













一文讓你讀懂JAVA.IO、字符編碼
作者:JAVA互聯搬磚工人
本篇給大家介紹JAVA.IO、字符編碼,希望對你有所幫助。
1 JAVA.IO字節流
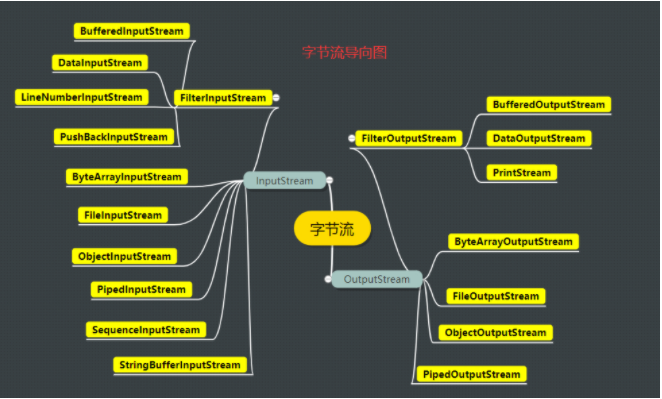
inputstream.png
- LineNumberInputStream和StringBufferInputStream官方建議不再使用,推薦使用LineNumberReader和StringReader代替
- ByteArrayInputStream和ByteArrayOutputStream 字節數組處理流,在內存中建立一個緩沖區作為流使用,從緩存區讀取數據比從存儲介質(如磁盤)的速率快
- //用ByteArrayOutputStream暫時緩存來自其他渠道的數據
- ByteArrayOutputStream data = new ByteArrayOutputStream(1024); //1024字節大小的緩存區
- data.write(System.in.read()); // 暫存用戶輸入數據
- //將data轉為ByteArrayInputStream
- ByteArrayInputStream in = new ByteArrayInputStream(data.toByteArray());
- FileInputStream和FileOutputStream 訪問文件,把文件作為InputStream,實現對文件的讀寫操作
- ObjectInputStream和ObjectOutputStream 對象流,構造函數需要傳入一個流,實現對JAVA對象的讀寫功能;可用于序列化,而對象需要實現Serializable接口
- //java對象的寫入
- FileOutputStream fileStream = new FileOutputStream("example.txt");
- ObjectOutputStream out = new ObjectOutputStream(fileStream);
- Example example = new Example();
- out.writeObject(example);
- //java對象的讀取
- FileInputStream fileStream = new FileInputStream("example.txt");
- ObjectInputStream in = new ObjectInputStream(fileStream);
- Example = (Example) in.readObject();
- PipedInputStream和PipedOutputStream 管道流,適用在兩個線程中傳輸數據,一個線程通過管道輸出流發送數據,另一個線程通過管道輸入流讀取數據,實現兩個線程間的數據通信
- // 創建一個發送者對象
- Sender sender = new Sender(); // 創建一個接收者對象
- Receiver receiver = new Receiver(); // 獲取輸出管道流
- // 獲取輸入輸出管道流
- PipedOutputStream outputStream = sender.getOutputStream();
- PipedInputStream inputStream = receiver.getInputStream();
- // 鏈接兩個管道,這一步很重要,把輸入流和輸出流聯通起來
- outputStream.connect(inputStream);
- sender.start();// 啟動發送者線程
- receiver.start();// 啟動接收者線程
- SequenceInputStream 把多個InputStream合并為一個InputStream,允許應用程序把幾個輸入流連續地合并起來
- InputStream in1 = new FileInputStream("example1.txt");
- InputStream in2 = new FileInputStream("example2.txt");
- SequenceInputStream sequenceInputStream = new SequenceInputStream(in1, in2);
- //數據讀取
- int data = sequenceInputStream.read();
- FilterInputStream和FilterOutputStream 使用了裝飾者模式來增加流的額外功能,子類構造參數需要一個InputStream/OutputStream
- ByteArrayOutputStream out = new ByteArrayOutputStream(2014);
- //數據寫入,使用DataOutputStream裝飾一個InputStream
- //使用InputStream具有對基本數據的處理能力
