













Flink SQL 知其所以然之去重不僅僅有 Count Distinct 還有強大的 Deduplication
1.序篇
源碼公眾號后臺回復1.13.2 deduplication 的奇妙解析之路獲取。
下面即是文章目錄,也對應到了本文的結論,小伙伴可以先看結論快速了解博主期望本文能給小伙伴們帶來什么幫助:
- 背景及應用場景介紹:博主期望你了解到,flink sql 的 deduplication 其實就是 row_number = 1,所以它可以在去重的同時,還能保留原始字段數據
- 來一個實戰案例:博主以一個日志上報重復的場景,來引出下文要介紹的 flink sql deduplication 解決方案
- 基于 Deduplication 的解決方案及原理解析:博主期望你了解到,deduplication 中,當 row_number order by proctime(處理時間)去重的原理就是給每一個 partition key 維護一個 value state。如果當前 value state 不為空,則說明 id 已經來過了,當前這條數據就不用下發了。如果 value state 為空,則 id 還沒還沒來過,把 value state 標記之后,把當前數據下發。
- 總結及展望篇
2.背景及應用場景介紹
你是否遇到過一下的場景:
由于上游發過來的數據有重復或者日志源頭數據有重復上報,導致下游計算 count,sum 時算多
想做到去重計算的同時,原始表的所有字段還能正常保留且下發
那么你能想到哪些解決方案呢?
熟悉離線計算的小伙伴可能很快就能給出答案。沒錯,hive sql 中的 row_number = 1。flink sql 中也是提供了一模一樣的功能,xdm,完美的解決這個問題。
下面開始正式篇章。
3.來一個實戰案例
先來一個實際案例來看看在具體輸入值的場景下,輸出值應該長啥樣。
場景:埋點數據上報的的字段有 id(標識唯一一條日志),timestamp(事件時間戳),page(時間發生的當前頁面),param1,param2,paramN...。但是日志上報時由于一些機制導致日志上報重復,下游算多了,因此需要做一次去重,下游再去消費去過重的數據。
來一波輸入數據:
| id | timestamp | page | param1 | param2 | paramN |
|---|---|---|---|---|---|
| 1 | 2021-11-01 00:01:00 | A | xxx1 | xxx2 | xxxN |
