手把手教你用Pyecharts庫對淘寶數據進行可視化展示
大家好,我是Python進階者。
一、前言
大家好,我是Python進階者。上一篇文章給大家講到了淘寶數據的預處理和詞頻處理,沒有來得及看的小伙伴,記得去學習了下了,詳情戳這里:手把手教你用Pandas庫對淘寶原始數據進行數據處理和分詞處理。這篇文章緊接著上一篇文章處理得到的數據進行可視化處理,一起來看看吧!
二、可視化
可視化部分,我們采用Pyecharts庫來進行完成,這個庫作圖十分的炫酷,而且可以交互,十分帶感,強烈推薦。關于這部分,小編以生成配料圖表和生成保質期可視化圖表為例來進行展開。
1、生成配料餅圖
針對配料數據,我們使用一個餅圖去進行展示,這樣顯得更加高大上一些,直接上代碼。
- # 生成配料圖表
- def get_ingredients_html(df):
- # 詞表分詞
- names = df.配料表.apply(jieba.lcut).explode()
- df1 = names[names.apply(len)>1].value_counts()
- # 寫入分詞后的結果
- with pd.ExcelWriter("淘寶商品配料數據.xlsx") as writer:
- df1.to_excel(writer, sheet_name="配料")
- fpath = r'C:\Users\pdcfi\Desktop\淘寶數據分析\淘寶商品配料數據.xlsx'
- # 讀取數據 提取列
- df1 = pd.read_excel(fpath, header=None, skiprows=1, sheet_name='配料', names=['sx', 'sl'])
- a = df1['sx'].to_list()[:10]
- b = df1['sl'].to_list()[:10]