- DataOutputStream dataOut = new DataOutputStream(out);
- dataOut.writeDouble(1.0);
- //數據讀取
- ByteArrayInputStream in = new ByteArrayInputStream(out.toByteArray());
- DataInputStream dataIn = new DataInputStream(in);
- Double data = dataIn.readDouble();
- DataInputStream和DataOutputStream (Filter流的子類) 為其他流附加處理各種基本類型數據的能力,如byte、int、String
- BufferedInputStream和BufferedOutputStream (Filter流的子類) 為其他流增加緩沖功能
- PushBackInputStream (FilterInputStream子類) 推回輸入流,可以把讀取進來的某些數據重新回退到輸入流的緩沖區之中
- PrintStream (FilterOutputStream子類) 打印流,功能類似System.out.print
2 JAVA.IO字符流
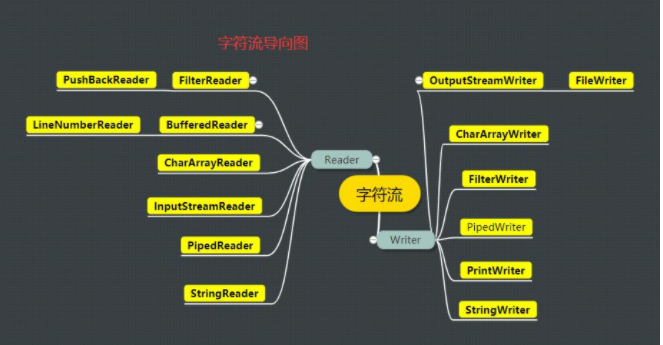
21.png
- 從字節流和字符流的導向圖來,它們之間是相互對應的,比如CharArrayReader和ByteArrayInputStream
- 字節流和字符流的轉化:InputStreamReader可以將InputStream轉為Reader,OutputStreamReader可以將OutputStream轉為Writer
- //InputStream轉為Reader
- InputStream inputStream = new ByteArrayInputStream("程序".getBytes());
- InputStreamReader reader = new InputStreamReader(inputStream, StandardCharsets.UTF_8);
- //OutputStream轉為Writer
- OutputStream out = new FileOutputStream("example.txt");
- OutputStreamWriter writer = new OutputStreamWriter(out);
- //以字符為單位讀寫
- writer.write(reader.read(new char[2]));
- 區別:字節流讀取單位是字節,字符流讀取單位是字符;一個字符由字節組成,如變字長編碼UTF-8是由1~4個字節表示
3 亂碼問題和字符流
- 字符以不同的編碼表示,它的字節長度(字長)是不一樣的。如“程”的utf-8編碼格式,由[-25][-88][-117]組成。而ISO_8859_1編碼則是單個字節[63]
- 平時工作對資源的操作都是面向字節流的,然而數據資源根據不同的字節編碼轉為字節時,它們的內容是不一樣,容易造成亂碼問題
- 兩種出現亂碼場景 encode和decode使用的字符編碼不一致:資源使用UTF-8編碼,而在代碼里卻使用GBK解碼打開使用字節流讀取字節數不符合字符規定字長:字符是由字節組成的,比如“程”的utf-8格式是三個字節;如果在InputStream里以每兩個字節讀取流,再轉為String(java默認編碼是utf-8),此時會出現亂碼(半個中文,你猜是什么)
- ByteArrayInputStream in = new ByteArrayInputStream("程序大法好".getBytes());
- byte[] buf = new byte[2]; //讀取流的兩個字節
- in.read(buf); //讀取數據
- System.out.println(new String(buf)); //亂碼
- ---result----
- � //亂碼
- 亂碼場景1,知道資源的字符編碼,就可以使用對應的字符編碼來解碼解決
- 亂碼場景2,可以一次性讀取所有字節,再一次性編碼處理。但是對于大文件流,這是不現實的,因此有了字符流的出現
- 字節流使用InputStreamReader、OutputStreamReader轉化為字符流,其中可以指定字符編碼,再以字符為單位來處理,可解決亂碼
- InputStreamReader reader =
- new InputStreamReader(inputStream, StandardCharsets.UTF_8);
4 字符集和字符編碼的概念區分
- 字符集和字符編碼的關系,字符集是規范,字符編碼是規范的具體實現;字符集規定了符號和二進制代碼值的唯一對應關系,但是沒有指定具體的存儲方式;
- unicode、ASCII、GB2312、GBK都是字符集;其中ASCII、GB2312、GBK既是字符集也是字符編碼;注意不混淆這兩者區別;而unicode的具體實現有UTF-8,UTF-16,UTF-32
