谷歌大腦Quoc發布Primer,從操作原語搜索高效Transformer變體
調參、改激活函數提高模型性能已經見怪不改了。最近Google Brain的首席Quoc發布了一個搜索框架,能夠自動搜索高效率的Transformer變體,并找到一些有效的模型Primer,其中ReLU加個平方竟然能提升最多性能!
目前自然語言處理領域發展的紅利都來自于大型的、基于Transformer的語言模型,但這些語言模型的訓練成本、推理成本都高到勸退平民煉金術師。
而當模型參數量大到一定程度的時候,研究人員也在考慮如何在縮小模型的情況下,保持性能不變。
Google Brain團隊最近在arxiv 上傳了一篇論文,目標是通過尋找更高效的Transformer 變體來降低訓練和推理成本。
與之前的方法相比,新提出的方法在更低級別上執行搜索,在Tensorflow 程序的原語上定義和搜索 Transformer。并提出了一種名為 Primer 的模型架構,訓練成本比原始 Transformer 和用于自回歸語言建模的其他模型變體要更小。

https://arxiv.org/abs/2109.08668
論文的作者是大神 Quoc V. Le,在斯坦福讀博期間導師是吳恩達教授,目前是谷歌的研究科學家,Google Brain 的創始成員之一;seq2seq的作者之一;谷歌AutoML的奠基人,提出包括神經架構等方法;EfficientNet的作者等。
研究人員使用TensorFlow(TF)中的操作來構造Transformer 變體的搜索空間。在這個搜索空間中,每個程序定義了自回歸語言模型的可堆疊解碼器塊。給定輸入張量是一個長度為n且嵌入長度為d的序列,程序能夠返回相同形狀的張量。
堆疊時,其輸出表示每個序列位置的下一個token的預測embedding,并且程序只指定模型架構,沒有其他內容。換句話說,輸入和輸出embedding矩陣本身以及輸入預處理和權重優化不在這個程序的任務范圍內。
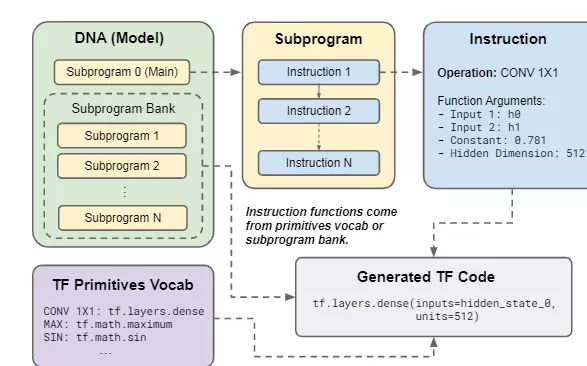
解碼器模型程序(DNA, decoder model program)定義了一個自回歸語言模型,每個DNA都有一組子程序,其中子程序0是MAIN函數的入口點。每個子程序都由指令組成,這些指令被轉換為TensorFlow代碼行。
指令操作映射到原語詞匯表中的基本TensorFlow庫函數或父DNA子程序之一,原語詞匯表由簡單的原語TF函數組成,如ADD、LOG、MATMUL等等,但像self-attention這樣的高級構建塊不是搜索空間中的操作,自注意力可以從低級操作中構建出來的。
DNA的子程序庫由附加程序組成,這些程序可以通過指令作為函數執行。每個子程序只能調用子程序庫中索引較高的子程序,這樣就消除了循環的可能性。
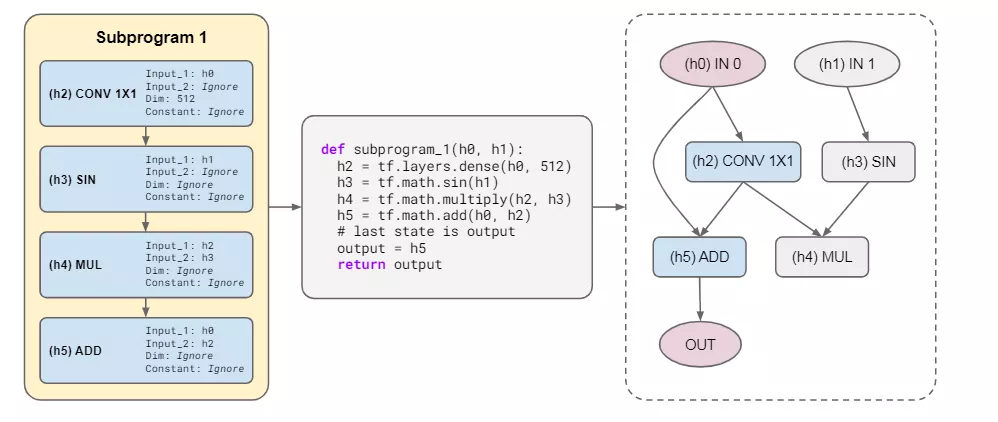
使用父指令的參數集填充操作的參數,該參數集包含所有潛在操作參數的值,參數包括Input 1( 用作第一個tensor輸入的隱藏狀態的索引)、Input 2(第二個tensor輸入的隱藏狀態的索引)、Constant(實值常數,可以用于MAX等函數)、Dimensionsize(用來表示輸出維度大小的整數)。特定操作中沒有使用的參數就直接被省略掉。