- from pyecharts.charts import Pie
- from pyecharts import options as opts
- # 繪制可視化圖表
- pie = (
- Pie().add('', [list(z) for z in zip(a, b)],
- radius=["20%", "60%"], # 半徑長度
- rosetype="radius" # 扇區圓心角展現數據的百分比,半徑展現數據的大小
- )
- .set_global_opts(title_opts=opts.TitleOpts(title="淘寶商品數據配料統計", subtitle="8.19"))
- .set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: owocgsc%")) # 數字項名稱和百分比
- )
- pie.render('淘寶商品數據配料統計.html')
在Pycharm里邊運行代碼之后,我們將會得到一個淘寶商品數據配料統計.html文件,雙擊打開該HTML文件,在瀏覽器里邊可以看到效果圖,如下圖所示。
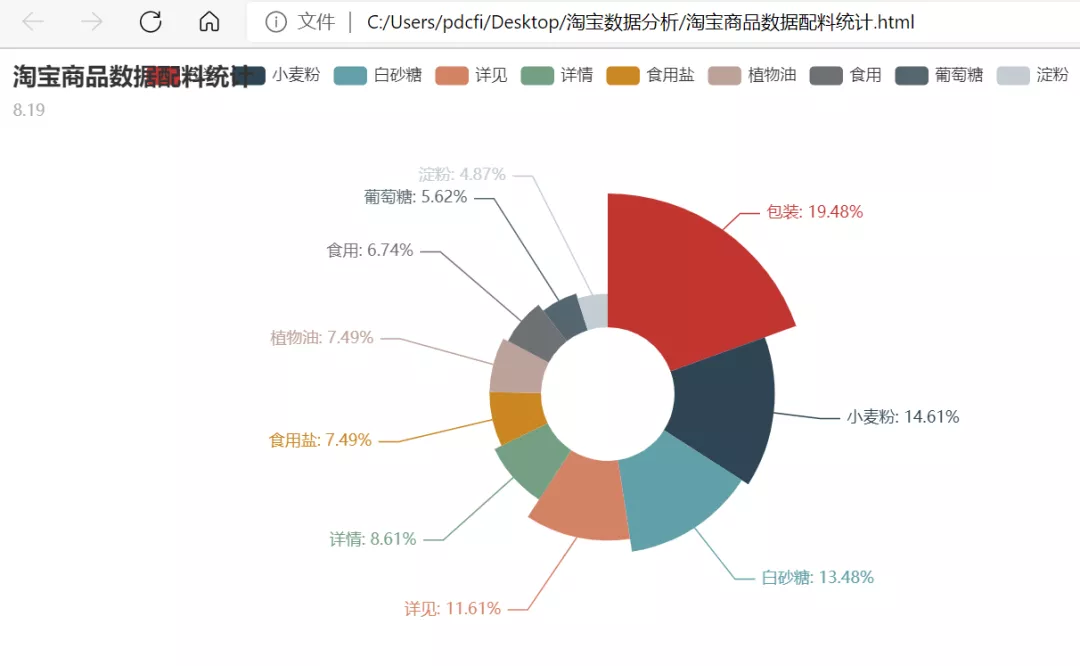
是不是感覺一下子就高大上了呢?而且動動鼠標,你還可以進行交互,是動態圖來著,十分好玩。
2、生成保質期可視化餅圖
針對保質期數據,我們也先使用一個餅圖去進行展示,直接上代碼,其實你會發現和上面那個配料圖表大同小異。
- """生成保質期可視化圖表"""
- def get_date_html(df):
- # 詞表分詞
- names = df.保質期.apply(jieba.lcut).explode()
- df1 = names[names.apply(len) > 1].value_counts()
- # 寫入分詞后的結果
