這5個Python庫太難搞!每位數(shù)據(jù)科學(xué)家都應(yīng)該了解
本文轉(zhuǎn)載自公眾號“讀芯術(shù)”(ID:AI_Discovery)。
Python之所以能成為世界上最受歡迎的編程語言之一,與其整體及其相關(guān)庫的生態(tài)系統(tǒng)密不可分,這些強(qiáng)大的庫讓Python保持著生命力和高效力。作為數(shù)據(jù)科學(xué)家免不了會使用一些Python庫用于項(xiàng)目和研究,除卻那些常見的庫,還有很多庫能夠增強(qiáng)你的數(shù)據(jù)科學(xué)研究能力。
本文將介紹五大難懂的Python庫,理解起來并不容易,但搞定它們你就能功力大增!
1. Scrapy
每位數(shù)據(jù)科學(xué)家的項(xiàng)目都是從處理數(shù)據(jù)開始的,而互聯(lián)網(wǎng)就是最大、最豐富、最易訪問的數(shù)據(jù)庫。但可惜的是,除了通過pd.read_html函數(shù)來獲取數(shù)據(jù)時,一旦涉及從那些數(shù)據(jù)結(jié)構(gòu)復(fù)雜的網(wǎng)站上抓取數(shù)據(jù),數(shù)據(jù)科學(xué)家們大多都會毫無頭緒。
Web爬蟲常用于分析網(wǎng)站結(jié)構(gòu)和存儲提取信息,但相較于重新構(gòu)建網(wǎng)頁爬蟲,Scrapy使這個過程變得更加容易。
Scrapy用戶界面非常簡潔使用感極佳,但其最大優(yōu)勢還得是效率高。Scrapy可以異步發(fā)送、調(diào)度和處理網(wǎng)站請求,也就是說:它在花時間處理和完成一個請求的同時,也可以發(fā)送另一個請求。Scrapy通過同時向一個網(wǎng)站發(fā)送多個請求的方法,使用非常快的爬行,以最高效的方式迭代網(wǎng)站內(nèi)容。
除上述優(yōu)點(diǎn)外,Scrapy還能讓數(shù)據(jù)科學(xué)家用不同的格式(如:JSON,CSV或XML)和不同的后端(如:FTP,S3或local)導(dǎo)出存檔數(shù)據(jù)。
圖源:unsplash
2. Statsmodels
到底該采用何種統(tǒng)計建模方法?每位數(shù)據(jù)科學(xué)家都曾對此猶豫不決,但Statsmodels是其中必須得了解的一個選項(xiàng),它能實(shí)現(xiàn)Sci-kit Learn等標(biāo)準(zhǔn)機(jī)器學(xué)習(xí)庫中沒有的重要算法(如:ANOVA和ARIMA),而它最有價值之處在于其細(xì)節(jié)化處理和信息化應(yīng)用。
例如,當(dāng)數(shù)據(jù)科學(xué)家要用Statsmodels算一個普通最小二乘法時,他所需要的一切信息,不論是有用的度量標(biāo)準(zhǔn),還是關(guān)于系數(shù)的詳細(xì)信息,Statsmodels都能提供。庫中實(shí)現(xiàn)的其他所有模型也是如此,這些是在Sci-kit learn中無法得到的。
- OLSRegressionResults
- ==============================================================================
- Dep. Variable: Lottery R-squared: 0.348
- Model: OLS Adj. R-squared: 0.333
- Method: LeastSquares F-statistic: 22.20
- Date: Fri, 21Feb2020 Prob (F-statistic): 1.90e-08
- Time: 13:59:15 Log-Likelihood: -379.82
- No. Observations: 86 AIC: 765.6
- DfResiduals: 83 BIC: 773.0
- DfModel: 2
- CovarianceType: nonrobust
- ===================================================================================
- coef std err t P>|t| [0.025 0.975]
- -----------------------------------------------------------------------------------
- Intercept 246.4341 35.233 6.995 0.000 176.358 316.510
- Literacy -0.4889 0.128 -3.832 0.000 -0.743 -0.235
- np.log(Pop1831) -31.3114 5.977 -5.239 0.000 -43.199 -19.424
- ==============================================================================
- Omnibus: 3.713 Durbin-Watson: 2.019
- Prob(Omnibus): 0.156 Jarque-Bera (JB): 3.394
- Skew: -0.487 Prob(JB): 0.183
- Kurtosis: 3.003 Cond. No. 702.
