美團提出基于隱式條件位置編碼,性能優于ViT和DeiT
隨著 Facebook 的 DETR (ECCV 2020)[2] 和谷歌的 ViT (ICLR 2021)[3] 的提出,Transformer 在視覺領域的應用開始迅速升溫,成為當下視覺研究的第一熱點。但視覺 Transformer 受限于固定長度的位置編碼,不能像 CNN 一樣直接處理不同的輸入尺寸,這在很大程度上限制了視覺 Transformer 的應用,因為很多視覺任務,如檢測,需要在測試時動態改變輸入大小。
一種解決方案是對 ViT 中位置編碼進行插值,使其適應不同的圖片大小,但這種方案需要重新 fine-tune 模型,否則結果會變差。
最近,美團提出了一種用于視覺 Transformer 的隱式條件位置編碼 CPE [1],放寬了顯式位置編碼給輸入尺寸帶來的限制,使得 Transformer 便于處理不同尺寸的輸入。實驗表明,應用了 CPE 的 Transformer 性能優于 ViT 和 DeiT。
論文地址:https://arxiv.org/pdf/2102.10882.pdf
項目地址:https://github.com/Meituan-AutoML/CPVT(即將開源)
背景
谷歌的 ViT 方法通常將一幅 224×224 的圖片打散成 196 個 16×16 的圖片塊(patch),依次對其做線性編碼,從而得到一個輸入序列(input sequence),使 Transformer 可以像處理字符序列一樣處理圖片。同時,為了保留各個圖片塊之間的位置信息,加入了和輸入序列編碼維度等長的位置編碼。DeiT [4] 提高了 ViT 的訓練效率,不再需要把大數據集(如 JFT-300M)作為預訓練的限制,Transformer 可以直接在 ImageNet 上訓練。
對于視覺 Transformer,位置編碼不可或缺
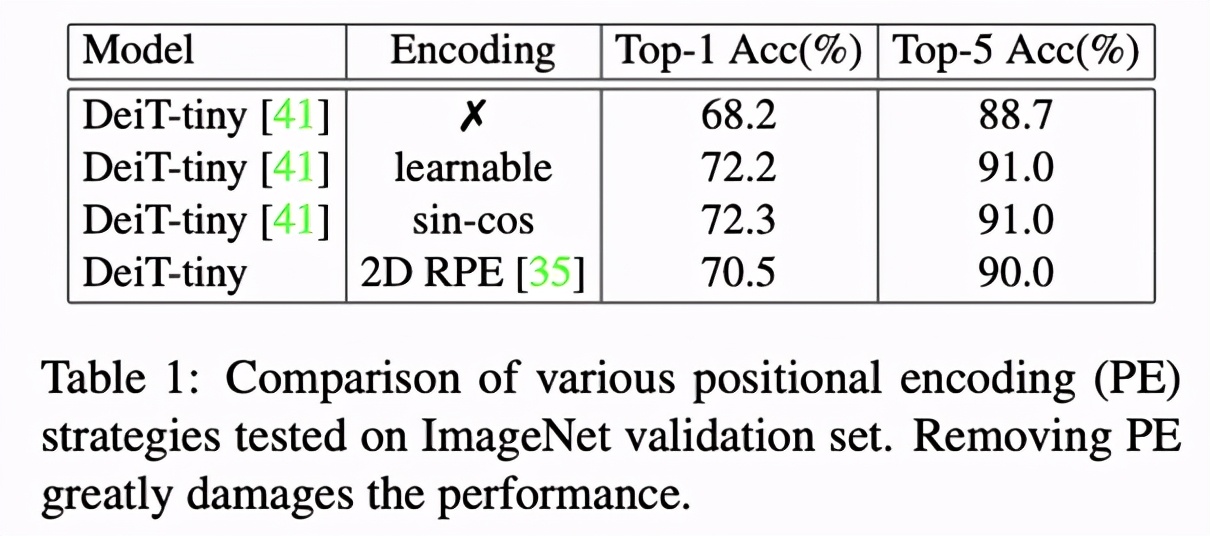
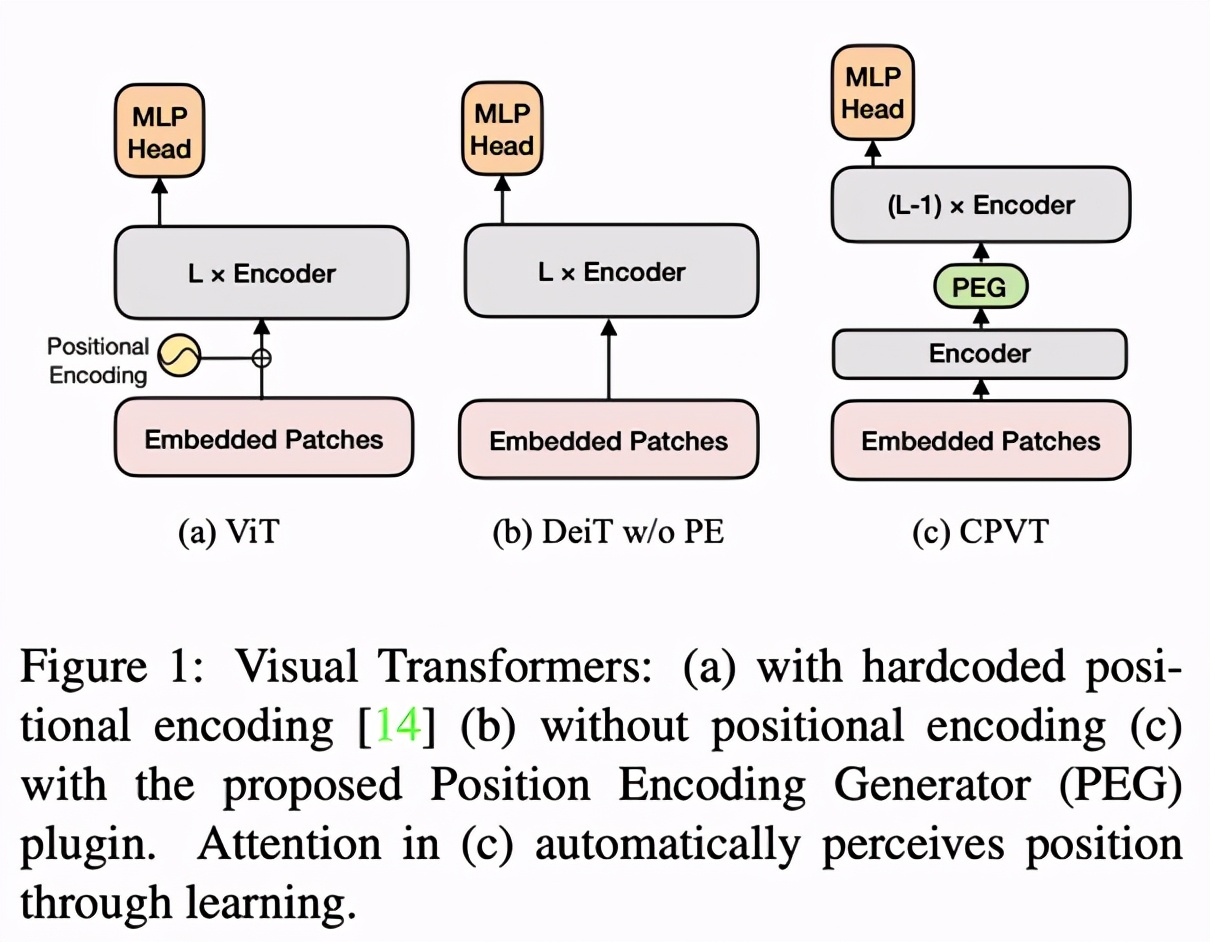
在 ViT 和 CPVT 的實驗中,我們可以發現沒有位置編碼的 Transformer 性能會出現明顯下降。除此之外,在 Table 1 中,可學習(learnable)的位置編碼和正余弦(sin-cos)編碼效果接近,2D 的相對編碼(2D RPE)性能較差,但仍然優于去掉位置編碼的情形。