- with pd.ExcelWriter("淘寶商品保質期數據.xlsx") as writer:
- df1.to_excel(writer, sheet_name="保質期")
- fpath = r'C:\Users\pdcfi\Desktop\淘寶數據分析\淘寶商品保質期數據.xlsx'
- # 讀取數據 提取列
- df1 = pd.read_excel(fpath, header=None, skiprows=1, names=['bzq', 'rq'])
- a = df1['bzq'].to_list()[:10]
- b = df1['rq'].to_list()[:10]
- from pyecharts.charts import Pie
- from pyecharts import options as opts
- # 繪制可視化圖表
- pie = (
- Pie()
- .add('', [list(z) for z in zip(a, b)],
- radius=["20%", "60%"], # 半徑長度
- rosetype="radius" # 扇區圓心角展現數據的百分比,半徑展現數據的大小
- )
- .set_global_opts(title_opts=opts.TitleOpts(title="淘寶商品保質期可視化圖表", subtitle="8.19"))
- .set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: owocgsc%")) # 數字項名稱和百分比
- )
- pie.render('淘寶商品保質期統計.html')
在Pycharm里邊運行代碼之后,我們將會得到一個淘寶商品保質期統計.html文件,雙擊打開該HTML文件,在瀏覽器里邊可以看到效果圖,如下圖所示。
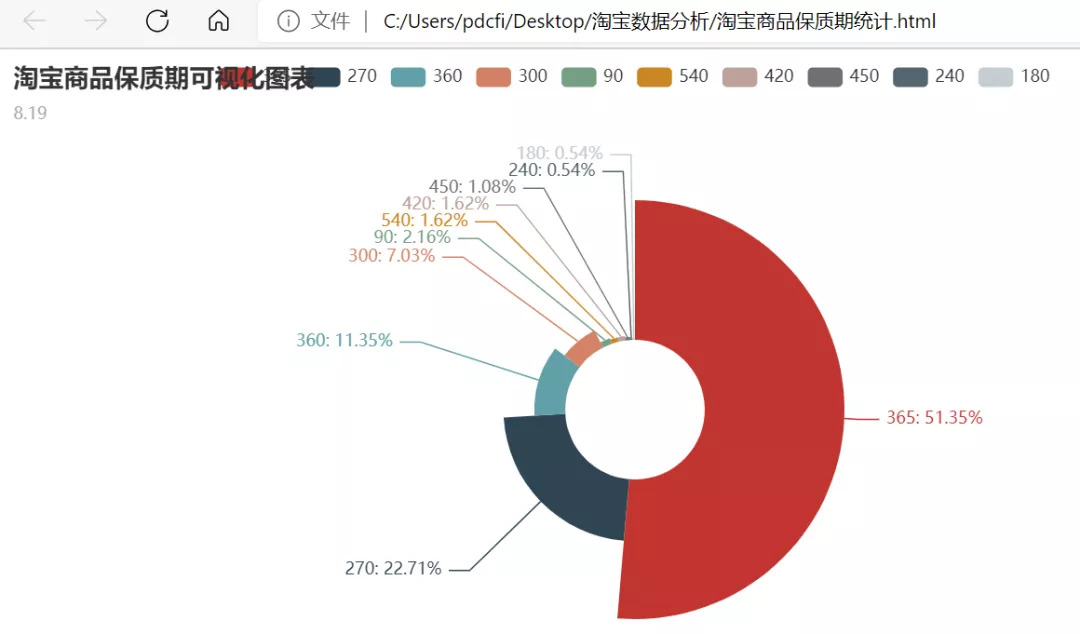
