













「算法與數據結構」帶你看分治算法之美
前言
這次分享的內容是,經典算法思想-分治,你可以把它稱之為一種思想,也可以叫它分治算法,為了更好的區分,接下來我們以'分治法'來稱呼它。
如果你還不了解什么是分治法,或者知道一些,但是對于它具體是如何實現回溯,那么這篇文章可能適合你閱讀。
我對分治算法的理解:
- 它的基本思想是將一個規模為N的問題分解為K個規模較小的子問題,這些子問題相互獨立且與原問題性質相同。
- 求出子問題的解,就可得到原問題的解,可以理解成一種分目標完成程序的算法。
- 二分法很多時候,就是一種分治的思想。
那么圍繞以下幾個點來展開介紹分治算法👇
- 基本思路
- 適用情況以及求解哪些經典問題
- 經典例題
分治法基本思想
一句話,對分治法概括它的話👇
將原問題劃分成n個規模較小而結構與原問題相似的子問題,遞歸去解決這些子問題,然后依次再合并其結果,最后得到原問題的解。
那么具體的來說,我們似乎可以分成三個步驟👇
- 分解:將要解決的問題劃分成若干規模較小的同類問題。
- 解決:當子問題劃分得足夠小時,用較簡單的方法解決。
- 合并:按原問題的要求,將子問題的解逐層合并構成原問題的解。
其實思想還是不變的,將一個難以直接解決的大問題,分割成一些小規模的相同問題,以便各個擊破,分而治之。
分治法適用情況
利用分治法求解一個問題,在于我們能否掌握分治法的幾個特征:
- 把一個問題可以縮小到一定程度,變成更小的問題來解決。
- 分解成若干個小問題后,規模更小且是同類問題,這樣子的話,該問題應該就是最優子結構。
- 利用該問題分解出來的子問題的解,合并為該問題的解。
- 分解出來的各個子問題是相互獨立的,即子問題之間不包含公共的子問題。
那我們來說一說這幾個特征吧~
第一條特征:一個問題的計算復雜性一般是隨問題的規模增加而增加的,所以絕大多數問題都滿足。
第二條特征:應用分治法的前提是得滿足它,你可以理解成它某種程度上反映了遞歸思想的應用。
