













用上強化學習和博弈論,EA開發的測試AI成精了
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
小人不斷跳躍到實時生成的平臺上、最后到達終點……
你以為這是個類似于微信“跳一跳”的小游戲?

但它的真實身份,其實是游戲大廠EA(美國藝電公司)最新研究出的游戲測試AI。
和普通只會打游戲的AI不同,這次EA提出的新模型不僅要讓小人成功跳到終點,還要自己實時生成平臺來“為難”自己。
為什么要設計成這種“相愛相殺”的關系呢?
因為,此前的許多游戲測試AI往往會對訓練中的地圖過擬合,這導致它們在測試新地圖時的表現很差。
由此,在強化學習的基礎上,EA研究人員受到GAN的啟發,提出了這種新方法ARLPCG (Adversarial Reinforcement Learning for Procedural Content Generation)。
目前,該方法的相關論文已被IEEE Conference on Games 2021接收。
用博弈論解決過擬合
其實,把AI用到游戲測試,已經不是一件新鮮事了。
此前許多游戲測試AI都用到了強化學習。
它的特點是基于環境而行動,根據從環境中獲得的獎勵或懲罰(比如獲得積分、掉血等等)不斷學習,從而制定出一套最佳的行動策略。
不過研究人員發現,強化學習對于固定場景的泛化能力很差,往往會出現過擬合的現象。
比如在同樣的場景中,只用強化學習訓練的情況下,小人遇到陌生路徑,就會發生“集體自殺”事件:

這對于測試游戲地圖哪里出現錯誤而言,真的非常糟糕。
為此,EA的研究人員參考了GAN的原理來設計模型,讓AI內部自己對抗、優化。
具體來看,他們提出的方法ARLPCG主要由兩個強化學習智能體組成。
第一個智能體生成器 (Generator)主要負責生成游戲地圖,它使用了程序內容生成(Procedural Content Generation),這是一種可以自動生成游戲地圖或其他元素的技術。
第二個智能體是解算器 (Solver),它負責完成生成器所創建的關卡。
其中,解算器完成關卡后會獲得一定的獎勵;生成器生成具有挑戰性且可通過的地圖時,也會獲得獎勵。
訓練過程中,兩個智能體之間會相互提供反饋,讓雙方都能拿到獎勵。
最終生成器將學會創建各種可通過的地圖,解算器也能在測試各種地圖時變得更加通用。
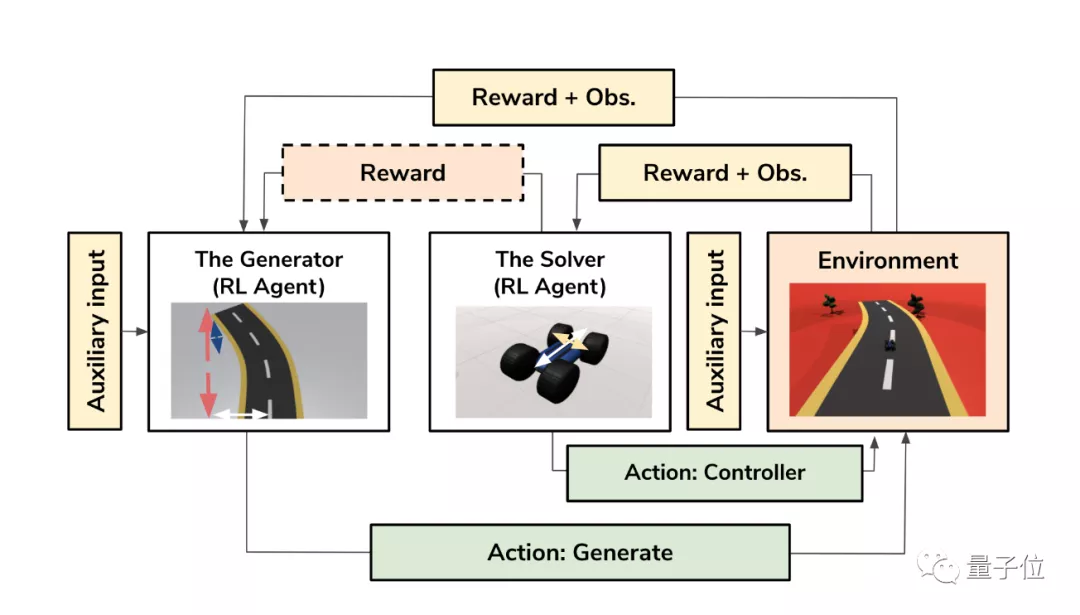
與此同時,為了能夠調節關卡難度,研究人員還在模型中引入了輔助輸入 (Auxiliary input)。
通過調節這個值的大小,他們就能控制游戲的通過率。
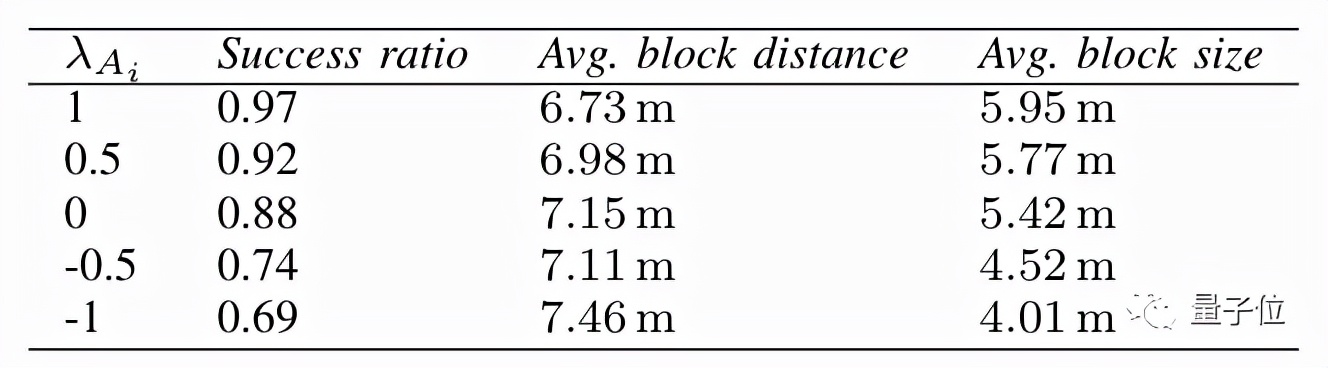
比如,將生成器的輔助輸入設為1時,它生成的平臺就會更大、間距更近,小人跳躍的難度也就更低。