相信有小伙伴肯定感覺哪里不對,一個保質期的可視化,做成這種餅圖似乎太丑了吧?嗯,的確是丑爆了,所以程序大佬把保質期這個圖轉為了柱狀圖,這樣看上去就高大上很多了。
3、生成保質期可視化柱狀圖
其實數據都是一樣的,只不過呈現方式不同,直接上代碼。
- """生成保質期可視化圖表"""
- def get_date_html(df):
- # 詞表分詞
- names = df.保質期.apply(jieba.lcut).explode()
- df1 = names[names.apply(len) > 1].value_counts()
- # 寫入分詞后的結果
- with pd.ExcelWriter("淘寶數據.xlsx") as writer:
- df1.to_excel(writer, sheet_name="保質期")
- fpath = r'C:\Users\dell\Desktop\崔佬\數據分析綜合實戰\淘寶數據.xlsx'
- # 讀取數據 提取列
- df1 = pd.read_excel(fpath, header=None, skiprows=1, names=['bzq', 'rq'])
- a = df1['bzq'].to_list()[:50]
- b = df1['rq'].to_list()[:50]
- bar = (
- Bar(init_opts=opts.InitOpts(theme=ThemeType.CHALK))
- .add_xaxis(a)
- .add_yaxis("保質期(天數)",b)
- .set_global_opts(
- title_opts=opts.TitleOpts(title="Bar-DataZoom(slider-保質期)"),
- datazoom_opts=opts.DataZoomOpts(),