美團、阿德萊德大學提出新型位置編碼方法
位置編碼的設計要求
顯式的位置編碼限制了輸入尺寸,因此美團這項研究考慮使用隱式的根據輸入而變化的變長編碼方法。此外,它還需要滿足以下要求:
保持很好的性能;
避免排列不變性(permutation equivariance);
易于實現。
基于上述要求,該研究提出了條件編碼生成器 PEG(Positional Encoding Generator),來生成隱式的位置編碼。
生成隱式的條件位置編碼
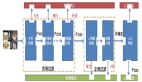
在 PEG 中,將上一層 Encoder 的 1D 輸出變形成 2D,再使用變換模塊學習其位置信息,最后重新變形到 1D 空間,與之前的 1D 輸出相加之后作為下一個 Encoder 的輸入,如 Figure 2 所示。這里的變換單元(Transoformation unit)可以是 Depthwise 卷積、Depthwise Separable 卷積或其他更為復雜的模塊。
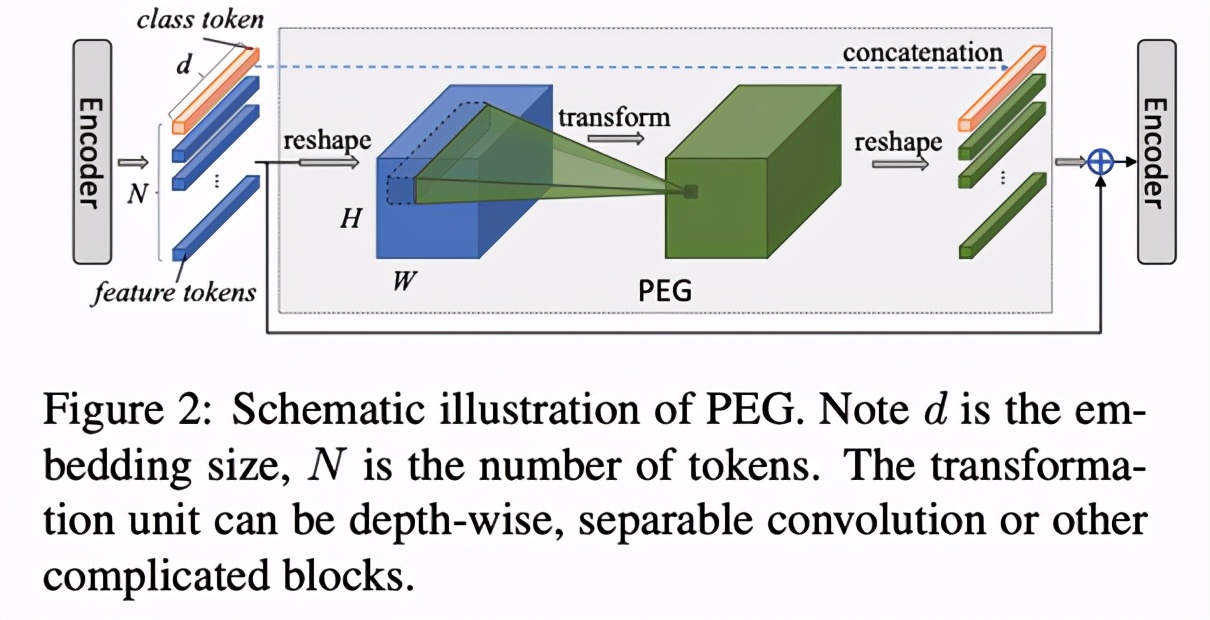
將 PEG 插入到模型中(如 Figure 1 中添加在第一個 Encoder 后),即可對各個 Encoder 添加位置編碼信息。這種編碼好處在于不需要顯式指定,長度可以依輸入變化而變化,因此被稱為隱式的條件位置編碼。
實驗
ImageNet 數據集
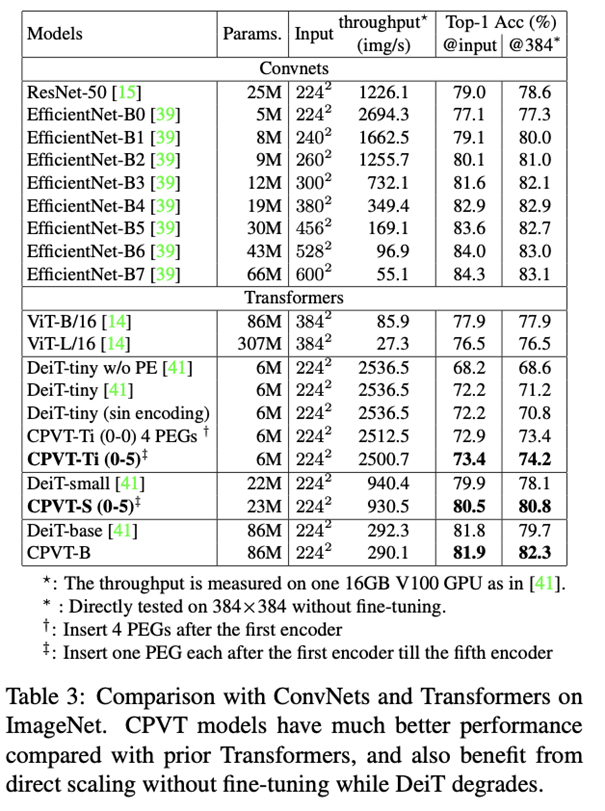
該研究將添加了 PEG 的 Vision Transformer 模型命名為 CPVT(Conditional Position encodings Visual Transformer)。在 ImageNet 數據集上,相同量級的 CPVT 模型性能優于 ViT 和 DeiT。得益于隱式條件編碼可以根據輸入動態調整的特性,基于 224×224 輸入訓練好的模型可以直接處理 384×384 輸入(Table 3 最后一列),無需 fine-tune 就能直接獲得性能提升。相比之下,其他顯式編碼沒有 fine-tune 則會出現性能損失。
與其他編碼方式的對比
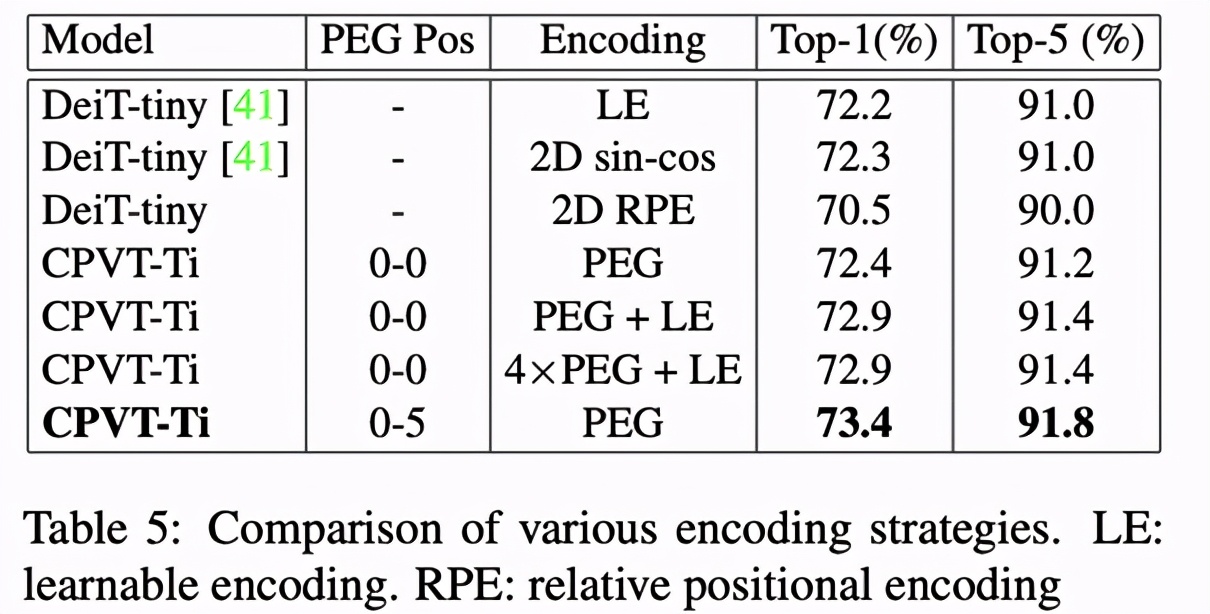
