「原理」AB測試-詳細過程和原理解讀
本文轉載自微信公眾號「巡山貓說數據」,作者巡山貓 。轉載本文請聯系巡山貓說數據公眾號。
AB測試原理簡介
AB測試最核心的原理,就四個字:假設檢驗。檢驗我們提出的假設是否正確。對應到AB測試中,就是檢驗實驗組&對照組,指標是否有顯著差異。
既然是假設檢驗,那么就是先假設,再收集數據,最后根據收集的數據來做檢驗。
先來說說假設。
假設一般成對出現,分為零假設 和 備選假設。
在AB測試中,零假設是:實驗組&對照組 指標相同,無顯著差異;備選假設則相反,實驗組&對照組 指標不同,有顯著差異。
舉個例子。我們優化了某算法,想提高頁面的點擊率。針對這個場景的AB測試,零假設就是 新算法&老算法的頁面點擊率無明顯差異,備選假設是 新算法&老算法的頁面點擊率有顯著差異。
再來說說檢驗。
一般來說,我們是通過具體的指標屬性來找尋相應的檢驗方法。那么問題來了,指標如何分類呢?
指標可以分為兩種類別:
1、絕對值類指標。也就是我們平常直接計算就能得到的,比如DAU,點擊次數等。我們的一般都是統計該指標在一段時間內的均值或者匯總值,不存在兩個值之間還要相互計算。
2、相對值類指標。與絕對值類指標相反,我們不能直接計算得到。比如某頁面的CTR,我們是用 頁面點擊數 / 頁面展現數。我們要計算點擊數和展現數,兩者相除才能得到該指標。類似的,還有XX轉化率,XX點擊率,XX購買率一類的。我們做的AB實驗,大部分情況下都想提高這類指標。
根據指標我們可以知道,該如何計算最小樣本量,以及實驗周期,以及對應的檢驗方法。
AB測試詳細流程
我們先看一個圖,結合這個實驗的流程圖,我們一點點來說:

選取指標
在做AB測試之前,我們一定要清楚,我們實驗的目標是什么。并落地到具體的幾個指標上,這幾個指標對于我們度量實驗結果,有非常明顯的幫助。但是,指標也要分層級,唯一一個核心指標+多個觀察指標。
核心指標用來度量我們這次實驗的效果,以及計算相應的樣本量。觀察指標則用來度量,該實驗對其他數據的影響(比如對大盤留存的影響,對網絡延遲的影響等等)。
建立假設
建立假設就如同上文所說,我們建立了零假設和備選假設,零假設一般是沒有效果,備選假設是有效果。
選取實驗單位
大家應該都使用用戶粒度來作為實驗單位,但是總體說來,實驗單位一般有3種。我們不用掌握,但是很多情況下面試官會問到,大家可以作為了解。
1、用戶粒度:這個是最推薦的,即以一個用戶的唯一標識來作為實驗樣本。好處是符合AB測試的分桶單位唯一性,不會造成一個實驗單位處于兩個分桶,造成的數據不置信。
2、設備粒度:以一個設備標識為實驗單位。相比用戶粒度,如果一個用戶有兩個手機,那么也可能出現一個用戶在兩個分桶中的情況,所以也會造成數據不置信的情況。
3、行為粒度:以一次行為為實驗單位,也就是用戶某一次使用該功能,是實驗桶,下一次使用可能就被切換為基線桶。會造成大量的用戶處于不同的分桶。強烈不推薦這種方式。
計算樣本量
樣本量計算,我們需要了解一下中心極限定理。具體書面定義和推導過程,大家可以在網上百度一下就好,我們這里就通俗的解釋一下。中心極限定理的含義,就是只要樣本量足夠大,無論是什么指標,無論對應的指標分布是怎樣的,樣本的均值分布都會趨于正態分布。