- ==============================================================================
對于數(shù)據(jù)科學(xué)家來說,掌握這些信息意義重大,但他們的問題是常常太過信任一個自己并不真正理解的模型。因?yàn)楦呔S數(shù)據(jù)不夠直觀,所以在部署這些數(shù)據(jù)之前,數(shù)據(jù)科學(xué)家有必要深入了解數(shù)據(jù)與模型。如果盲目追求像準(zhǔn)確度或均方誤差之類的性能指標(biāo),可能會造成嚴(yán)重的負(fù)面影響。
Statsmodels不僅具有極其詳細(xì)的統(tǒng)計建模,而且還能提供各種有用的數(shù)據(jù)特性和度量。例如,數(shù)據(jù)科學(xué)家們常會進(jìn)行時序分解,它可以幫助他們更好地理解數(shù)據(jù),以及分析何種轉(zhuǎn)換和算法更為合適,或者也可以將pinguoin用于一個不太復(fù)雜但非常精確的統(tǒng)計函數(shù)。
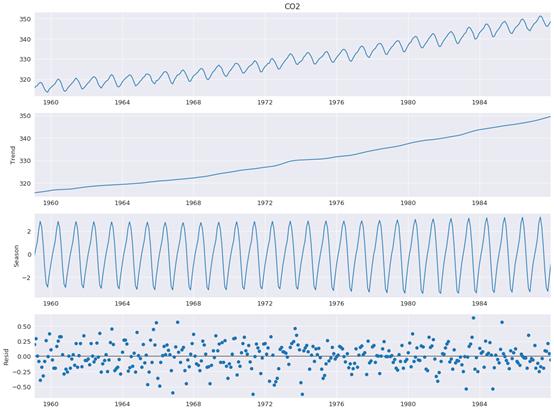
圖源:Statsmodels
3. Pattern
一些成熟完善的網(wǎng)站用來檢索數(shù)據(jù)的方法可能更為具體,在這種情況下用Scrapy編寫Web爬蟲就有點(diǎn)“大材小用”了,而Pattern就是Python中更高級的Web數(shù)據(jù)挖掘和自然語言處理模塊。
Pattern不僅能無縫整合谷歌、推特和維基百科三者的數(shù)據(jù),而且還能提供一個不太個性化的Web爬蟲和HTML DOM解析器。它采用了詞性標(biāo)注、n-grams搜索、情感分析和WordNet。不論是聚類分析,還是分類處理,又或是網(wǎng)絡(luò)分析可視化,經(jīng)Pattern預(yù)處理后的文本數(shù)據(jù)都可用于各種機(jī)器學(xué)習(xí)算法。
從數(shù)據(jù)檢索到預(yù)處理,再到建模和可視化,Pattern可以處理數(shù)據(jù)科學(xué)流程中的一切問題,而且它也能在不同的庫中快速傳輸數(shù)據(jù)。
圖源:unsplash
4. Mlxtend
Mlxtend是一個任何數(shù)據(jù)科學(xué)項(xiàng)目都可以應(yīng)用的庫。它可以說是Sci-kit learn庫的擴(kuò)展,能自動優(yōu)化常見的數(shù)據(jù)科學(xué)任務(wù):
- 全自動提取與選擇特征。
- 擴(kuò)展Sci-kit learn庫現(xiàn)有的數(shù)據(jù)轉(zhuǎn)換器,如中心化處理和事務(wù)編碼器。