研究人員還提出進化搜索(evolutionary search),目標是在搜索空間中找到最有效的模型架構。主要方法是設計一個固定的訓練預算(使用TPUv2限時24小時),并將其適應性指標定義為Tensor2Tensor中One Billion Words Benchmark (LM1B)上的困惑度。
這些架構搜索工作的明確目標是在優化效率時減少訓練或推理步驟時間,在搜索過程中,可以發現將步長時間增加一倍、采樣效率提高三倍是一個不錯的修改方案,因為它最終使模型架構的計算效率更高。還可以將ReLUs平方化,并在注意力上增加深度卷積,從而增加訓練步長時間。
這些操作極大地提高了模型的采樣效率,通過大幅減少達到目標質量所需的訓練步驟數量,減少了達到目標性能所需的總計算量。
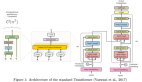
通過這個搜索程序找到的模型被研究人員命名為Primer,也就是原語搜索Transformer(PRIMitives searched transformER)。
Primer 的改進主要有平方 ReLU 激活并在自注意力中的每個 Q、K 和 V 投影后添加一個深度卷積層。
最有效的修改是將變Transformer前饋塊中的ReLU激活改進為平方ReLU激活函數,這也是第一次證明這種整流多項式激活在Transformer 中有用。并且高階多項式的有效性也可以在其他Transfomer 非線性激活函數中觀察到,例如GLU 的各種變體,ReGLU、近似GELU等。然而平方ReLU與最常用的激活功能相比 ReLU、GELU和Swish 具有截然不同的漸近性。
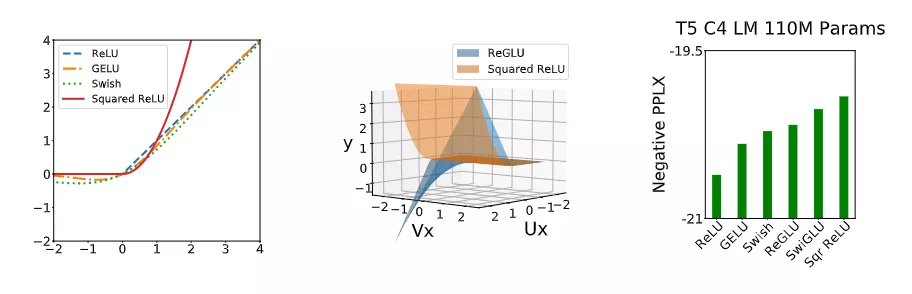
平方ReLU確實與ReGLU有顯著重疊,事實上,當ReGLU的U和V權重矩陣相同時,平方ReLU與ReLU是等效的。并且平方ReLU在更簡單的同時,也能獲得GLU變體的好處,且無需額外參數,并提供更好的質量。
研究人員使用三個Transformer 變體與Primer 進行對比:
1、Vanilla Transformer: 原始Transformer,使用ReLU激活和layer normalization。
2、Transformer+GELU: Transformer的常用變體,使用GELU近似激活函數
3、Transformer++: 使用RMS歸一化、Swish激活和GLU乘法分支在前饋反向瓶頸(SwiGLU)中。這些修改在T5 中進行了基準測試,并被表明是有效的。
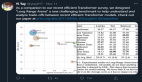
實驗表明,隨著計算規模的增長,Primer 相對于 Transformer 的收益會增加,并且在最佳模型大小下遵循與質量相關的冪律。
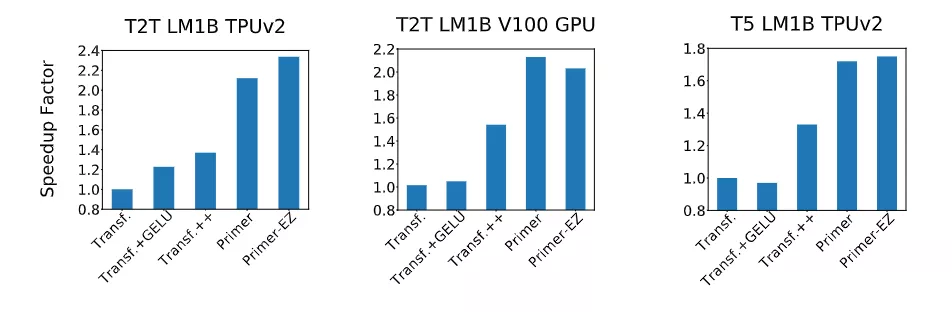
研究人員還憑經驗驗證了 Primer 可以放入不同的代碼庫,發現可以顯著加快訓練速度,而無需額外調整。例如,在 500M 的參數大小下,Primer 在 C4 自回歸語言建模上改進了原始 T5 架構,將訓練成本降低了 4 倍。
此外,降低的訓練成本意味著 Primer 需要更少的計算來達到目標one shot性能。例如,在類似于 GPT-3 XL 的 1.9B 參數配置中,Primer 使用 1/3 的訓練計算來實現與 Transformer 相同的一次性性能。
研究人員已經開源了模型,以幫助提論文可重復性。