8個深度學習中常用的激活函數

激活函數,又稱轉換函數,是設計神經網絡的關鍵。激活函數在某種意義上是重要的,因為它被用來確定神經網絡的輸出。它將結果值映射為0到1或-1到1等(取決于函數)。激活函數還有另一個名稱,稱為Squashing函數,當限制了激活函數的范圍時使用這個名稱。激活函數應用于神經網絡的每個節點,并決定該神經元是否應該被“觸發”/“激活”。
為什么選擇激活函數是非常重要的。
當在隱藏層和輸出層中實現時,激活函數的選擇非常關鍵。模型的準確性和損失很大程度上依賴于激活函數。此外,必須根據您對模型的期望來選擇它們。例如,在二值分類問題中,sigmoid函數是一種最優選擇。
激活函數類型。大致可分為兩類:
線性激活函數。
非線性激活函數。
為了方便展示我們導入如下庫:
- import math as m
- import matplotlib.pyplot as plt
- import numpy as np
- import tensorflow as tf
- from tensorflow import keras
- from tensorflow.keras import layers
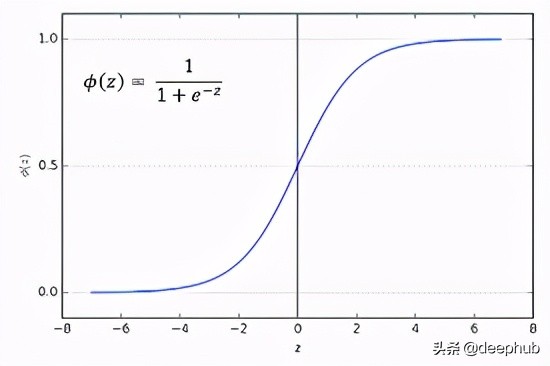
Sigmoid
sigmoid激活函數也稱為logistic函數。Sigmoid函數在回歸分類問題中非常流行。sigmoid函數給出的值的范圍是0和1。
- def sigmoid(x):
- return 1 / (1 + m.exp(-x))values_of_sigmoid = []
- values_of_x = []
- for i in range(-500,500,1):
- i = i*0.01
- values_of_x.append(i)