- 最早出現的ASCII碼是使用一個字節(8bit)來規定字符和二進制映射關系,標準ASCII編碼規定了128個字符,在英文的世界,是夠用的。但是中文,日文等其他文字符號怎么映射呢?因此其他更大的字符集出現了
- unicode(統一字符集),早期時它使用2個byte表示1個字符,整個字符集可以容納65536個字符。然而仍然不夠用,于是擴展到4個byte表示一個字符,現支持范圍是U+010000~U+10FFFF
- unicode是兩個字節的說法是錯誤的;UTF-8是變字長的,需要用1~4個字節存儲;UTF-16一般是兩個字節(U+0000~U+FFFF范圍),如果遇到兩個字節存不下,則用4個字節;而UTF-32是固定四個字節
- unicode表示的字符,會用“U+”開頭,后面跟著十六進制的數字,如“字”的編碼就是U+5B57
- UTF-8 編碼和unicode字符集
范圍 Unicode(Binary) UTF-8編碼(Binary) UTF-8編碼byte長度 U+0000~U+007F 00000000 00000000 00000000 0XXXXXXX 0XXXXXX 1 U+0080~U+07FF 00000000 00000000 00000YYY YYXXXXXX 110YYYYY 10XXXXXX 2 U+0800~U+FFFF 00000000 00000000 ZZZZYYYY YYXXXXXX 1110ZZZZ 10YYYYYY 10XXXXXX 3 U+010000~U+10FFFF 00000000 000AAAZZ ZZZZYYYY YYXXXXXX 11110AAA 10ZZZZZZ 10YYYYYY 10XXXXXX 4
- 程序是分內碼和外碼,java的默認編碼是UTF-8,其實指的是外碼;內碼傾向于使用定長碼,和內存對齊一個原理,便于處理。外碼傾向于使用變長碼,變長碼將常用字符編為短編碼,罕見字符編為長編碼,節省存儲空間與傳輸帶寬
- JDK8的字符串,是使用char[]來存儲字符的,char是兩個字節大小,其中使用的是UTF-16編碼(內碼)。而unicode規定的中文字符在U+0000~U+FFFF內,因此使用char(UTF-16編碼)存儲中文是不會出現亂碼的
- JDK9后,字符串則使用byte[]數組來存儲,因為有一些字符一個char已經存不了,如emoji表情字符,使用字節存儲字符串更容易拓展
- JDK9,如果字符串的內容都是ISO-8859-1/Latin-1字符(1個字符1字節),則使用ISO-8859-1/Latin-1編碼存儲字符串,否則使用UTF-16編碼存儲數組(2或4個字節)
- System.out.println(Charset.defaultCharset()); //輸出java默認編碼
- for (byte item : "程序".getBytes(StandardCharsets.UTF_16)) {
- System.out.print("[" + item + "]");
- }
- System.out.println("");
- for (byte item : "程序".getBytes(StandardCharsets.UTF_8)) {
- System.out.print("[" + item + "]");
- }
- ----result----
- UTF-8 //java默認編碼UTF-8
- [-2][-1][122][11][94][-113] //UTF_16:6個字節?
- [-25][-88][-117][-27][-70][-113] //UTF_8:6個字節 正常
- “程序”的UTF-16編碼竟是輸出6個字節,多出了兩個字節,這是什么情況?再試試一個字符的輸
- for (byte item : "程".getBytes(StandardCharsets.UTF_16)) {
- System.out.print("[" + item + "]");
- }
- ---result--
- [-2][-1][122][11]
- 可以看出UTF-16編碼的字節是多了[-2][-1]兩個字節,十六進制是0xFEFF。而它用來標識編碼順序是Big endian還是Little endian。以字符'中'為例,它的unicode十六進制是4E2D,存儲時4E在前,2D在后,就是Big endian;2D在前,4E在后,就是Little endian。FEFF表示存儲采用Big endian,FFFE表示使用Little endian
- 為什么UTF-8沒有字節序的問題呢?個人看法,因為UTF-8是變長的,由第一個字節的頭部的0、110、1110、11110判斷是否需后續幾個字節組成字符,使用Big endian易讀取處理,反過來不好處理,因此強制用Big endian
- 其實感覺UTF-16可以強制規定用Big endian;但這其中歷史問題。。。
【編輯推薦】
責任編輯:姜華
來源:
今日頭條

























