













?GPT-3好“搭檔”:這種方法緩解模型退化,讓輸出更自然
文本生成對于許多自然語言處理應用來說都是非常重要的。
但神經語言模型的基于最大化的解碼方法(如 beam search)往往導致退化解,即生成的文本是不自然的,并且常常包含不必要的重復。現有的方法通過采樣或修改訓練目標來引入隨機性,以降低某些 token 的概率(例如,非似然訓練)。然而,它們往往導致解決方案缺乏連貫性。
近日,來自劍橋大學、香港中文大學、騰訊 AI 實驗室和 DeepMind 的科學家們證明,自然語言生成模型出現退化現象的一個潛在原因是 token 的分布式表示向量存在各向異性。
他們進一步提出了一個基于對比學習的自然語言生成框架。在兩種語言的三個基準測試上進行的大量實驗和分析表明,該方法在人工評估和自動評估兩個方面上優于目前最先進的文本生成方法。
研究動機與主要研究內容
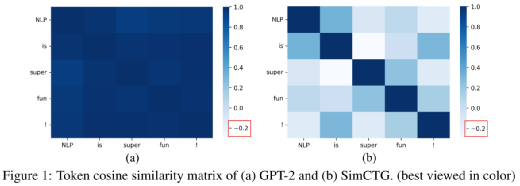
圖1. Token 表示向量的 cosine 相似度矩陣
這項研究中,研究團隊發現,神經語言模型的退化源于 token 表示向量的各向異性分布,即它們的表示向量駐留在整個空間的一個狹窄子集中。
圖1(a)展示了 token 表示向量的 cosine 相似度矩陣,其中表示向量來源于 GPT-2 的最后一個隱層的輸出。研究團隊看到句子中 token 之間的余弦相似度超過 0.95,這意味著這些表征彼此十分接近。
在理想情況下,模型的 token 表示應遵循各向同性分布,即 token 相似度矩陣應是稀疏的,不同 token 的表示應是有區別的,如圖2(b)所示。在解碼過程中,為了避免模型退化,需要保留生成文本的 token 相似矩陣的稀疏性。
基于上述動機,研究團隊提出了 SimCTG(一個簡單的神經文本生成對比框架),該框架鼓勵模型學習有區分度的、各向同性的 token 表示。
對比搜索背后的關鍵直覺是:
(1)在每個解碼步驟,輸出應該從組中選擇最有可能的候選詞的預測模型,以更好地維護生成的文本之間的語義一致性;
(2)token 相似矩陣的稀疏性應該保持以避免退化。
主要方法
- 對比訓練
研究團隊的目標是鼓勵語言模型學習有區別且各向同性的 token 表示。為此,在語言模型的訓練中引入了一個對比損失函數 LCL。給定任意一個變長序列 x,該對比損失函數定義為:
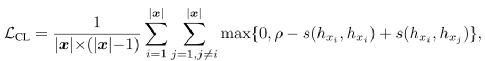
其中,ρ 是預先設定的 margin,hxi 是模型輸出的 xi 的表示向量。相似度函數 s 計算任意兩個表示向量之間的余弦相似度:
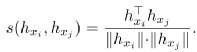
可以想象,通過訓練上述對比損失函數,不同 token 的表示間的距離將被拉開。因此,可以得到一個可分的、各向同性的模型表示空間。最終的總損失函數為:
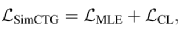
- 對比搜索
研究團隊提出一種新的解碼方法:對比搜索(contrastive search)。每一步解碼時,(1)模型從最可能的候選集合中選出一個作為輸出,(2)產生的輸出應當與前面已經生成的內容足夠不同。這種方式下生成的文本在保持與前文的語義一致性的同時還能避免模型退化。具體來說,輸出 xt 的生成滿足:

其中 V(k) 是候選詞集合,k 通常取 3 到 10。上式的第一項代表模型對 v 的支持度 v(model confidence),是模型估計的候選詞 v 為下一個詞的概率。第二項是對模型退化的懲罰項(degeneration penalty)是下一個詞 v 與前面已生成的詞的相似度最大值。α 是超參數,負責調節兩項損失之間的平衡。當 α=0 時,解碼方法退化到貪婪搜索。