基于正態分布,我們才能計算出相應的樣本量和做假設檢驗。具體的樣本量計算推導過程,大家如有需要,可以關注后加我微信私聊,這里就放結論。
整體公式如下:

由于指標可以分為將絕對值指標和相對值指標。對應的,我們在計算絕對值指標和相對值指標時,標準差的計算方式也會不同。具體如下:

我們舉兩個例子說明一下,讓大家更有體感。
案例1-相對值指標:
某產品點擊率1.5%,波動范圍[1.0%,2.0%],優化了該功能后,需要AB測試計算樣本量
P:1.5%,p:2.0%(由于波動范圍是[1.0%,2.0%],所以至少是2.0%
總樣本量 = 16 * (1.5%*(1-1.5%)+2.0%*(1-2.0%))/ (2.0%-1.5%)^2=22000
案例2-絕對值指標:
某產品購買金額標準差是25,優化了該功能后,預估至少有5元的絕對提升,需要AB測試計算樣本量
σ=25,Δ=5
總樣本量 = 16 * 25*25*2/5*5=800
最小樣本量,是指我們的實驗單位,必須滿足這個數量,實驗結果中的數據檢驗才可信。也就是說,我們的實驗桶必須達到這個流量,才能收集數據及檢驗指標。
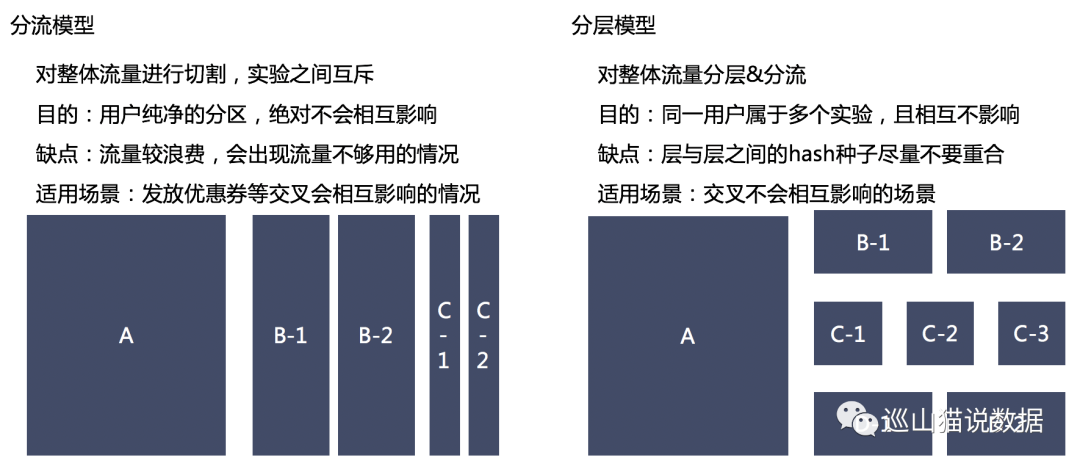
流量分割
流量切割有兩種方式:分流和分層。
分流是指我們直接將整體用戶切割為幾塊,用戶只能在一個實驗中。但是這種情況很不現實,因為如果我要同時上線多個實驗,流量不夠切怎么辦?那為了達到最小樣本量,我們就得延長實驗周期,要是做一個實驗,要幾個月,相信我,你老板一定會和你聊聊人生理想的。
另一種方式,分層。就是將同一批用戶,不停的隨機后,處于不同的桶。也就是說,一個用戶會處于多個實驗中,只要實驗之間不相互影響,我們就能夠無限次的切割用戶。這樣在保證了每個實驗都能用全流量切割的同時,也保證了實驗數據是置信的。
兩種方式用圖來表達如下:
實驗周期計算
相應的,最小樣本量有了,我們切分了流量,知道了實驗桶一天大概能有多少樣本量(也可以算小時,如果產品的流量足夠大)。我們直接用 最小樣本量 / 實驗桶天均流量 即可以得到相應的實驗周期。
線上驗證
很多公司不會做線上驗證。當然,不驗證也沒關系,就是有可能會踩坑,所以還是建議大家在實驗上線后進行線上驗證。
線上驗證主要是2個方向,一個是驗證實驗策略是否真的觸發。即我們上線的實驗桶,是否在產品上實際落地了。比如你優化了一個產品功能,你可以去實際體驗下,實驗桶產品是否真的有優化。
另一個是驗證同一個用戶只能在同一個桶中,要是同時出現在兩個桶中,后期數據也會不置信。這個上文有說過。
數據檢驗
數據檢驗,大家可能都聽過。比如Z檢驗,T檢驗,單尾檢驗,雙尾檢驗,算P值,算置信區間等等。我們這里先說說哪種情況用Z檢驗,哪種情況用T檢驗。因為這個問題經常會碰到,也是AB測試中,面試官的必問問題。
大家應該都看過這個圖:
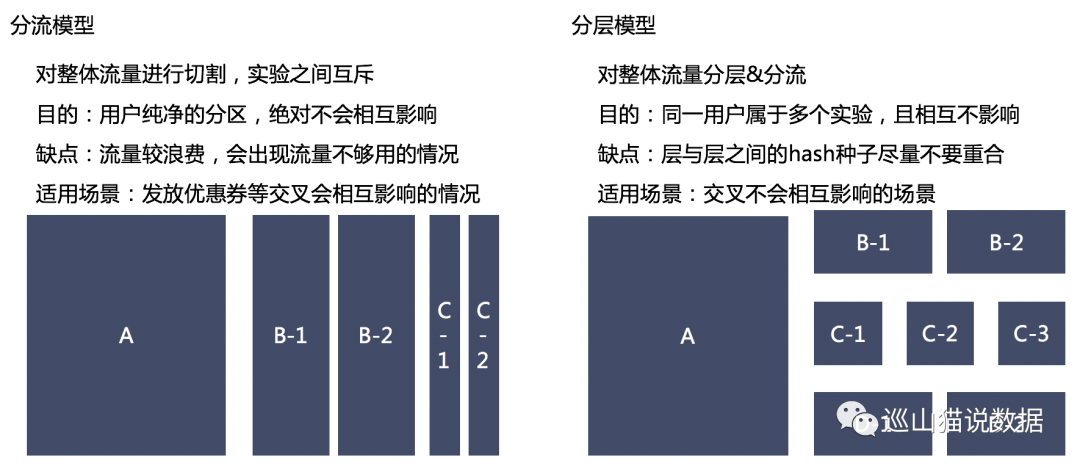
