













AI大牛周明打造輕量“孟子模型”開源!靠10億參數沖上CLUE榜第三
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
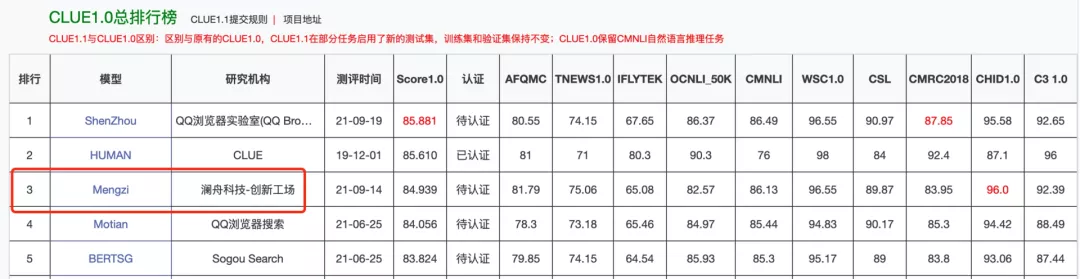
只用10億參數就殺進中文自然語言理解CLUE榜單前三的孟子模型,現在開源了!
其打造團隊瀾舟科技-創新工場最新宣布,基于孟子通用模型,他們將開源4個模型。
分別可用于文本分類、金融新聞分類、文案生成和圖片描述等場景。
今年7月,這個由AI大牛周明率隊打造的輕量級模型,一經發布就驚艷眾人。
它以十億參數完成此前百億、千億參數模型創造的紀錄,打破近年來CLUE榜單被騰訊、搜狗、華為、阿里達摩院輪番霸榜的格局。
截至目前,孟子模型仍舊是榜單前五中唯一非巨頭企業推出的模型,且排名第三。
下游任務表現出色
CLUE榜單可是自然語言理解玩家的必爭之地,騰訊、搜狗、華為、阿里達摩院等更是輪番霸榜刷新紀錄。
而他們的大模型動輒就是百億、千億級的參數,僅僅只有10億參數的孟子模型,到底是如何殺出重圍的呢?
我們不妨來了解一下孟子模型。
孟子模型是瀾舟科技基于語言學信息融入和訓練加速等方法,研發的系列模型。
由于與BERT保持一致的模型結構(Transformer),孟子模型可以快速替換現有的預訓練模型。
它可處理多語言、多模態數據,同時支持多種文本理解和文本生成任務,在文本分類、閱讀理解等各類任務上表現出色。
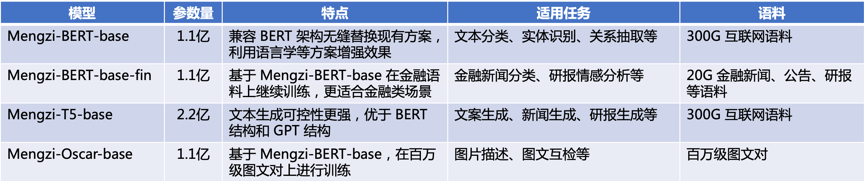
具體來看,這次開源的4個模型架構如下:
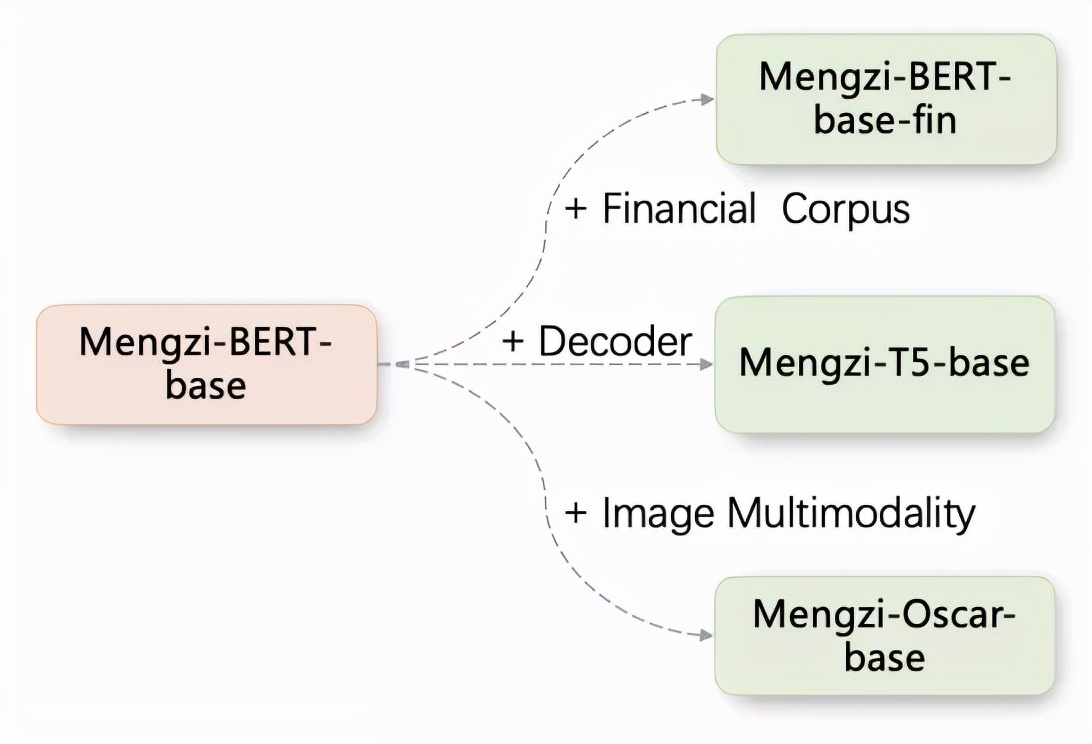
對應各個場景來看,在金融方面的任務中,孟子模型表現優秀:

生成營銷文案上,相對于GPT而言,孟子模型能夠生成的語言明顯更為豐富。
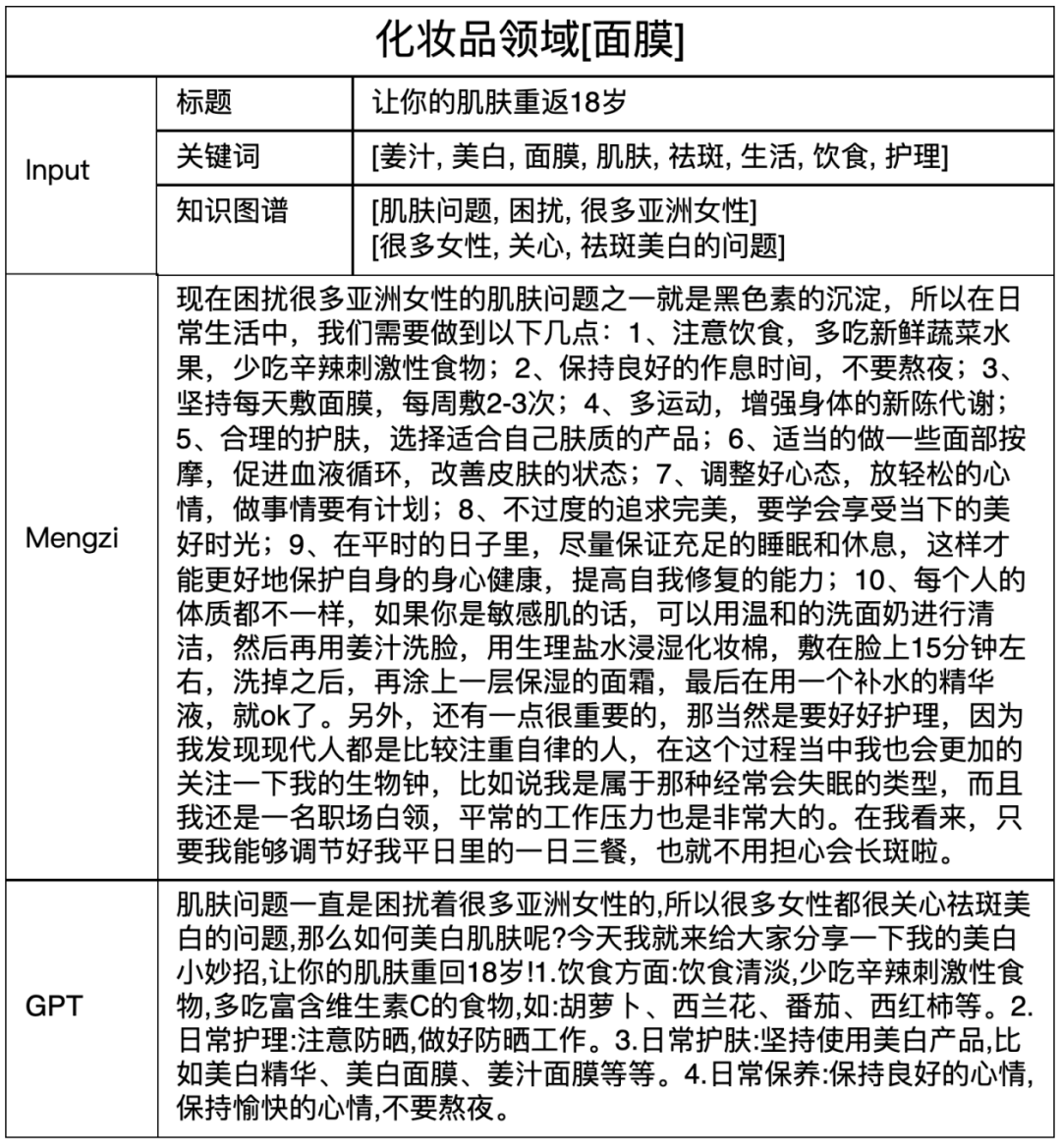
描述圖片內容上也更為準確、細致,幾乎看不出AI的痕跡。

