譯者 | 朱先忠?
審校 | 孫淑娟?
本文將展示各種流行機器學習模型和嵌入技術對馬其頓餐廳評論情感分析的有效性,探索并比較幾種經典的機器學習模型以及包括神經網絡和Transformers在內的現代深度學習技術。實驗表明,采用最新OpenAI嵌入的微調Transformers模型和深度學習模型遠遠優于其他方法。?

雖然用于自然語言處理的機器學習模型傳統上側重于如英語和西班牙語等流行語言;但是,在不太常用語言的發展方面其相關機器學習模型的研究與應用要少得多。另一方面,隨著新冠肺炎疫情導致電子商務的興起,馬其頓語等不太常見的語言也通過在線評論產生了大量數據。這為開發和訓練馬其頓餐廳評論情感分析的機器學習模型提供了機會;成功的話,這可以幫助企業更好地了解客戶情感并改善相關服務。在這項研究中,我們解決了這個問題帶來的挑戰,并探索和比較了馬其頓餐廳評論中用于分析情緒的各種情感分析模型,從經典的隨機森林到現代深度學習技術和Transformers等。?
首先,我們給出本文內容的提綱:?
- LASER嵌入?
- 多語言通用文本編碼器?
- OpenAI Ada v2?
- 隨機森林?
- XGBoost?
- 支持向量機?
- 深度學習?
- Transformers?
預處理數據?
語言是一種獨特的人類交流工具,如果沒有適當的處理技術,計算機無法解釋語言。為了讓機器能夠分析和理解語言,我們需要以可計算處理的方式表示復雜的語義和詞匯信息。實現這一點的一種流行方法是使用向量表示。近年來,除了特定語言的表示模型之外,還出現了多語言模型。這些模型可以捕獲大量語言上文本的語義上下文。?
然而,對于使用西里爾(Cyrillic)文字的語言,由于互聯網上的用戶經常使用拉丁文字來表達自己,從而產生了由拉丁文字和西里爾文字組成的混合數據;這樣一來,就產生了一個額外的挑戰。為了應對這一挑戰,我使用了一家當地餐館的數據集,其中包含大約500條評論——其中包含拉丁語和西里爾語腳本。數據集還包括一小部分英語評論,這將有助于評估混合數據的表現。此外,在線文本可能包含需要刪除的符號,如表情符號。因此,在執行任何文本嵌入之前,預處理是至關重要的步驟。?
import pandas as pd?
import numpy as np?
#把數據集加載進一個dataframe?
df = pd.read_csv('/content/data.tsv', sep='\t')?
# 注意sentiment類別的分布情況?
df['sentiment'].value_counts()?
# -------?
# 0 337?
# 1 322?
# Name: sentiment, dtype: int64?
注意到,數據集包含了分布幾乎相等的正負類。為了刪除表情符號,我使用了Python庫emoji,它可以輕松刪除表情符號和其他符號。?
!pip install emoji?
import emoji?
clt = []?
for comm in df['comment'].to_numpy():?
clt.append(emoji.replace_emoji(comm, replace=""))?
df['comment'] = clt?
df.head()?
對于西里爾文和拉丁文的問題,我將所有文本轉換為一種或另一種,這樣機器學習模型就可以在兩者上進行測試,以比較性能。我使用“cyrtranslit”庫執行此任務。它支持大多數西里爾字母,如馬其頓語、保加利亞語、烏克蘭語等。?
import cyrtranslit?
latin = []?
cyrillic = []?
for comm in df['comment'].to_numpy():?
latin.append(cyrtranslit.to_latin(comm, "mk"))?
cyrillic.append(cyrtranslit.to_cyrillic(comm, "mk"))?
df['comment_cyrillic'] = cyrillic?
df['comment_latin'] = latin?
df.head()?
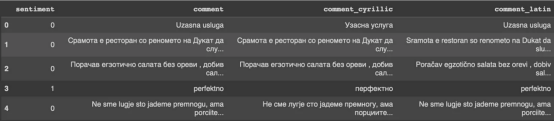
圖1:轉換輸出的結果?
對于我使用的嵌入模型,通常不需要刪除標點符號、停止單詞和進行其他文本清理。這些模型被設計用于處理自然語言文本,包括標點符號,并且當句子保持完整時,通常能夠更準確地捕捉句子的意思。這樣,文本的預處理就完成了。?