Table 5 給出了 CPVT-Ti 模型在不同編碼策略下的表現。其中在從第 0 個到第 5 個 Encoder 各插入一個 PEG 的性能最優,Top-1 準確率達到 73.4%。CPVT 單獨使用 PEG 或與可學習編碼相結合也優于 DeiT-tiny 在各種編碼策略下的表現。
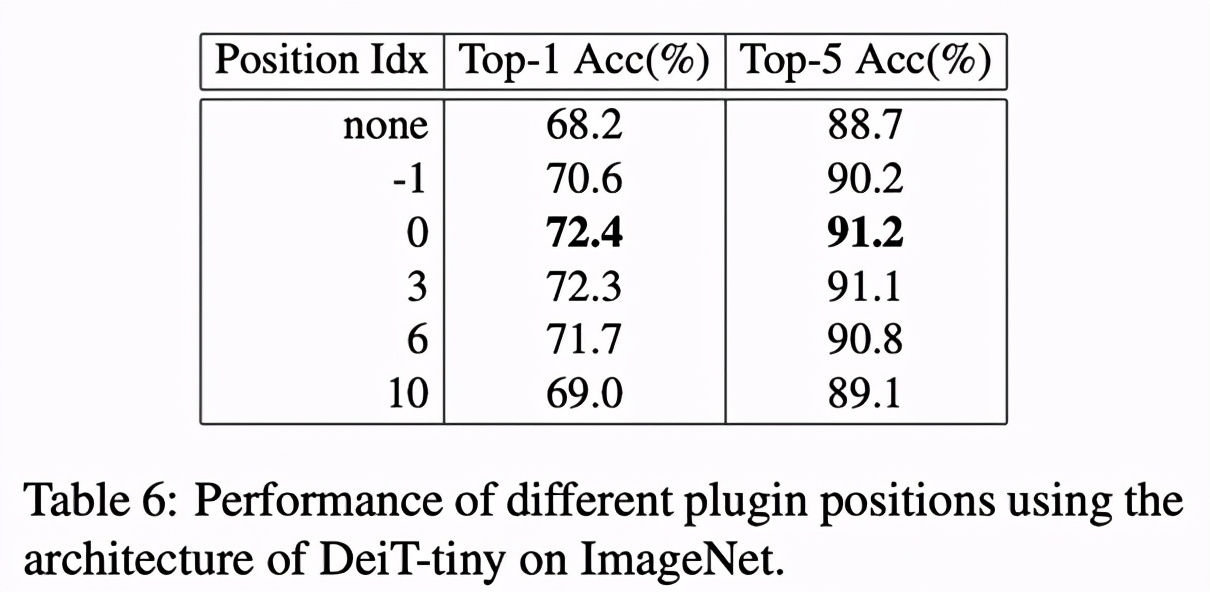
PEG 在不同位置的作用
ViT 主干由 12 個 Encoder 組成,CPVT 對比了 PEG 位于 -1、0、3、6、10 等處的結果。實驗表明,PEG 用于第一個 Encoder 之后表現最好 (idx 0)。該研究認為,放在第一個 encoder 之后不僅可以提供全局的接受域,也能夠保證模型盡早地利用到位置信息。
結論
CPVT 提出的隱式位置編碼是一個即插即用的通用方法。它放寬了對輸入尺寸的限制,因而有望促進 Vision Transformer 在分割、檢測、超分辨率等任務中的進一步應用,提升其性能。這項研究對后續 Vision Transformer 的發展將產生積極的影響。