Python自動化之數據驅動,讓你的腳本簡潔10倍
前言
數據驅動是一種思想,讓數據和代碼進行分離,比如爬蟲時,我們需要分頁爬取數據時,我們往往把頁數 page 參數化,放在 for 循環 range 中,假如沒有 range 這個自帶可以生產數字序列的方法可以用,我們是不是得手動逐個添加?
現實場景中就存在大量這樣的例子,比如我之前寫的爬取上海各地區房租情況的時候,對地區進行遍歷的時候,為了偷懶,我直接把這些地區的拼音全稱放在了列表里,組合成各地區房源的鏈接。***文章寫完了,有讀者反饋,少了徐匯區的統計數據。這種小數量的數據都出現了紕漏,可想而知,對于大量的數據,怎么保證數據的完整和準確性?我們需要把兩者分離,數據專門儲存在特定文件(比如 Excel 文件)。
舉一個小栗子:登錄流程,在測試的時候,除了測試登錄成功的場景,我們往往需要測到各種登錄異常的場景。
寫幾條很常見的案例如下:
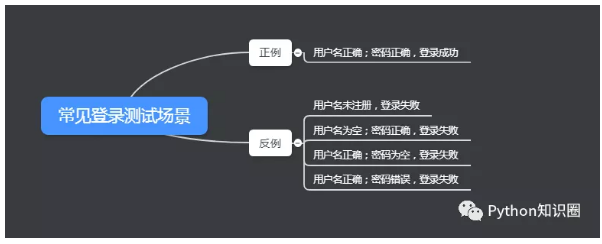
比如上面寫了 5 條案例,數據和腳本不做分離的話,我們寫自動化測試腳本需要寫 5 條。

5 條案例中,腳本都是基本一樣的,只是輸入框輸入的數據不一樣罷了。
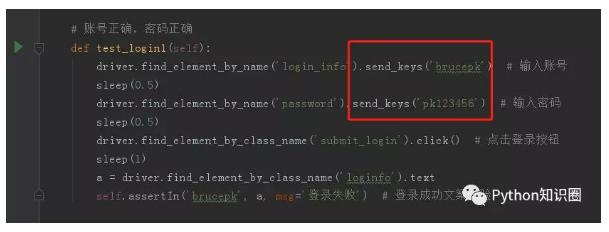
數據分離
我們完全可以把數據存儲在 Excel 表中,我們通過循環讀取 Excel 表中的數據來實現一條腳本執行多條數據。
我們先封裝一個操作 Excel 文件的類,需要先安裝導入包 openpyxl。
我們用這個庫可以做一下功能:讀取表格數據、保存執行結果。
我們先在類下寫一個打開 Excel 文件的初始化方法,構造方法的作用是,當類被實例化后,會立即調用構造方法。

讀取表格數據
然后我們寫一個讀取 Excel 數據的方法,讀取數據后返回數據列表,以便之后調用獲取對應的數據,因為第 1 列數據是序號,所以直接返回第 2 列之后的數據。

保存執行結果
實際結果和預期結果對比后,我們需要標記執行結果是 pass 或者 fail,我們需要保存結果,保存到對應的單元格中。

我們看看我們的案例格式:
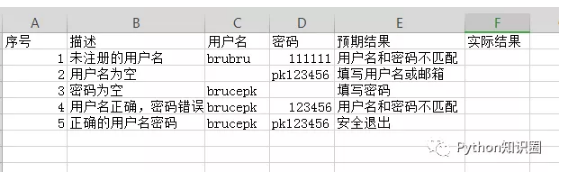
這樣的話,我們腳本就不用寫 5 條了,調用 Excel 文件的數據,循環執行案例即可,不僅邏輯清晰,還方便了后期的維護。
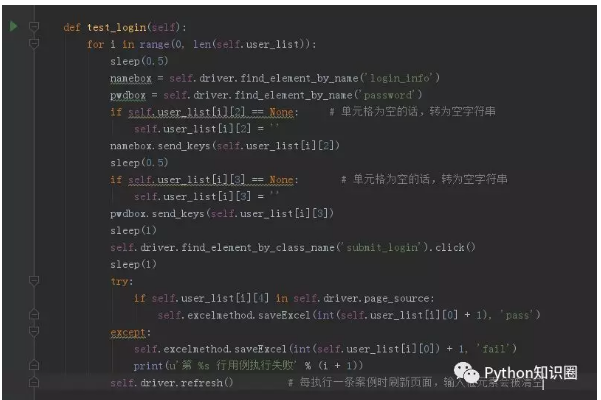
這樣,測試數據和腳本分離后,不同的測試數據用不同的 Excel 文件保存即可。
吃飯時或者下班時執行下測試腳本,吃完飯后或者第二天上班時,查看下 Excel 里的執行結果,有 fail 再手動看看能否復現,是不是很高效?