- )
- )
- return bar
這么處理之后,我們就會得到一個柱狀圖了,如下圖所示。
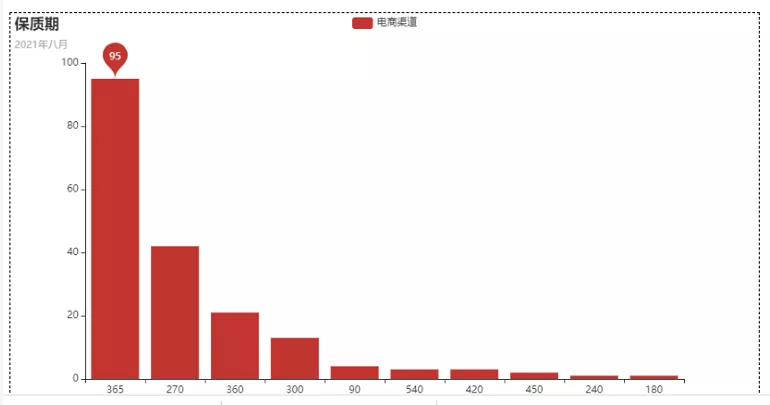
這把看上去,是不是覺得清晰很多了呢?
不過呢,程序大佬還覺得不夠,想把這兩張圖放到一起,這應該怎么辦呢?
4、合并餅圖和柱狀圖到一個HTML文件
其實這個也并不難,只需要將生成兩個圖的函數放到一個布局類里邊就可以完成了,直接上代碼。
- def page_draggable_layout(df):
- page = Page(layout=Page.DraggablePageLayout)
- page.add(
- get_ingredients_html(df),
- get_date_html(df)
- )
- page.render("page_draggable_layout.html")
如果你想在一個HTML文件里邊加入更多的圖,只需要繼續在add()函數里面進行添加生成可視化圖的函數即可。話不多說,直接上效果圖。
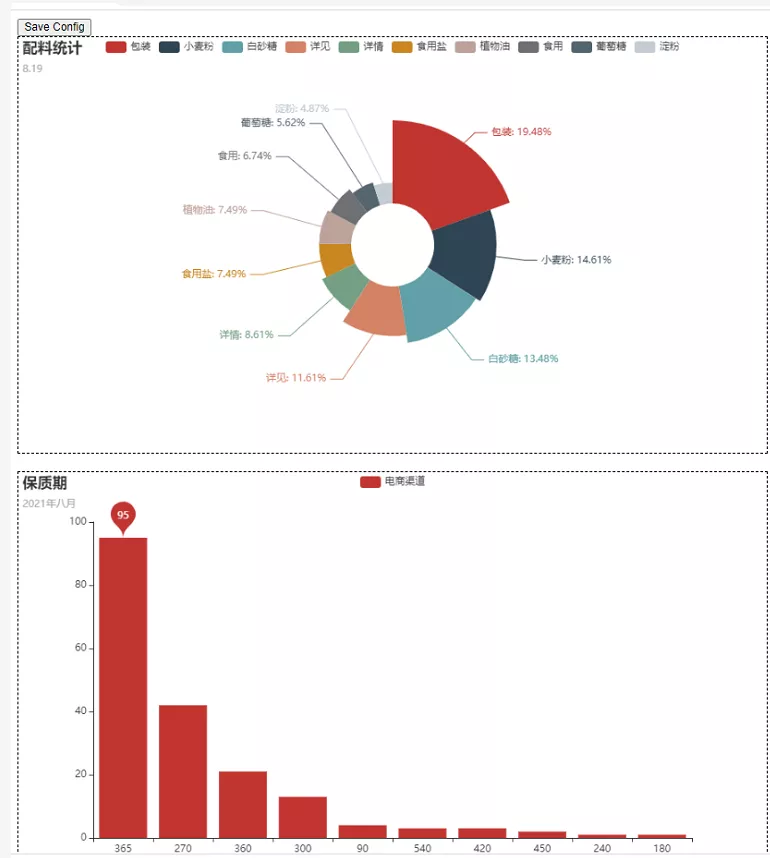
從上圖我們可以看到配料餅圖和保質期柱狀圖都同時在同一個HTML文件出現了,而且也是可以進行點擊交互的噢!我們還可以收到拖拽,讓圖表移動,如下圖所示,分為左右圖進行展示。
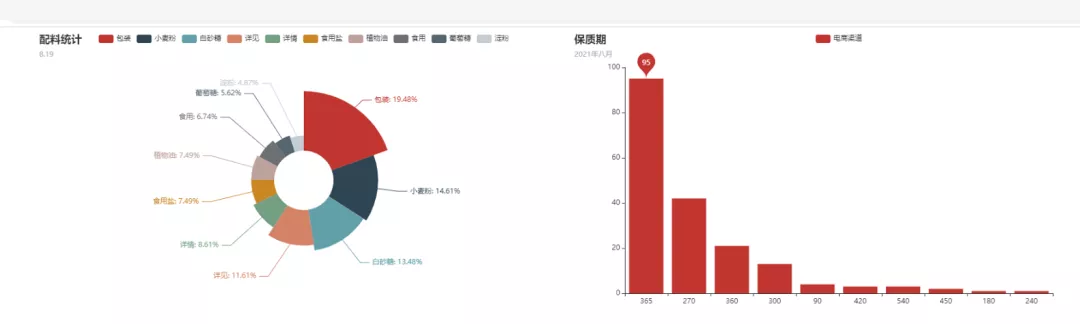
你以為到這里就結束了?其實并沒有,程序大佬還想玩點更加高大上的,他想把table表一并顯示出來,這樣顯得更加飽滿一些。那么table表又如何來進行顯示呢?
5、table表加持
其實在這里,程序大佬卡了一下,他在群里問,基于他目前的數據,像下圖這樣的df數據如何進行展示出來。
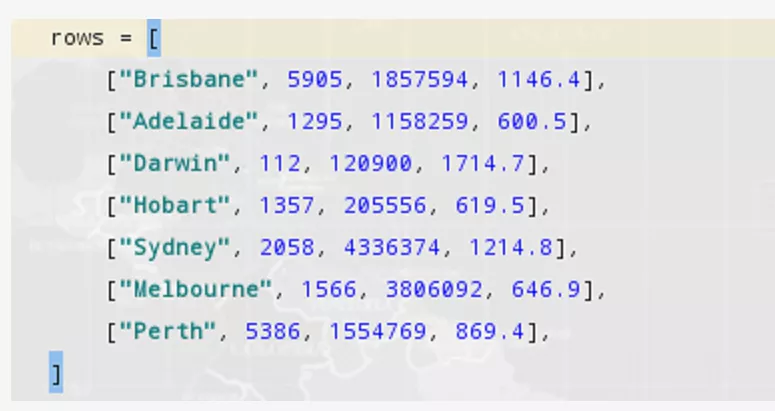