四兩撥千斤
與其他中文語言模型相比,孟子模型最大的特點就是小而精。
它采用輕量化訓練策略,致力于構建十億參數級別的小模型,充分發揮已有參數下的模型潛力,有利于快速、低成本的落地現實業務場景。
與此同時,孟子還使用人類先驗知識引導模型訓練,讓模型更高效率獲得知識。
孟子模型具備頂尖的語言理解能力,在權威CLUE中文理解評測的總排行榜,分數突破84分,逼近人類基準分數(85.61)。
另外,基于T5-style的端到端生成的訓練范式,同步適配BERT-style的判定式架構,讓孟子模型便于適配行業應用,可以覆蓋廣泛業務場景。
在模型架構上,“孟子”也進行了全方位改進。

具體有四方面:
- 模型結構方面,將語義角色、詞性標注等語言學特征融合到Embedding表示中,基于句法約束引入注意力機制中,從而提升模型對語言學知識的建模能力。
- 訓練策略上,引入基于實體知識和Discourse的Mask機制,強化模型對語言成分和語篇關系的表征。
- 為進一步提高訓練效率,使用了大模型蒸餾和初始化小模型策略。
- 為更好地將孟子模型適應垂直領域如金融、營銷,使用了領域數據繼續訓練并構造相應的提示模版(Prompt),取得了明顯的性能提升。
周明:未來十年孕育認知智能大機遇
最后,我們再來介紹一下孟子模型的幕后團隊——瀾舟科技。
它是由創新工廠孵化的一家認知智能公司。
公司創始人——周明博士。
AI領域內,周明已不用過多介紹,他是公認的世界級AI科學家,自然語言處理領域的代表性人物。
周明博士在2020年加盟創新工場,擔任創新工場首席科學家。
就在剛剛開幕的2021杭州·云棲大會上,我們也看到了周明博士的身影。
基于自己多年的產學研認識,他分享了自己對于認知智能的一些思考。

周明博士提到,目前神經網絡的方法依賴大規模的標注數據做端到端訓練。這種黑箱式系統缺乏解釋能力、也不具備常識推理能力。
我們人腦在處理熟悉任務的時候,都是依賴直覺的,這有點對應預訓練模型或者深度學習;
在處理新事物時,人腦就要沉靜下來,用自己的知識去推理,這更像是符號計算。
他認為,當下的深度學習應該思考如何用一個模型將這二者的優勢結合,也就是把數據和知識融合起來解決問題。
此外周明博士還提出,現在深度學習訓練新任務,要學習所有的能力。但人類在應對新任務時,往往只是基于基礎能力做了小部分的調整。
所以,如何模擬人腦、設計一系列基礎能力和相應微調機制,是深度學習要思考的問題。
提及對AI行業的展望,周明博士表示:
AI正由感知智能快速向認知智能邁進,未來的十年孕育著巨大的認知智能發展和創新的機遇。
與此同時,他還在分享中透露,瀾舟科技從開源起步,正在過渡到SaaS、訂制和App。目前已與國內外幾十所著名高校和十余個相關領域的頭部企業建立了穩定的合作關系。
傳送門
目前,瀾舟科技已經發布了項目開源地址和技術報告,地址如下:
項目地址:https://github.com/Langboat/Mengzi
技術報告:https://arxiv.org/abs/2110.06696





