- values_of_sigmoid.append(sigmoid(i))plt.plot( values_of_x ,values_of_sigmoid)
- plt.xlabel("values of x")
- plt.ylabel("value of sigmoid")
tanH
這個函數非常類似于sigmoid激活函數。這個函數在-1到1的范圍內接受任何實值作為輸入和輸出值。輸入越大(越正),輸出值越接近1.0,而輸入越小(越負),輸出越接近-1.0。Tanh激活函數計算如下。
- def tanh(x):
- return (m.exp(x) - m.exp(-x)) / (m.exp(x) + m.exp(-x))values_of_tanh = []
- values_of_x = []
- for i in range(-500,500,1):
- i = i*0.001
- values_of_x.append(i)
- values_of_tanh.append(tanh(i))plt.plot( values_of_x ,values_of_tanh)
- plt.xlabel("values of x")
- plt.ylabel("value of tanh")

Softmax
Softmax激活函數輸出一個和為1.0的值向量,可以解釋為類隸屬度的概率。Softmax是argmax函數的“軟”版本,它允許一個“贏家通吃”函數的似然輸出。
- def softmax(x):
- e_x = np.exp(x - np.max(x))
- return e_x / e_x.sum()values_of_x = [i*0.01 for i in range(-500,500)]
- plt.plot(scores ,softmax(values_of_x))
- plt.xlabel("values of x")
- plt.ylabel("value of softmax")
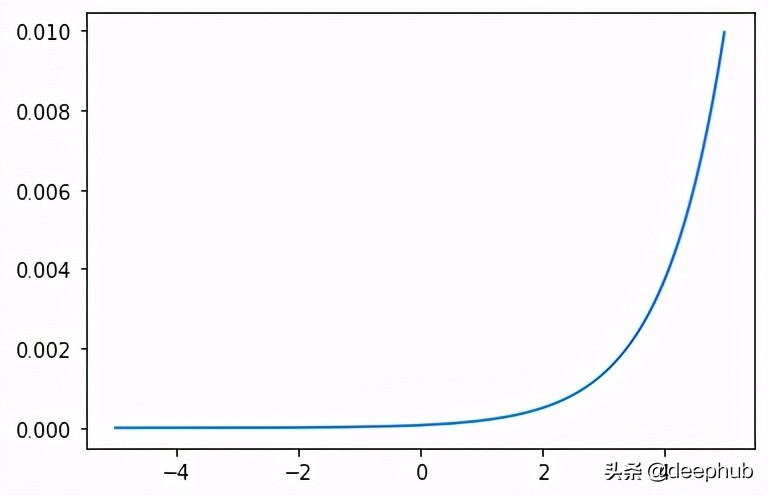
RELU 線性整流單元
ReLU可能是用于隱藏層的最常見的函數。它還可以有效地克服其他以前流行的激活函數(如Sigmoid和Tanh)的限制。具體來說,它不太容易受到阻止深度模型被訓練的梯度下降消失問題的影響,盡管它可能會遇到諸如飽和單元等其他問題。
- def ReLU(x):
- return max(0,x)values_of_relu = []
- values_of_x = []
- for i in range(-500,500,1):
- i = i*0.01
- values_of_x.append(i)
- values_of_relu.append(ReLU(i))plt.plot(values_of_x,values_of_relu)
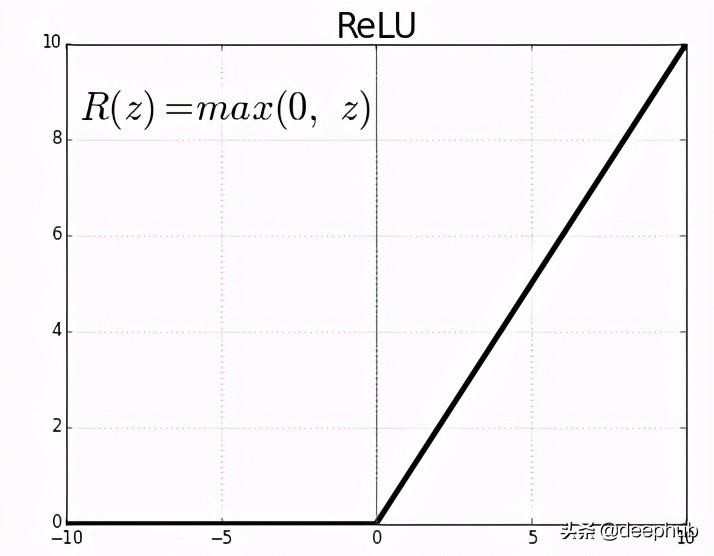
Leaky ReLU
ReLU的問題:當給ReLU一個負值時,它立即變成零,這降低了模型合適地擬合或從數據訓練的能力。這意味著ReLU激活函數的任何負輸入都會在圖中立即將該值轉換為零,這反過來又會通過不適當地映射負值而影響結果圖。
為了克服這個問題,Leaky ReLU被引入。
- def leaky_ReLU(x):
- return max(0.1*x,x)values_of_L_relu = []
- values_of_x = []
- for i in range(-500,500,1):