而且,他自己在不斷的嘗試中,始終報錯,一時間丈二和尚摸不著頭腦,不知如何是好。
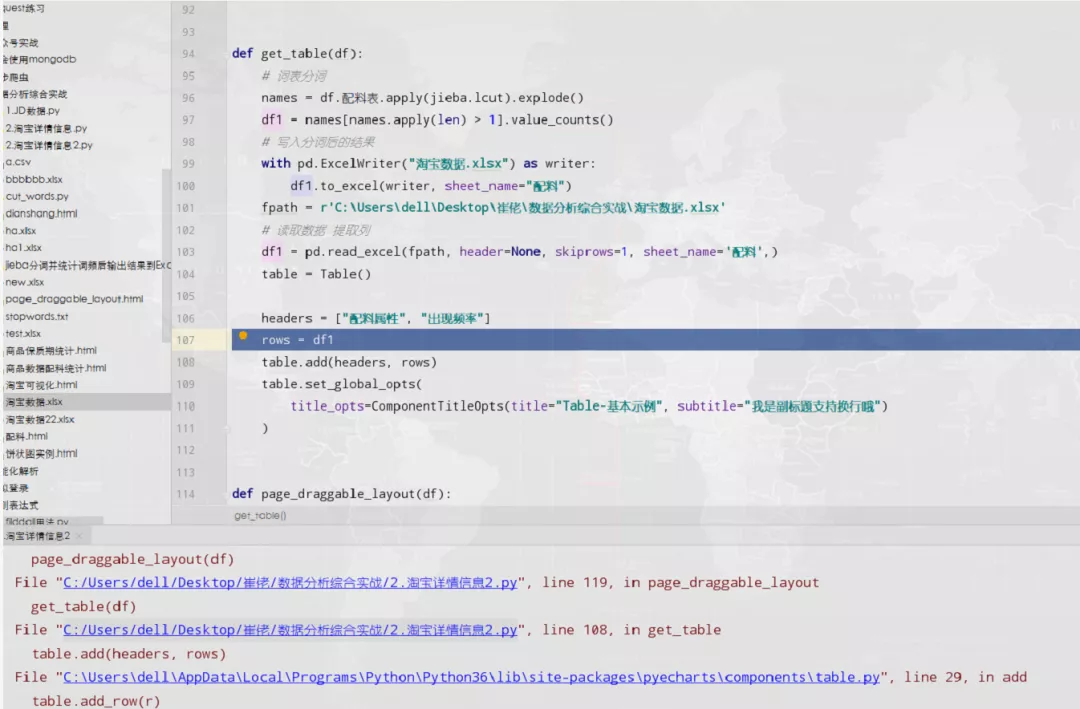
不過此時小小明大佬,又遞來了橄欖枝,人狠話不多,直接丟了兩行代碼,讓人拍手叫絕。
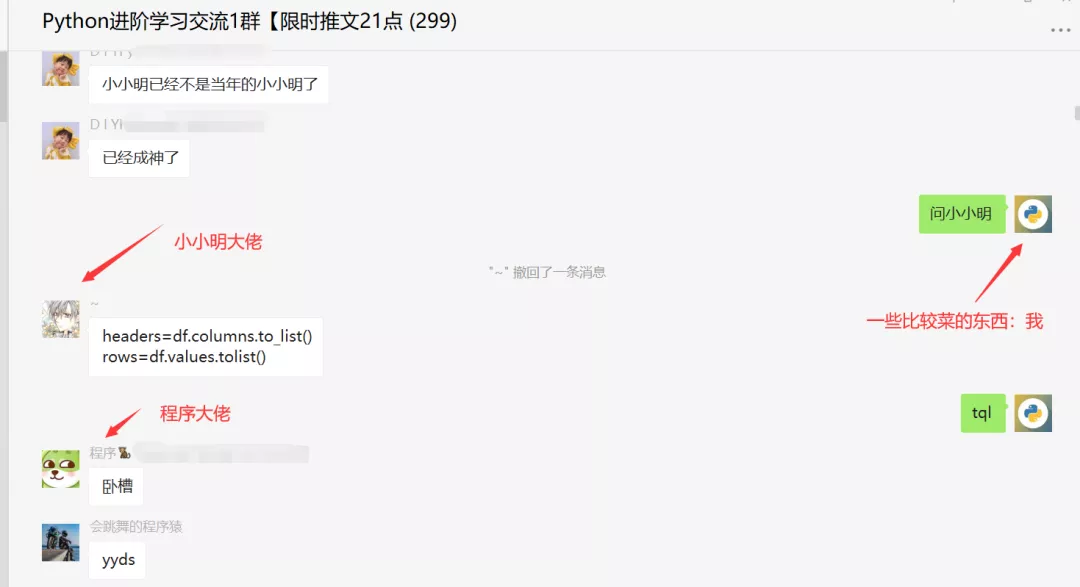
然后程序大佬,拿到Pycharm中一跑,啪,成了,真是拍案叫絕,小小明yyds!那么呈現的效果圖是下面這樣的。
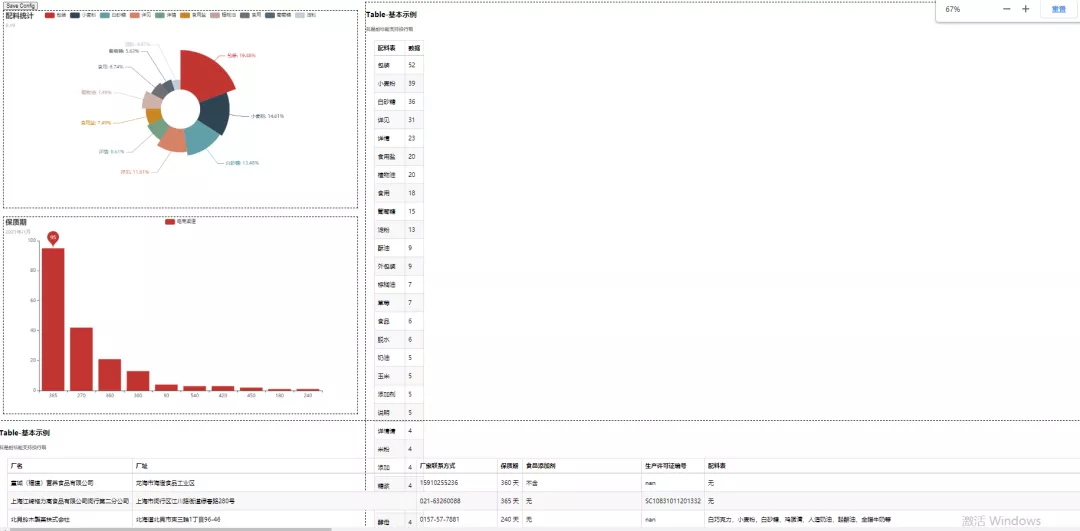
這樣看上去還稍微不太好看,拖拽下,調整下格式看看,如下圖所示。
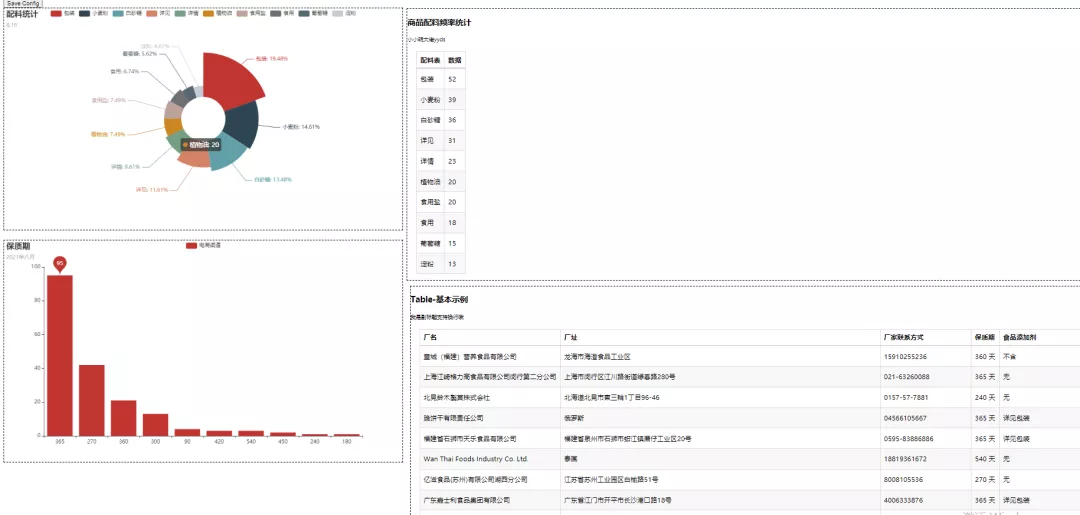
但是這樣一看,確實高大上了一些,不過還是達不到程序大佬心里的預期,于是乎他繼續折騰。
6、調整圖像背景色
現在呢,程序大佬又想要加點背景色,這樣顯得高大上一些,代碼如下。
- # 繪制可視化圖表
- pie = (
- Pie(init_opts=opts.InitOpts(theme=ThemeType.CHALK))
- .add('', [list(z) for z in zip(a, b)],
- radius=["20%", "60%"], # 半徑長度
- rosetype="radius" # 扇區圓心角展現數據的百分比,半徑展現數據的大小
- )
- .set_global_opts(title_opts=opts.TitleOpts(title="配料統計", subtitle="8.19"))
- .set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: owocgsc%")) # 數字項名稱和百分比
- )
- return pie
其實核心的那句代碼下面這個,引入了一個主題:
- init_opts=opts.InitOpts(theme=ThemeType.CHALK)
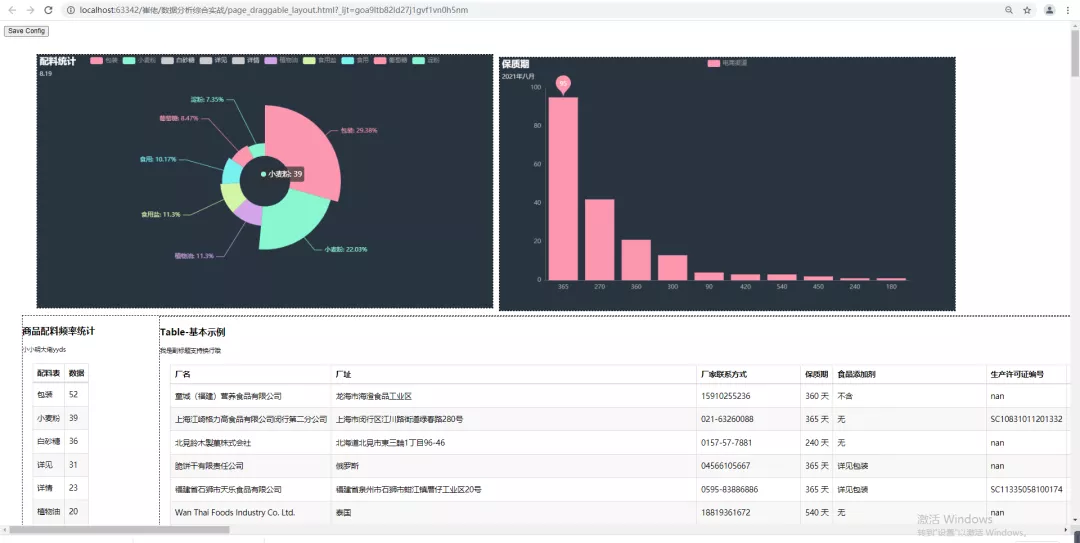
得到的效果圖如上圖所示了。
7、添加漏斗圖
這里是以數據里邊的”食品添加“列來做實例的,代碼如下所示。
- def get_sptj_data(df):
- # 詞表分詞
- names = df.食品添加劑.apply(jieba.lcut).explode()
- df1 = names[names.apply(len) > 1].value_counts()
- # 寫入分詞后的結果
- with pd.ExcelWriter("淘寶數據.xlsx") as writer:
- df1.to_excel(writer, sheet_name="食品添加劑")
- fpath = r'C:\Users\dell\Desktop\崔佬\數據分析綜合實戰\淘寶數據.xlsx'
- # 讀取數據 提取列
- df1 = pd.read_excel(fpath, header=None, skiprows=1, names=['sptj', 'sj'])
- a = df1['sptj'].to_list()[:10]
- b = df1['sj'].to_list()[:10]
- c = (
- Funnel(init_opts=opts.InitOpts(theme=ThemeType.CHALK))
- .add(
- "商品",
- [list(z) for z in zip(a, b)],
- label_opts=opts.LabelOpts(position="inside"),
- )
- .set_global_opts(title_opts=opts.TitleOpts(title="Funnel-Label(food_add)"))