第三條特征:這個應該就是分治法的關鍵了吧,能否利用分治法完全取決于問題是否具有第三條特征,如果具備了第一條和第二條特征,而不具備第三條特征,則可以考慮用貪心法或動態規劃法。
第四條特征:涉及到分治法的效率,如果各子問題是不獨立的則分治法要做許多不必要的工作,重復地解公共的子問題,此時雖然可用分治法,但一般用動態規劃法較好。
了解分治法的特征,我們來看看有哪些經典的問題是利用這個思想來解決問題的👇
分治法求解經典問題
什么情況下,可以用該思路來求解呢,以下來自網上搜集的內容👇
(1)二分搜索
(2)大整數乘法
(3)Strassen矩陣乘法
(4)棋盤覆蓋
(5)合并排序
(6)快速排序
(7)線性時間選擇
(8)最接近點對問題
(9)循環賽日程表
(10)漢諾塔
我想提起的是合并(歸并)排序,它完成照應分治法的思想,分解大問題,解決各個規模小問題,最后合并,那我們來看看合并(歸并)排序代碼👇
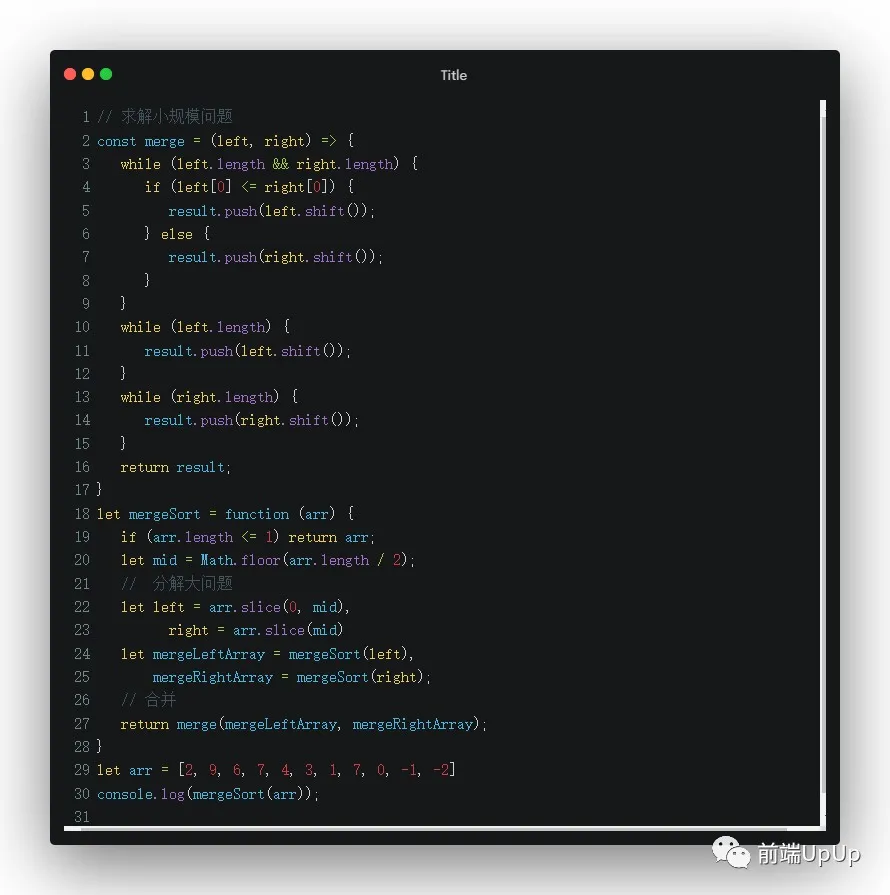
歸并排序
對于歸并排序的思路,是如何實現的,之前的排序一章以及提及過,采用的是分治思路,可以看看是如何實現的,這里就不具體展開了。
2個例子
接下來,我們通過三個題目作為例子,來看看怎么利用分治的思想來解決問題👇
最大子序和⭐
鏈接:最大子序和
給定一個整數數組 nums ,找到一個具有最大和的連續子數組(子數組最少包含一個元素),返回其最大和。
示例:
輸入: [-2,1,-3,4,-1,2,1,-5,4] 輸出: 6
解釋: 連續子數組 [4,-1,2,1] 的和最大,為 6。
進階:
如果你已經實現復雜度為 O(n) 的解法,嘗試使用更為精妙的分治法求解。
來源:力扣(LeetCode) 鏈接:https://leetcode-cn.com/problems/maximum-subarray 著作權歸領扣網絡所有。商業轉載請聯系官方授權,非商業轉載請注明出處。
首先,我們看看能不能以O(n)復雜度解決這個問題,其實仔細想一想的話,我們可以通過一個簡單