矢量嵌入?
目前,沒有大規模的馬其頓語言描述模型可用。然而,我們可以使用基于馬其頓語文本訓練的多語言模型。當前,有幾種這樣的模型可用,但對于這項任務,我發現LASER和多語言通用句子編碼器是最合適的選擇。?
LASER?
LASER(Language-Agnostic Sentence Representations)是一種生成高質量多語言句子嵌入的語言不可知方法。LASER模型基于兩階段過程。其中,第一階段是對文本進行預處理,包括標記化、小寫和應用句子。這部分是特定于語言的;第二階段涉及使用多層雙向LSTM將預處理的輸入文本映射到固定長度的嵌入。?
在一系列基準數據集上,LASER已經被證明優于其他流行的句子嵌入方法,如fastText和InferSent。此外,LASER模型是開源的,免費提供,使每個人都可以輕松訪問。?
使用LASER創建嵌入是一個簡單的過程:?
!pip install laserembeddings?
!python -m laserembeddings download-models?
from laserembeddings import Laser?
#創建嵌入?
laser = Laser()?
embeddings_c = laser.embed_sentences(df['comment_cyrillic'].to_numpy(),lang='mk')?
embeddings_l = laser.embed_sentences(df['comment_latin'].to_numpy(),lang='mk')?
# 保存嵌入?
np.save('/content/laser_multi_c.npy', embeddings_c)?
np.save('/content/laser_multi_l.npy', embeddings_l)?
多語言通用句子編碼器?
多語言通用句子編碼器(MUSE)是由Facebook開發的用于生成句子嵌入的預訓練模型。MUSE旨在將多種語言的句子編碼到一個公共空間中。?
該模型基于深度神經網絡,該網絡使用“編碼器-解碼器”架構來學習句子與其在高維空間中的對應嵌入向量之間的映射。MUSE是在一個大規模的多語言語料庫上訓練的,其中包括維基百科的文本、新聞文章和網頁。?
!pip install tensorflow_text?
import tensorflow as tf?
import tensorflow_hub as hub?
import numpy as np?
import tensorflow_text?
#加載MUSE模型?
module_url = "https://tfhub.dev/google/universal-sentence-encoder-multilingual-large/3"?
embed = hub.load(module_url)?
sentences = df['comment_cyrillic'].to_numpy()?
muse_c = embed(sentences)?
muse_c = np.array(muse_c)?
sentences = df['comment_latin'].to_numpy()?
muse_l = embed(sentences)?
muse_l = np.array(muse_l)?
np.save('/content/muse_c.npy', muse_c)?
np.save('/content/muse_l.npy', muse_l)?
OpenAI Ada v2?
2022年底,OpenAI宣布了他們全新的最先進嵌入模型text-embedding-ada-002(https://openai.com/blog/new-and-improved-embedding-model/)。由于此模型基于GPT-3構建,因此具有多語言處理能力。為了比較西里爾文和拉丁語評論的結果,我決定在兩個數據集上運行了模型:?
!pip install openai?
import openai?
openai.api_key = 'YOUR_KEY_HERE'?
embeds_c = openai.Embedding.create(input = df['comment_cyrillic'].to_numpy().tolist(), model='text-embedding-ada-002')['data']?
embeds_l = openai.Embedding.create(input = df['comment_latin'].to_numpy().tolist(), model='text-embedding-ada-002')['data']?
full_arr_c = []?
for e in embeds_c:?
full_arr_c.append(e['embedding'])?
full_arr_c = np.array(full_arr_c)?
full_arr_l = []?
for e in embeds_l:?
full_arr_l.append(e['embedding'])?
full_arr_l = np.array(full_arr_l)?
np.save('/content/openai_ada_c.npy', full_arr_c)?
np.save('/content/openai_ada_l.npy', full_arr_l)?
機器學習模型?
本節將探討用于預測馬其頓餐廳評論中情緒的各種機器學習模型。從傳統的機器學習模型到深度學習技術,我們將研究每個模型的優缺點,并比較它們在數據集上的性能。?
在運行任何模型之前,應該先對數據進行分割,以便針對每種嵌入類型進行訓練和測試。這可以通過sklearn庫輕松完成。?
from sklearn.model_selection import train_test_split?
X_train, X_test, y_train, y_test = train_test_split(embeddings_c, df['sentiment'], test_size=0.2, random_state=42)?