效率分析:該方法可以有效地實現對比搜索。所需的額外計算是退化罰的計算,該計算可以通過簡單的矩陣乘法來實現。后文將證明,對比搜索的譯碼速度優于或可與其他廣泛應用的譯碼方法相媲美。
文本生成
首先在開放式文本生成任務(open-ended document generation)上評價研究團隊所提出的新方法。
模型和基線 本文提出的方法與模型結構無關,因此可以應用于任何生成模型。在這項實驗中,他們在具有代表性的 GPT-2 模型上評估了所提出的方法。
具體來說,研究團隊在評估基準(詳細如下)上使用提出的目標 LSimCTG 對 GPT-2 進行了調優,并使用不同的解碼方法生成連續文本。使用基礎模型(117 M 參數)進行實驗,該模型由 12 個 Transformer 層和 12 個 attention head 組成,將本方法與兩個強基線方法進行比較:
(1)GPT-2 在標準 MLE 損失函數上微調;(2)利用非似然目標函數微調。研究團隊的實現基于 Huggingface 庫(Wolf 等人,2019)。
基準數據集 研究團隊在 Wikitext-103 數據集(Merity 等人, 2017)上進行了實驗,該數據集包含了一個包含超過 1 億單詞。Wikitext-103 是一個文檔級數據集,已被廣泛用于大規模語言建模的評估。
評價指標
研究團隊從兩個方面進行評價:
(1)語言建模質量,衡量模型的內在質量;
(2)生成質量,用來衡量生成文本的質量。
l 語言建模質量
n 困惑度
n 預測準確率
n 預測重復率
l 文本生成質量
n 生成重復度
n 多樣性
nMAUVE(一種度量機器生成文本與人類生成文本間相近程度的指標;MAUVE 越高,機器文本越像人類文本)
n 語義連貫性
n 生成文本的困惑度
實驗結果
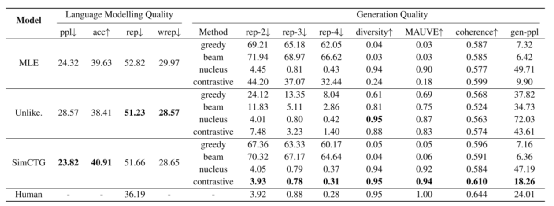
表1. 多種方法在 Wikitext-103 數據集上的測試結果
表1 展示了 Wikitext-103 數據集上的實驗結果。
語言建模質量 從結果來看,SimCTG 獲得了最好的困惑度和下一個 token 預測準確率。因為其使用了更有區分度的分布式表示,SimCTG 在進行下一個 token 預測時更不容易混淆,從而提高了模型性能。在 rep 和 wrep 度量上,非似然模型產生了最好的結果,但代價是復雜性和下一個 token 預測準確性方面的性能下降。
文本生成質量
首先,在 rep-n 和多樣性指標上,SimCTG+對比搜索獲得了最好的性能,表明它最好地解決了模型退化問題。其次,MAUVE 分數表明 SimCTG+對比搜索生成的文本在令牌分布方面與人類編寫的文本最接近。第三,在所有方法中,SimCTG+對比搜索是唯一一種一致性得分在 0.6 以上的方法,表明該方法生成的文本質量高,且相對于前綴而言語義一致。最后,gen-ppl 度量也驗證了 SimCTG+對比搜索的優越性,因為與其他方法相比,它獲得了明顯更好的生成困惑度。
此外,從 MLE 和 Unlikelihood 基線的結果來看,對比搜索仍然比貪婪搜索和 beam 搜索帶來了額外的性能提升。然而,對比訓練的性能提高仍然滯后于 SimCTG,這說明了對比訓練的必要性。一個可能的原因是,沒有對比損失 LCL,MLE 或 unlikelihood 訓練出來的 token 表示不具備充分的可區分性。因此,不同候選對象的退化懲罰不易區分,輸出的選擇受模型置信度的影響,使得對比搜索的有效性降低。
人工評價
研究團隊還通過內部評分平臺,在高英語水平學生的幫助下進行了人工評價。所有生成文本和真實的后文放在一起隨機打亂,然后由 5 個人類評分者評估,最終產生總共 9000 個標注樣本。評估遵循李克特 5 點量表(1、2、3、4 或 5),從以下三個方面進行打分:
- 連貫性:生成的文本是否與前文在語義上保持一致