按照上文我們說的指標分類,一般情況下,絕對值指標用T檢驗,相對值指標用Z檢驗。因為絕對指標的的總體方差,需要知道每一個用戶的值,這個在AB實驗中肯定不可能。而相對值指標是二項分布,可以通過樣本量的值計算出總體的值,就如同10W人的某頁面點擊率是10%,隨機從這10W人中抽樣1W人,這個點擊率也是10%一樣。
再來說說具體的檢驗。一般情況下我們可以用兩種常用方法:
1、算P值,也就是算當零假設成立時,觀測到樣本數據出現的概率。統計學上,將5%作為一個小概率事件,所以一般用5%來對比計算出來的P值。當P值小于5%時,拒絕零假設,即兩組指標不同;反過來,當P值大于5%時,接受零假設,兩組指標相同。
2、算置信區間。一般情況下,我們都會用95%來作為置信水平。也就是說,當前數據的估計,有95%的區間包含了總體參數的真值。這么說可能比較繞,我們可以簡單理解成 總體數據有95%的可能性在這個范圍內。
我們計算兩組指標的差異值,如果我們算出的差異值置信區間不含0,我們就拒絕零假設,認為兩組指標不同;但是如果包含0,我們則要接受零假設,認為兩組指標相同。
當然,我們也可以直接算出Z值或者T值,查表對比。但是這種不是很常用,還是以P值及置信區間為主流。
還有些公司,會將所有指標計算到為不同流量區間內的自然波動。比如我有三個指標,日活100W,那么可以拆分成多個流量區間,比如 1w、2w、5w、10w、20w、50w,100w這幾個流量比例,然后依次計算這3個指標,在這些流量下的自然波動閾值,如果高于閾值,我們就認為實驗有效。這種就會方便很多,但是不夠嚴謹。
最后來說說單尾檢驗,雙尾檢驗。單尾檢驗的前提是我們不僅認為兩組指標不同,還明確了大小,一般情況下,我們都認為實驗組的效果高于基線組。而雙尾檢驗只是認為兩組指標不同,未明確大小。通常來說,我們更推薦使用雙尾檢驗,為什么呢?
因為實驗本身就是一種利用數據來做決策的方法,我們不要再人為的帶入主觀設想。而是用雙尾檢驗,我們不僅能量化漲了多少,還能量化掉了多少,因為實驗結果有正有負,不一定都是有效果的(正向的),還可能有負向的效果,我們也可以將有負向效果的實驗記錄下來,沉淀成知識庫,為后期實驗避坑。
當然,生活中有些事件是可以用單尾檢驗的。比如我們優化了制造燈泡的流程,提升了燈泡的質量,那對于燈泡的質量檢驗我們就采用單尾檢驗就好,因為我們只關心燈泡質量是否和預期一樣,有所提升。
知識點總結
以上,我們就講完了整體的AB測試的流程,以及流程中的各個需要用到的知識點。
我們來總結下知識點:
1、實驗流程是 選取指標 -- 建立假設 -- 選取實驗單位 -- 計算樣本量 -- 流量分割 -- 實驗周期計算 -- 線上驗證 -- 數據檢驗。
2、假設分為零假設和備選假設,零假設一般都是實驗無效(指標無差異),備選假設是實驗有效(指標有差異)。
3、指標可以分為 絕對值指標 和相對值指標,相應的,絕對值指標推薦用T檢驗,相對值指標推薦用Z檢驗。
4、檢驗數據是否有效,可以算P值,高于5%就接受原假設,兩組指標相同;也可以算置信區間的差異值,如果差異值包含0,則接受原假設,兩組指標相同。