- i = i*0.01
- values_of_x.append(i)
- values_of_L_relu.append(leaky_ReLU(i))plt.plot(values_of_x,values_of_L_relu)
下面幾個函數都是RELU的變體基本上都是與Leaky 類似優化了激活函數負值時的返回
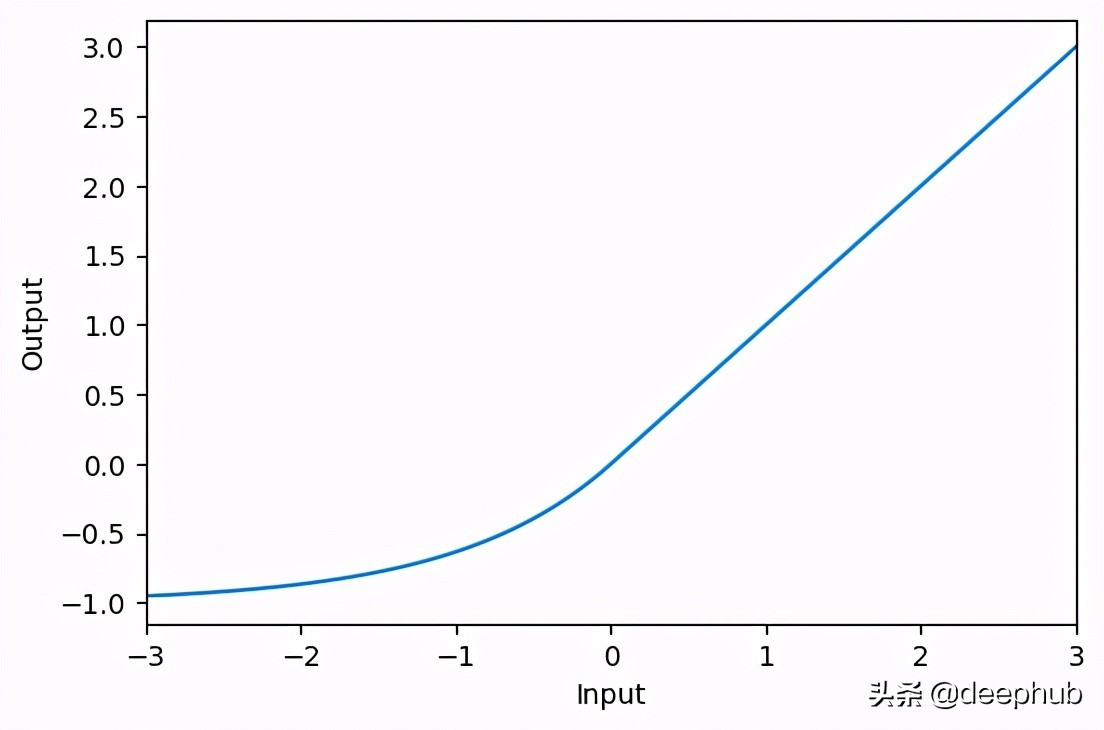
ELU
- activation_elu = layers.Activation(‘elu’)x = tf.linspace(-3.0, 3.0, 100)
- y = activation_elu(x) # once created, a layer is callable just like a functionplt.figure(dpi=100)
- plt.plot(x, y)
- plt.xlim(-3, 3)
- plt.xlabel(“Input”)
- plt.ylabel(“Output”)
- plt.show()
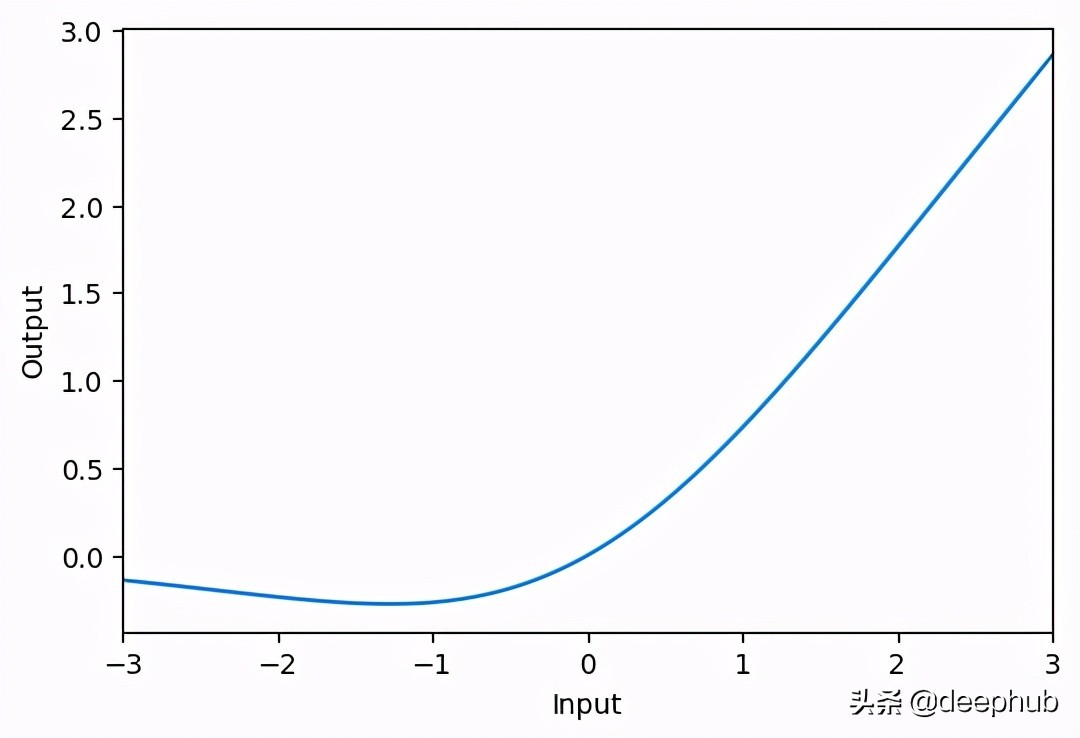
SELU
- activation_selu = layers.Activation('selu')x = tf.linspace(-3.0, 3.0, 100)
- y = activation_selu(x) # once created, a layer is callable just like a functionplt.figure(dpi=100)
- plt.plot(x, y)
- plt.xlim(-3, 3)
- plt.xlabel("Input")
- plt.ylabel("Output")