更多得是,我們這題嘗試一下用分治法來解決這題。對于一個數組的最大子序和,它對答案的貢獻,只能是以下幾種情況👇
- 出現在左半邊
- 出現在右半邊
- 出現在中間,穿過中間。
那么我們是不是可以遞歸處理呢,對于出現在左邊和出現在右邊的答案,我們可以把它們當作是一種情況,然后遞歸去處理,當然了遞歸的出口,很顯然,當遞歸的數組的長度為1時,我們需要遞歸結束。
對于出現在中間答案的情況,我們可以通過計算來算出答案,所以思路理清楚, 接下來,我們看如何寫👇
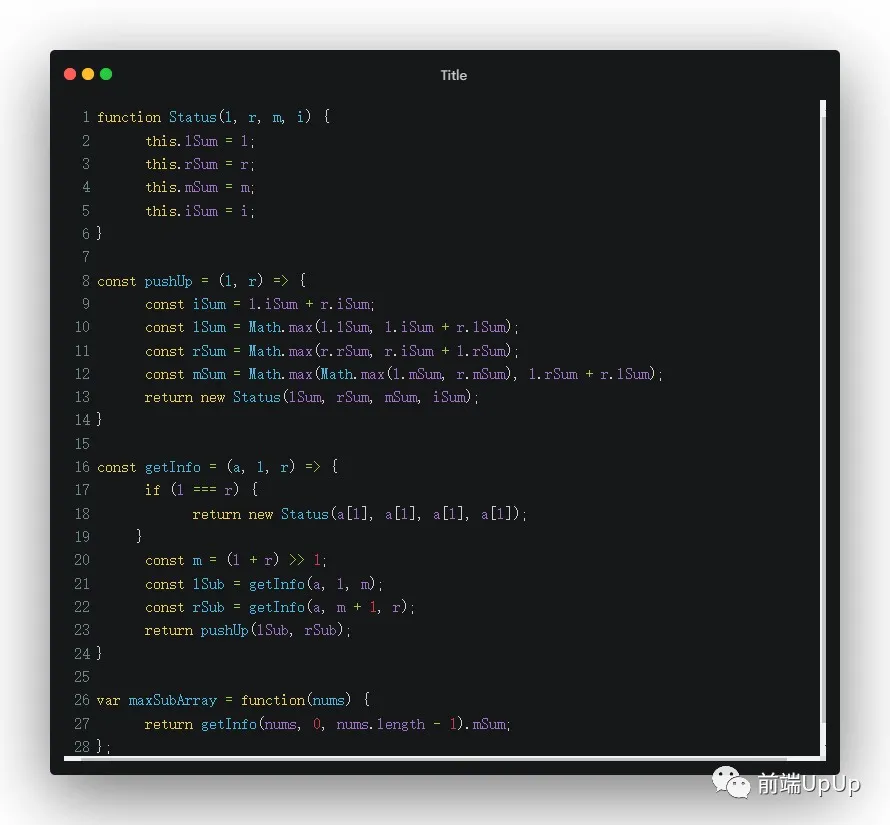
分治法連續最大和
當然了,這題用動態規劃思路更好求解,也更加得好理解👇
- //dp[i]表示nums中以nums[i]結尾的最大子序和
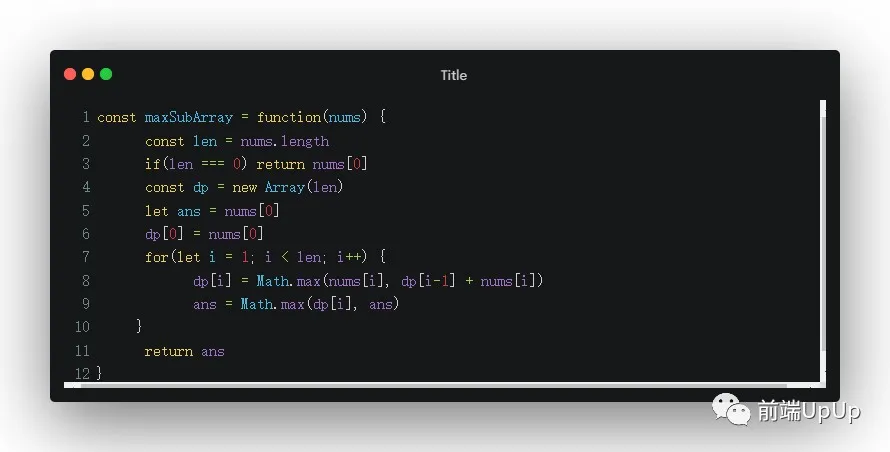
動態規劃求連續和
代碼點這里☑️
搜索二維矩陣 II⭐⭐
鏈接:搜索二維矩陣 II
編寫一個高效的算法來搜索 m x n 矩陣 matrix 中的一個目標值 target。該矩陣具有以下特性:
每行的元素從左到右升序排列。每列的元素從上到下升序排列。示例:
現有矩陣 matrix 如下:
- [ [1, 4, 7, 11, 15], [2, 5, 8, 12, 19], [3, 6, 9, 16, 22], [10, 13, 14, 17, 24], [18, 21, 23, 26, 30] ]
給定 target = 5,返回 true。
給定 target = 20,返回 false。
來源:力扣(LeetCode) 鏈接:https://leetcode-cn.com/problems/search-a-2d-matrix-ii 著作權歸領扣網絡所有。商業轉載請聯系官方授權,非商業轉載請注明出處。
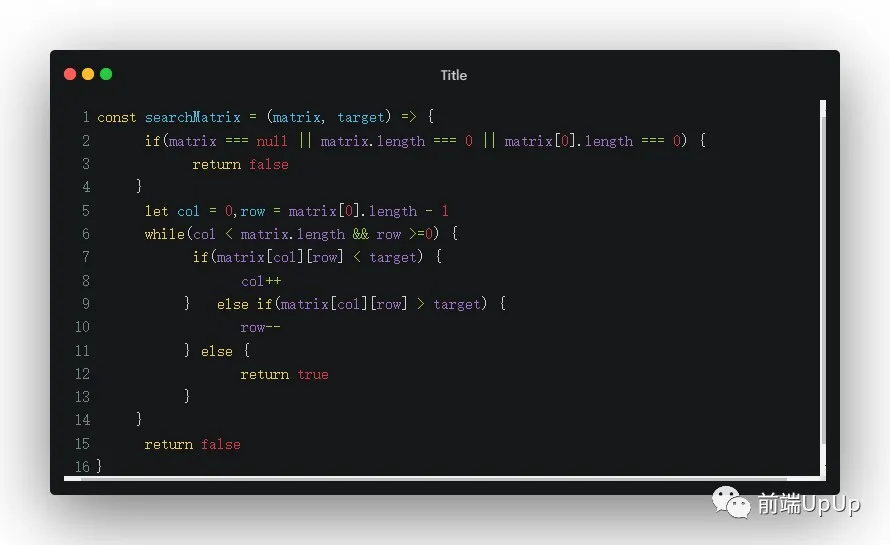
這題的題目很清晰👉矩陣的每行從左到右是升序, 每列從上到下也是升序,在矩陣中查找某個數。