| 1 | 2021-11-01 00:01:00 | A | xxx1 | xxx2 | xxxN |
| 2 | 2021-11-01 00:01:00 | A | xxx3 | xxx2 | xxxN |
| 2 | 2021-11-01 00:01:00 | A | xxx3 | xxx2 | xxxN |
| 3 | 2021-11-01 00:03:00 | C | xxx5 | xxx2 | xxxN |
其中第二條和第四條是重復上報的數據,則預期輸出數據如下:
| id | timestamp | page | param1 | param2 | paramN |
|---|---|---|---|---|---|
| 1 | 2021-11-01 00:01:00 | A | xxx1 | xxx2 | xxxN |
| 2 | 2021-11-01 00:01:00 | A | xxx3 | xxx2 | xxxN |
| 3 | 2021-11-01 00:03:00 | C | xxx5 | xxx2 | xxxN |
4.基于 Deduplication 的解決方案及原理解析
4.1.sql 寫法
還是上面的案例,我們來看看最終的 sql 應該怎么寫:
- select id,
- timestamp,
- page,
- param1,
- param2,
- paramN
- from (
- SELECT
- id,
- timestamp,
- page,
- param1,
- param2,
- paramN
- -- proctime 代表處理時間即 source 表中的 PROCTIME()
- row_number() over(partition by id order by proctime) as rn
- FROM source_table
- )
- where rn = 1
上面的 sql 應該很好理解。其中由于我們并不關心重復數據上報的時間前后,所以此處就直接使用 order by proctime 進行處理,按照數據來的前后時間去第一條。
4.2.proctime 下 flink 生成的算子圖及 sql 算子語義
算子圖如下所示:
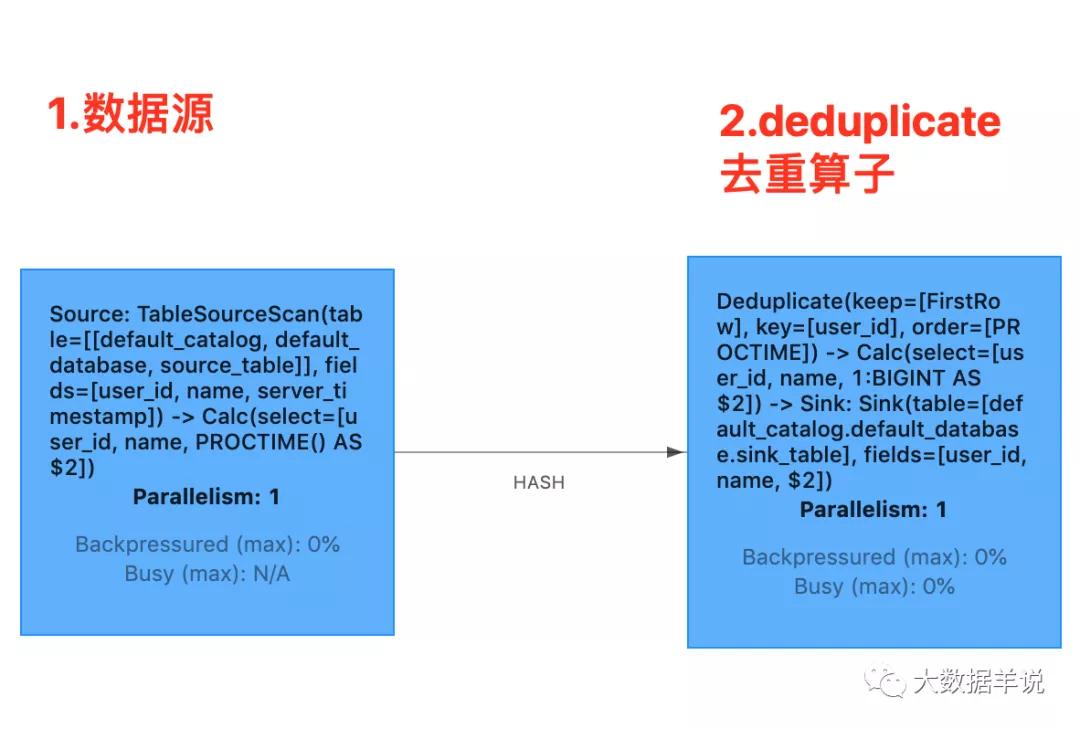
deduplication
- source 算子:source 通過 keyby 的方式向 deduplication 算子發數據時,其中 keyby 的 key 就是 sql 中的 id