- 大量的評估指標(biāo):包括偏差方差分解(即測量模型中的偏差和方差)、特征點(diǎn)檢測、McNemar測試、F測試等。
- 模型可視化,包括特征邊界、學(xué)習(xí)曲線、PCA交互圈和富集圖繪。
- 含有許多Sci-kit Learn庫中沒有的內(nèi)置數(shù)據(jù)集。
- 圖像與文本預(yù)處理功能,如名稱泛化器,可以識別并轉(zhuǎn)換具有不同命名系統(tǒng)的文本(如:它能識別“Deer,John”,“J.Deer”,“J.D.”和“John Deer”是相同的)。
Mlxtend還有非常實(shí)用的圖像處理功能,比如它可以提取面部標(biāo)志:
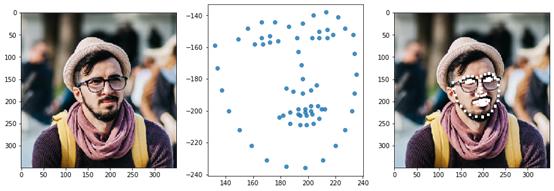
圖源:Mlxtend
再來看看它的決策邊界繪制功能:
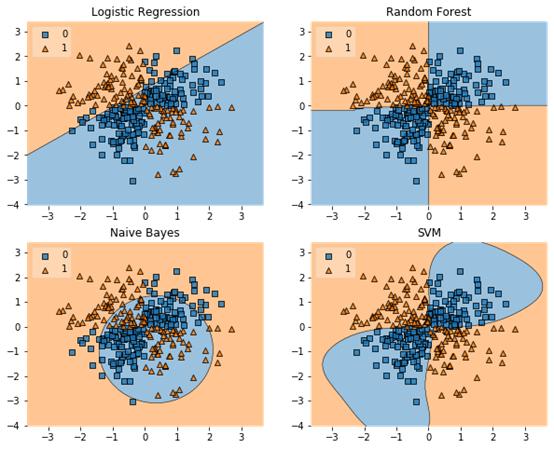
圖源:Mlxtend
5. REP
與Mlxtend一樣,REP也可以被看作是Sci-kit學(xué)習(xí)庫的擴(kuò)展,但更多的是在機(jī)器學(xué)習(xí)領(lǐng)域。首先,它是一個統(tǒng)一的Python包裝器,用于從Sci-kit-learn擴(kuò)展而來的不同機(jī)器學(xué)習(xí)庫。它可以將Sci-kit learn與XGBoost、Pybrain、Neurolab等更專業(yè)的機(jī)器學(xué)習(xí)庫整合在一起。
例如,當(dāng)數(shù)據(jù)科學(xué)家想要通過一個簡單的包裝器將XGBoost分類器轉(zhuǎn)換為Bagging分類器,再將其轉(zhuǎn)換為Sci-kit-learn模型時,只有REP能做到,因?yàn)樵谄渌麕熘袩o法找到像這種易于包裝和轉(zhuǎn)換的算法。
- from sklearn.ensemble importBaggingClassifier
- from rep.estimators importXGBoostClassifier, SklearnClassifier
- clf =BaggingClassifier(base_estimator=XGBoostClassifier(), n_estimators=10)
- clf =SklearnClassifier(clf)
除此之外,REP還能實(shí)現(xiàn)將模型從任何庫轉(zhuǎn)換為交叉驗(yàn)證(折疊)和堆疊模型。它有一個極快的網(wǎng)格搜索功能和模型工廠,可以幫助數(shù)據(jù)科學(xué)家在同一個數(shù)據(jù)集里有效地使用多個機(jī)器學(xué)習(xí)分類器。同時使用REP和Sci-kit learn,能幫助我們更輕松自如地構(gòu)建模型。
圖源:unsplash
這五個Python庫絕對你為它付出時間!