- plt.show()
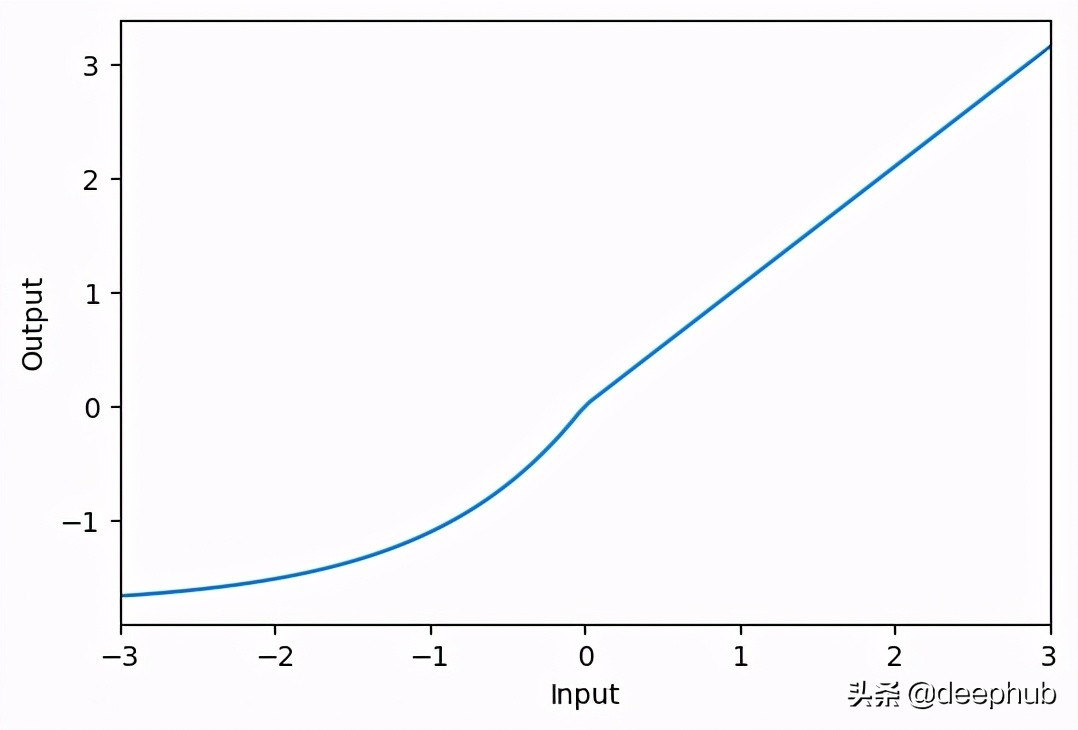
Swish
- activation_swish = layers.Activation(‘swish’)x = tf.linspace(-3.0, 3.0, 100)
- y = activation_swish(x) # once created, a layer is callable just like a functionplt.figure(dpi=100)
- plt.plot(x, y)
- plt.xlim(-3, 3)
- plt.xlabel(“Input”)
- plt.ylabel(“Output”)
- plt.show()
總結
常用于隱藏層激活函數:
一般遞歸神經網絡使用Tanh或sigmoid激活函數,甚至兩者都使用。例如,LSTM通常對循環連接使用Sigmoid激活,對輸出使用Tanh激活。
1.多層感知器(MLP): ReLU激活函數。
2.卷積神經網絡(CNN): ReLU激活函數。
3.遞歸神經網絡:Tanh和/或Sigmoid激活函數。
如果你不確定使用哪個激活函數,你肯定可以嘗試不同的組合,并尋找最適合的,但是可以從RELU開始
輸出層激活功能:
輸出層激活函數必須根據你要解決的問題類型來選擇。例如,如果你有一個線性回歸問題,那么線性激活函數將是有用的。下面是您可能面臨的一些常見問題和使用的激活函數。
二進制分類:一個節點,sigmoid激活。
多類分類:每個類一個節點,softmax激活。
多標簽分類:每個類一個節點,sigmoid激活。
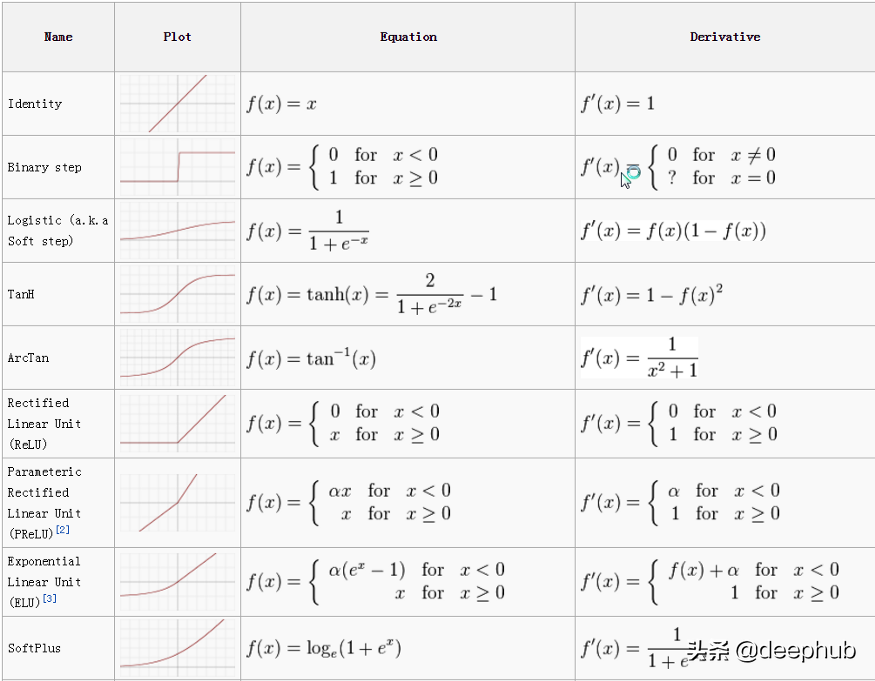
以下是一些常用激活函數的公式和可視化顯示,希望對你有幫助