當然了,我們有一個簡單的思路👇
- 維護兩個指針(row,col),找到目標元素時,我們就放回true
- 當指向當前的元素值小于target時,我們就col++,向上移動一行。
- 如果當前的值大于當前的target,我們就row--,向左移動一列。
- 知道col > 矩陣的行,或者row < 0時,我們直接return false,表示不存在。
時間復雜度:O(n+m)
- 時間復雜度分析的關鍵是注意到在每次迭代(我們不返回 true)時,行或列都會精確地遞減/遞增一次。
- 由于行只能減少 m 次,而列只能增加 n次,因此在導致 while 循環終止之前,循環不能運行超過 n+m 次。
- 因為所有其他的工作都是常數,所以總的時間復雜度在矩陣維數之和中是線性的。
根據以上的偽代碼,我們基本上就能解出這個題目👇
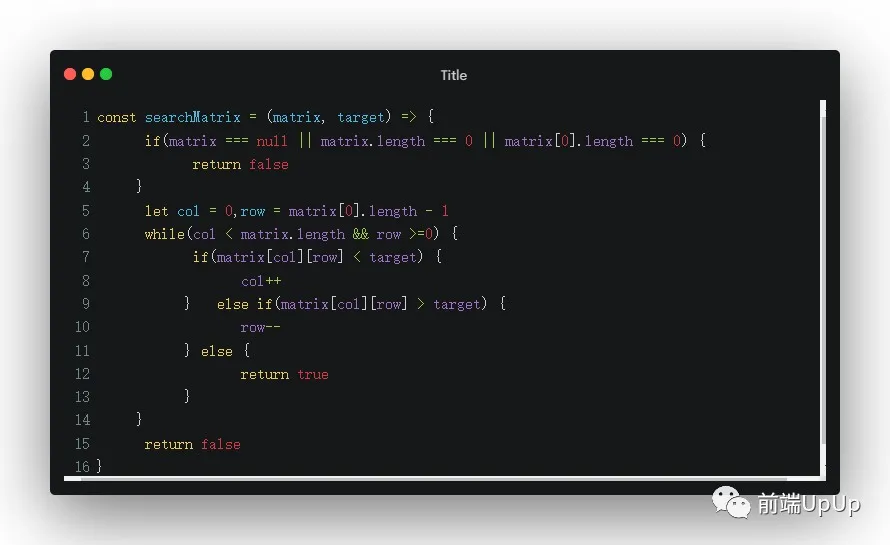
二位矩陣求值
這樣子的解法,簡單且容易理解,其實這并不是真正意義上的二分,只是根據數據的特殊性,使用特定的搜索方式完成對矩陣的查找。
既然一維數組查某個值時,我們可以將復雜度降為log級別的時間復雜度,那么在二維的情況下,我們是不是也可以這么考慮呢?
這個思路,可以借鑒一下👇
- 我們可以迭代矩陣對角線,二分搜索這些行和列,對它們進行切片。
- 在對角線上迭代,二分搜索行和列,知道對角線上的迭代元素用完為止(這個時候,就可以放回true或者是false)
說得更加簡單一些,二分查找的思想是沿著對角線,行查找一下,列查找一下。
可以借鑒一下代碼,就會明白如何利用矩陣的對角線去分治。
二位矩陣求值
代碼點這里☑️
理清楚分治法思路,對它的特征有了一定的了解,明白何如利用它解決實際的問題,那或許這就是這篇文章的意義所在吧~
題目匯總
題目不多,但是對于基本的入門分治法,應該還是不錯的選擇👇
- 最大子序和
- 連續數列
- 切分數組



















