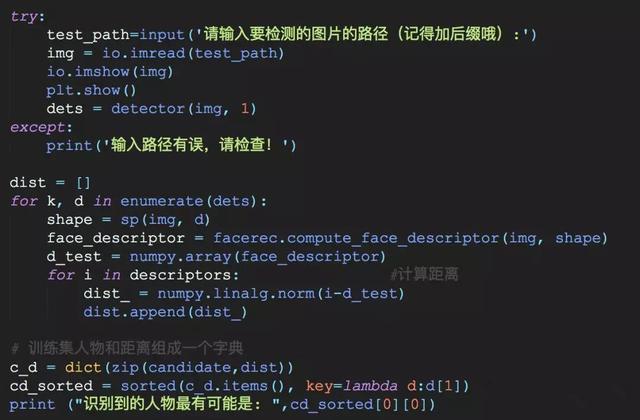
4.運行看一下
這里我用了一張“斷水流大師兄”林國斌的照片,識別的結果是,果然,是最接近黎明了(嘻嘻,我愛黎明)。但如果你事先在訓練圖像集里面有放入林國斌的照片,那么出來的結果就是林國斌了。

為什么是黎明呢?我們看一下輸入圖片里的人物***與每個明星的距離,輸出打印一下:
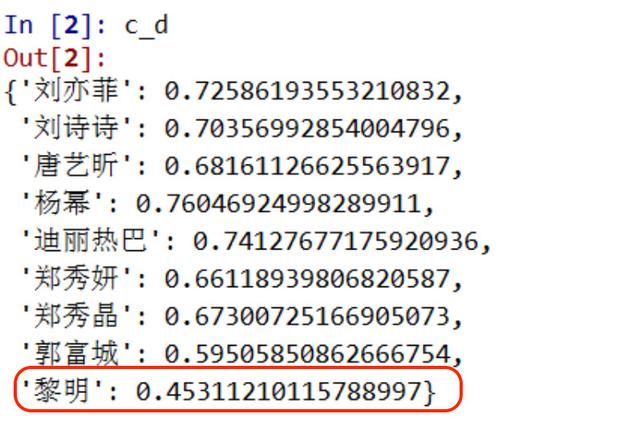
沒錯,他和黎明的距離是最小的,所以和他也最像了!