- deduplication 算子:deduplication 算子為每一個 partition key 都維護了一個 value state 用于去重。每來一條數據時都從當前 partition key 的 value state 去獲取 value, 如果不為空,則說明已經有數據來過了,當前這一條數據就是重復數據,就不往下游算子下發了, 如果為空,則說明之前沒有數據來過,當前這一條數據就是第一條數據,則把當前的 value state 值設置為 true,往下游算子下發數據
4.3.proctime 下 deduplication 原理解析
具體的去重算子為 deduplication。我們通過 transformation 可以看到去重算子為下圖所示:
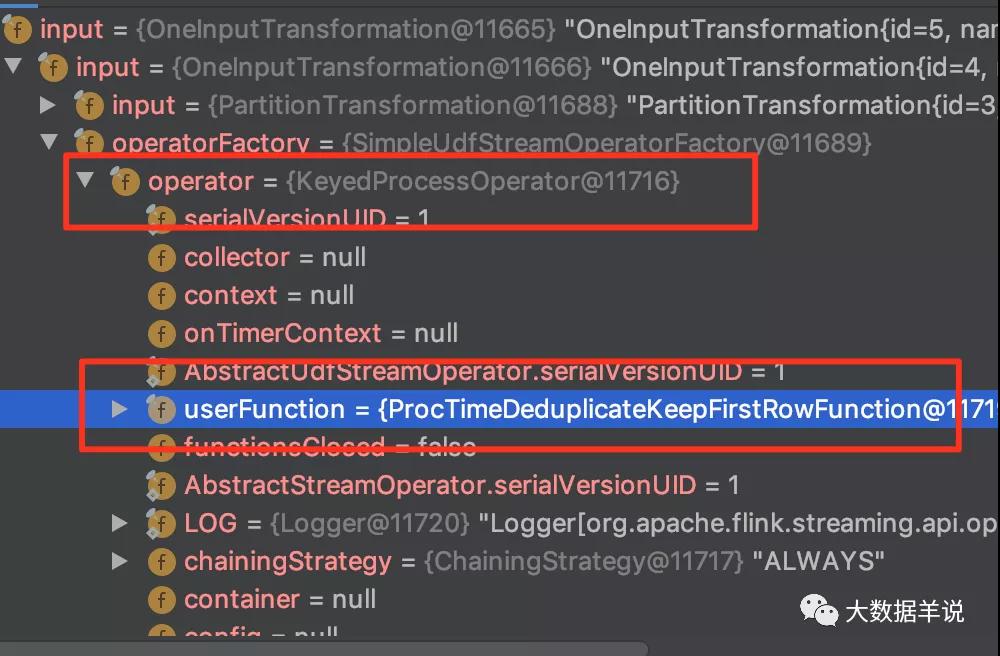
transformation
上述的去重邏輯集中在 org.apache.flink.table.runtime.operators.deduplicate.ProcTimeDeduplicateKeepFirstRowFunction 的 processFirstRowOnProcTime,如下圖所示:
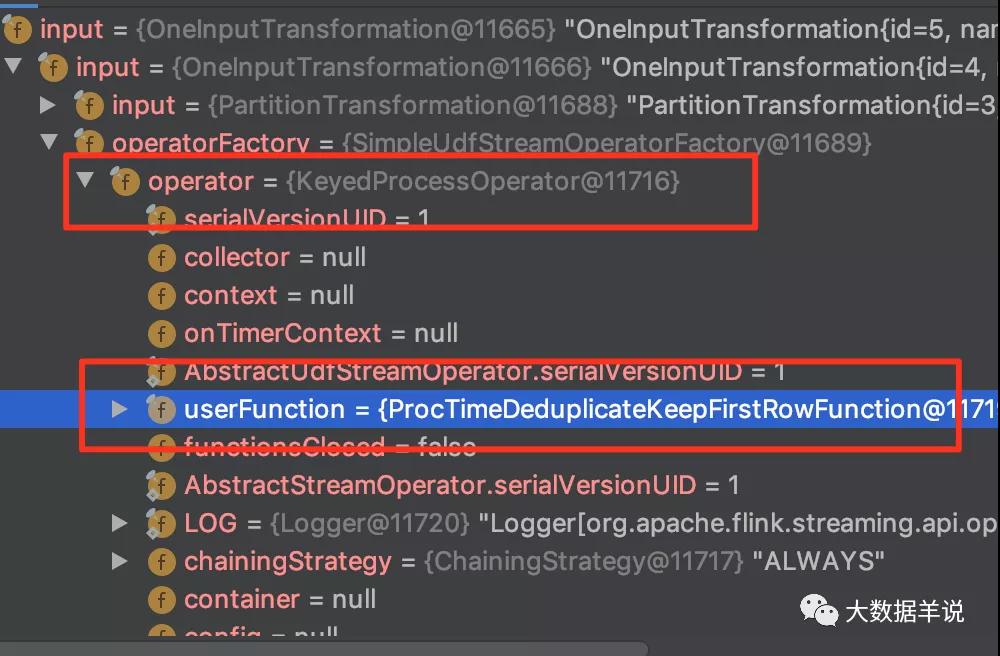
ProcTimeDeduplicateKeepFirstRowFunction
5.總結與展望
源碼公眾號后臺回復1.13.2 deduplication 的奇妙解析之路獲取。
本文主要介紹了 deduplication 的應用場景案例以及其運行原理,主要包含下面兩部分:
背景及應用場景介紹:博主期望你了解到,flink sql 的 deduplication 其實就是 row_number = 1,所以它可以在去重的同時,還能保留原始字段數據
來一個實戰案例:博主以一個日志上報重復的場景,來引出下文要介紹的 flink sql deduplication 解決方案
基于 Deduplication 的解決方案及原理解析:博主期望你了解到,deduplication 中,當 row_number order by proctime(處理時間)去重的原理就是給每一個 partition key 維護一個 value state。如果當前 value state 不為空,則說明 id 已經來過了,當前這條數據就不用下發了。如果 value state 為空,則 id 還沒還沒來過,把 value state 標記之后,把當前數據下發。
