- )
- return c
得到的效果圖如下圖所示。
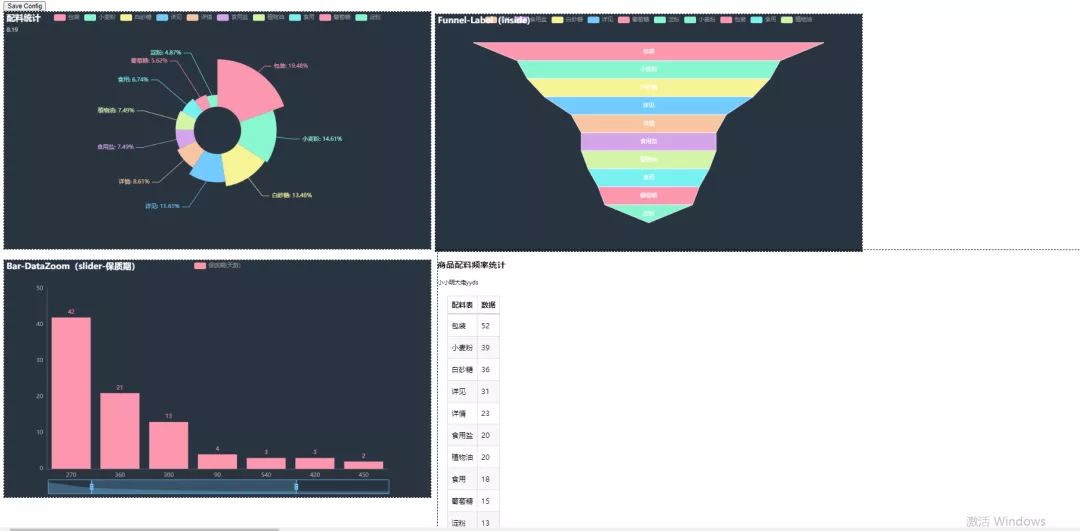
寫到這里,基本上快接近尾聲了,不過程序大佬為了感謝小小明大佬,后來又補充了一個極化裝逼圖來贊揚小小明。
8、極化圖
直接上代碼,程序大佬取的這個zb函數,就是裝13的意思,取的太沒有水平了。
- def zb_data():
- data = [(i, random.randint(1, 100)) for i in range(10)]
- c = (
- Polar()
- .add(
- "",
- data,
- type_="effectScatter",
- effect_opts=opts.EffectOpts(scale=10, period=5),
- label_opts=opts.LabelOpts(is_show=False),
- )
- .set_global_opts(title_opts=opts.TitleOpts(title="Polar-沒啥用,用來裝逼,小小明yyds"))
- )
- return c
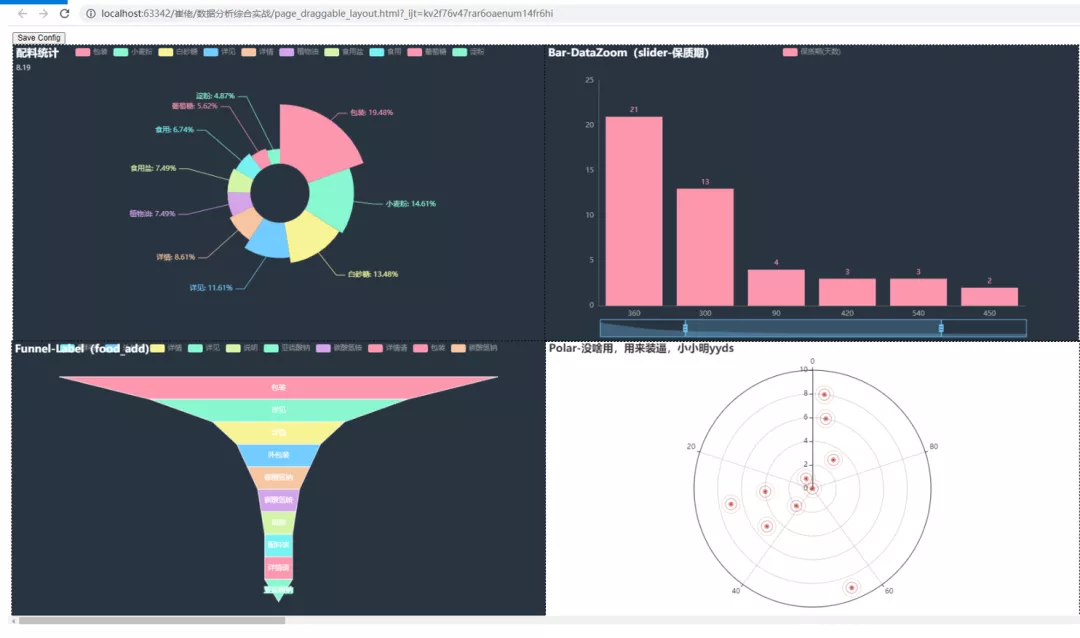
看上去確實很高大上呢。
三、總結
大家好,我是Python進階者。本文基于一份雜亂的淘寶原始數據,利用正則表達式re庫和Pandas數據處理對數據進行清洗,然后通過stop_word停用詞對得到的文本進行分詞處理,得到較為”干凈“的數據,之后利用傳統方法和Pandas優化處理兩種方式對數據進行詞頻統計,針對得到的數據,利用Pyecharts庫,進行多重可視化處理,包括但不限于餅圖、柱狀圖、Table表、漏斗圖、極化圖等,通過一系列的改進和優化,一步步達到想要的效果,可以說是干貨滿滿,實操性強,親測有效。
【編輯推薦】