- 流暢性:生成的文本是否易讀
- 信息量:生成的文本是否多樣,是否包含有趣的內容
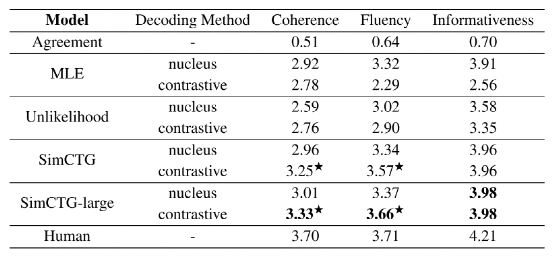
表2. 文本生成的人工評價
表2 給出了人工評價結果,其中第一行顯說明了人類評價能夠很好的發現參考文本。首先,研究團隊發現直接使用 MLE 或 Unlikelihood 模型進行對比搜索并不能得到滿意的結果。這是由于它們表示空間的各向異性。第二,Unlikelihood 模型的一致性得分明顯低于 MLE 和 SimCTG,表明其產生的結果最不可能,這從表1 的 generation perplexity(gen-ppl)中也可以看出。此外,SimCTG +對比搜索結果在一致性和流暢性方面明顯優于不同模型的核抽樣。
最后,SimCTG-large +對比搜索獲得了全面的最佳性能,甚至在流暢度指標上與人類書寫的文本表現相當。這揭示了該方法對于大型模型的通用性,未來的工作可以集中于將其擴展到包含超過數十億參數的模型,如 GPT-3。
開放式對話系統
為了測試這個方法在不同任務和語言中的通用性,本文還在開放域對話生成任務中評估了研方法。在這個任務中,給定一個多回合對話上下文(每個回合都是一個用戶的話語),要求模型生成一個語義上與上下文一致的適當的響應。在這里,對話語境被視為前文。
基線模型和基準測試集 研究在中文和英文兩種語言的兩個基準數據集上進行了實驗。中國數據集方面,使用 LCCC 數據集(Wang 等人,2020)。英語數據集方面,則使用 DailyDialog 數據集。
研究團隊比較了通過 SimCTG 和 MLE 微調的 GPT-2 模型。具體來說,對于中文基準數據集,使用了一個公開可用的中文 GPT-2(Zhao 等人,2019)。在訓練期間,使用 128 作為 batch size,并將訓練樣本截斷為最大長度 256 個 token。在 LCCC 數據集上,對模型進行 40k 步的訓練(即微調)。對于 DailyDialog 數據集,由于其數據集較小,將模型訓練 5k 步。優化方面,使用 Adam 優化器和 2e-5 的學習率。
模型評價 研究團隊依靠人工評價來衡量模型的性能,從測試集中隨機選取了 200 個對話上下文,請 5 位標注者從三個維度:連貫性、流暢性和(3)信息量,分別進行打分。分數遵循李克特 5 分量表(1、2、3、4 或 5)。
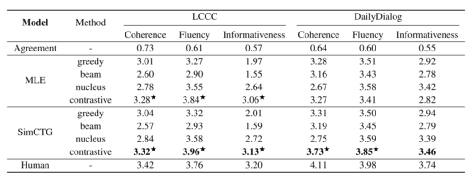
表3. 開放式對話的人工評價
表3 展示了開放式對話的人工評價結果。在這兩個數據集上, SimCTG +對比搜索在各種指標上顯著優于其他方法,這表明該方法可推廣到不同的語言和任務上。值得強調的是,在 LCCC 基準測試中,SimCTG +對比搜索在流暢度指標上的表現出人意料地優于人類,而在連貫性和信息量指標上的表現也相當不錯。
并且,即使不進行對比訓練,MLE 模型在使用對比搜索時的性能也顯著提高。這是由于漢語語言模型的固有屬性,MLE 目標已經可以產生一個表現出高度各向同性的表示空間,使得對比搜索可以直接應用。這一發現尤其具有吸引力,因為它揭示了對比搜索在現成語言模型(即不進行對比訓練)上的潛在適用性,適用于某些語言,如漢語。
總結
這項研究中,作者們證明了神經語言模型的退化源于它們的 token 表示的各向異性性質,并提出了一種新的方法——SimCTG,用于訓練語言模型,使其獲得一個各向同性且有區分度的表示空間。此外,研究還介紹了一種新的解碼方法——對比搜索,該方法與本文所提出的 SimCTG 目標一致。基于在兩種語言的三個基準測試集上進行的廣泛實驗和分析,自動和人工評價都表明了,本文所提的方法大大削弱了模型退化程度,顯著優于當前最先進的文本生成方法。























