













數據不夠,Waymo用GAN來湊:用生成圖像在仿真環境中訓練模型
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
疫情當下,Waymo等自動駕駛廠商暫時不能在現實世界的公共道路上進行訓練、測試了。
不過,工程師們還可以在GTA(劃掉),啊不,在仿真環境里接著跑車。

模擬環境里的場景、對象、傳感器反饋通常是用虛幻引擎或者Unity這樣的游戲引擎來創建的。
為了實現逼真的激光雷達等傳感器建模,就需要大量的手動操作,想要獲得足夠多、足夠復雜的數據,可得多費不少功夫。
數據不夠,無人車標桿Waymo決定用GAN來湊。
這只GAN,名叫SurfelGAN,能基于無人車收集到的有限的激光雷達和攝像頭數據,生成逼真的相機圖像。
用GAN生成的數據訓練,還是訓練自動駕駛汽車,這到底靠譜不靠譜?
SurfelGAN
那么首先,一起來看看SurfelGAN是怎樣煉成的。
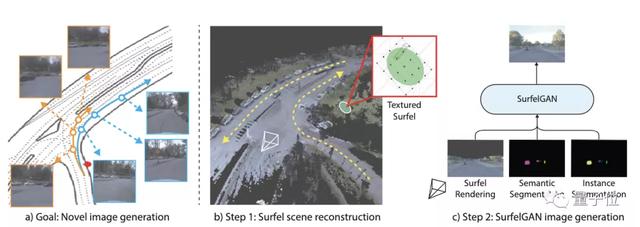
主要有兩個步驟:
首先,掃描目標環境,重建一個由大量有紋理的表面元素(Surfel)構成的場景。
然后,用相機軌跡對表面元素進行渲染,同時進行語義和實例分割。接著,通過GAN生成逼真的相機圖像。
表面元素場景重建
為了忠實保留傳感器信息,同時在計算和存儲方面保持高效,研究人員提出了紋理增強表面元素地圖表示方法。
表面元素(surface element,縮寫Surfel)適用于動態幾何建模,一個對象由一組密集的點或帶有光照信息的面元來表示。
研究人員將激光雷達掃描捕獲的體素,轉換為具有顏色的表面元素,并使其離散成 k×k 的網格。
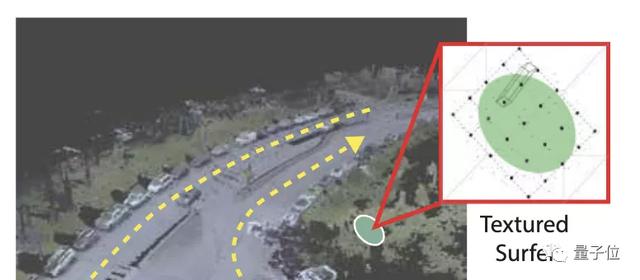
由于光照條件的不同和相機相對姿勢(距離和視角)的變化,每個表面元素在不同的幀中可能會有不同的外觀,研究人員提出,通過創建一個由 n 個不同距離的 k×k 網格組成的編碼簿,來增強表面元素表示。
在渲染階段,該方法根據相機姿勢來決定使用哪一個 k×k 塊。

圖中第二行,即為該方法的最終渲染效果。可以看到,與第一行基線方法相比,紋理增強表面元素圖消除了很多偽影,更接近于第三行中的真實圖像。
為了處理諸如車輛之類的動態對象,SurfelGAN還采用了Waymo開放數據集中的注釋。來自目標對象的激光雷達掃描的數據會被積累下來,這樣,在模擬環境中,就可以在任意位置完成車輛、行人的重建。
通過SurfelGAN合成圖像
完成上面的步驟,模擬場景仍存在幾何形狀和紋理不完美的問題。
這時候,GAN模塊就上場了。
訓練設置了兩個對稱的編碼-解碼生成器,從Sufel圖像到真實圖像的GS→I,以及反過來從真實圖像到Sufel圖像的GI→S。同樣也有兩個判別器,分別針對Sufel域和真實域。
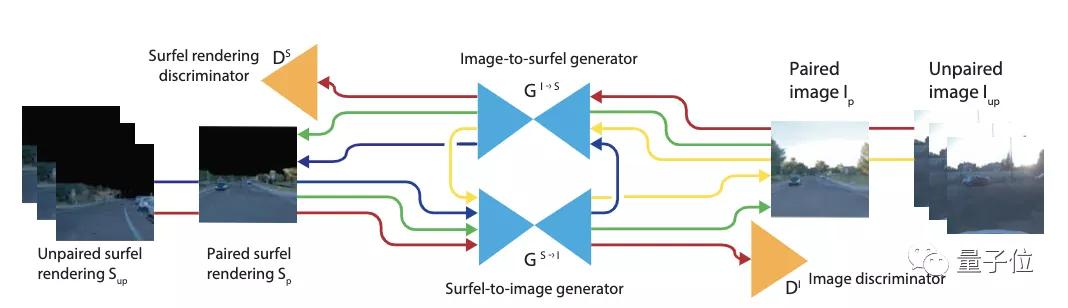
上圖中,綠色的線代表有監督重建損失,紅色的線代表對抗損失,藍線/黃線為周期一致性損失。
輸入數據包括配對數據和未配對數據。其中,未配對數據用來實現兩個目的:
- 提高判別器的泛化性能;
- 通過強制循環一致性來規范生成器。
另外,由于表面元素圖像的覆蓋范圍有限,渲染出的圖像中包含了大面積的未知區域,并且,相機和表面元素之間的距離也引入了另一個不確定因素,研究人員采用了距離加權損失來穩定GAN的訓練。
具體而言,在數據預處理過程中,先生成一個距離圖,然后利用距離信息作為加權稀疏,對重構損失進行調節。
實驗結果
最后,效果如何,還是要看看實驗結果。
研究人員們基于Waymo Open Dataset(WOD)進行了實驗。該數據集包括798個訓練序列,和202個驗證序列。每個序列包含20秒的攝像頭數據和激光雷達數據。此外,還包括WOD中真的對車輛、行人的注釋。
他們還從WOD中衍生出了一個新的數據集——Waymo Open Dataset-Novel View。在這個數據集中,根據相機擾動姿勢,研究人員為原始數據集里的每一幀創建了新的表面元素渲染。
此外,還有9800個100幀短序列,用于真實圖像的無配對訓練。以及雙攝像頭-姿勢數據集(DCP),用于測試模型的真實性。

可以看到,在檢測器的鑒定下,SurfelGAN生成的最高質量圖像將AP@50從52.1%拉升到了62.0%,與真實圖像的61.9%持平。

Waymo認為,這樣的結果為將來的動態對象建模和視頻生成模擬系統奠定了堅實的基礎。
華人一作
論文的第一作者,是Waymo的華人實習生Zhenpei Yang,他于2019年6月至8月間在Waymo完成了這項研究。
Zhenpei Yang本科畢業于清華大學自動化系,目前在德州大學奧斯汀分校攻讀博士,研究方向是3D視覺和深度學習。
Waymo首席科學家Dragomir Anguelov,也是論文的作者之一。






