當輔助輸入為-1時,生成的平臺就會變小、間距也會拉開,能夠通關的小人隨之變少。

結果顯示,在生成器的輔助輸入從1降至-1過程中,成功率從97%降低到了69%。
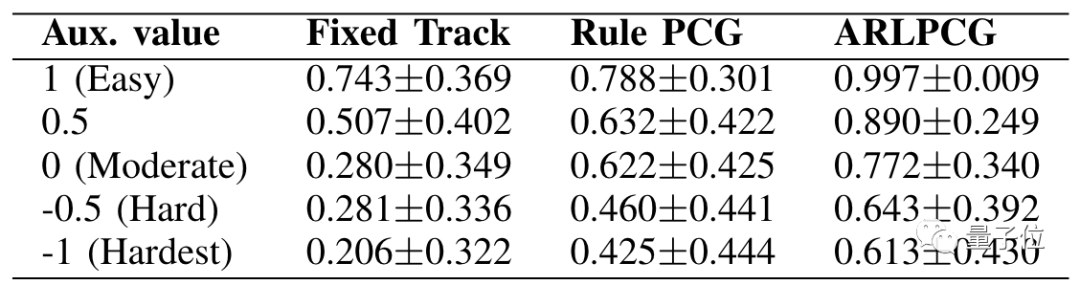
此外,也能通過調節解算器的輔助輸入值控制通過率。
在固定路徑、規則生成路徑和對抗化生成路徑幾種情況下,通過率都隨著輔助輸入的降低而降低。
其中,對抗強化生成路徑的通過率明顯高于其他兩種。
此外,因為具有對未知環境泛化的能力,這個AI訓練好后還可以被用于實時測試。
它可以在未知路段中構建出合理的通過路線,并能反饋路徑中的障礙或其他問題的位置。

此外,這個AI還能被用于不同的游戲環境,在這篇論文中,EA還展示了它在賽車游戲環境中的表現情況。

在這個場景下,生成器可以創建不同長度、坡度、轉彎的路段,解算器則變成了小車在上面行駛。
如果在生成器中添加光線投射,還能在現有環境中導航。
在這種情況下,我們看到生成器在不同障礙物之間創建行駛難度低的軌道,從而讓小車到達終點(圖中紫色的球)。

為測試大型開放游戲
論文一作Linus Gisslén表示,開放世界游戲和實時服務類游戲是現在發展的大勢所趨,當游戲中引入很多可變動的元素時,會產生的bug也就隨之增多。
因此游戲測試變得非常重要。
目前常用的測試方法主要有兩種:一種是用腳本自動化測試,另一種是人工測試。
腳本測試速度快,但是在復雜問題上的處理效果不好;人工測試剛好相反,雖然可以發現很多復雜的問題,但是效率很低。
而AI剛好可以把這兩種方法的優點結合起來。

事實上,EA這次提出的新方法非常輕便,生成器和求解器只用了兩層具有512個單元的神經網絡。
Linus Gisslén解釋稱,這是因為具有多個技能會導致模型的訓練成本非常高,所以他們盡可能讓每個受過訓練的智能體只會一個技能。
他們希望之后這個AI可以不斷學習到新的技能,讓人工測試員從無聊枯燥的普通測試中解放出來。
此外EA表示,當AI、機器學習逐漸成為整個游戲行業使用的主流技術時,EA也會有充分的準備。
論文鏈接:
https://arxiv.org/abs/2103.04847
參考鏈接:
[1]https://venturebeat.com/2021/10/07/reinforcement-learning-improves-game-testing-ai-team-finds/
[2]https://www.youtube.com/watch?v=z7q2PtVsT0I
