隨機森林?
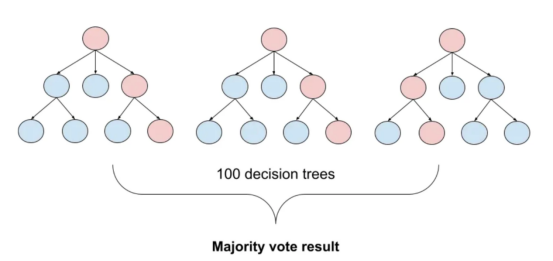
圖2:隨機森林分類的簡化表示。構建100個決策樹,并將結果作為每個決策樹的結果之間的多數表決進行計算?
隨機森林是一種廣泛使用的機器學習算法,它使用決策樹集合對數據點進行分類。該算法通過在完整數據集的子集和特征的隨機子集上訓練每個決策樹來工作。在推理過程中,每個決策樹都會生成一個情緒預測,最終的結果是通過對所有樹進行多數投票獲得的。這種方法有助于防止過度擬合,并可導致更穩健和準確的預測結果。?
from sklearn.ensemble import RandomForestClassifier?
from sklearn.metrics import classification_report, confusion_matrix?
rfc = RandomForestClassifier(n_estimators=100)?
rfc.fit(X_train, y_train)?
print(classification_report(y_test,rfc.predict(X_test)))?
print(confusion_matrix(y_test,rfc.predict(X_test)))?
XGBoost?
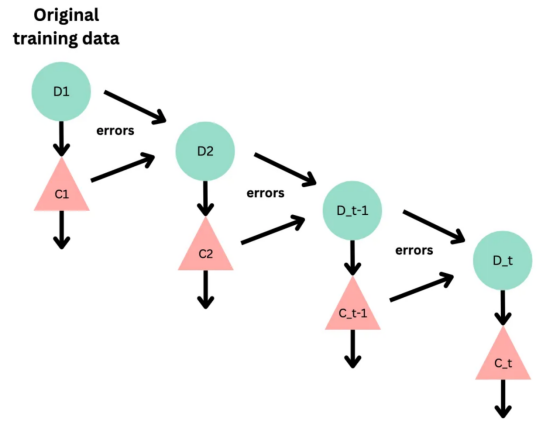
圖3:基于boosting算法的順序過程。每個下一個決策樹都基于上一個決策的殘差(誤差)進行訓練?
XGBoost(極限梯度增強)是一種強大的集成方法,主要用于表格數據。與隨機森林算法模型一樣,XGBoost也使用決策樹對數據點進行分類,但方法不同。XGBoost不是一次訓練所有樹,而是以順序的方式訓練每棵樹,從上一棵樹所犯的錯誤中學習。這個過程被稱為“增強”,這意味著將弱模型結合起來,形成一個更強的模型。雖然XGBoost主要使用表格數據產生了很好的結果,但使用向量嵌入測試該模型也會很有趣。?
from xgboost import XGBClassifier?
from sklearn.metrics import classification_report, confusion_matrix?
rfc = XGBClassifier(max_depth=15)?
rfc.fit(X_train, y_train)?
print(classification_report(y_test,rfc.predict(X_test)))?
print(confusion_matrix(y_test,rfc.predict(X_test)))?
支持向量機?
圖4:支持向量分類的簡化表示。在具有1024個輸入特征的這種情緒分析的情況下,超平面將是1023維?
支持向量機(SVM)是一種用于分類和回歸任務的流行且強大的機器學習算法。它的工作原理是找到將數據分成不同類的最佳超平面,同時最大化類之間的邊界。SVM對高維數據特別有用,可以使用核函數處理非線性邊界。?
from sklearn.svm import SVC?
from sklearn.metrics import classification_report, confusion_matrix?
rfc = SVC()?
rfc.fit(X_train, y_train)?
print(classification_report(y_test,rfc.predict(X_test)))?
print(confusion_matrix(y_test,rfc.predict(X_test)))?
深度學習?
圖5:此問題中使用的神經網絡的簡化表示?
深度學習是一種先進的機器學習方法,它利用由多層和神經元組成的人工神經網絡。深度學習網絡在文本和圖像數據方面表現出色。使用Keras庫實現這些網絡是一個很簡單的過程。?
import tensorflow as tf?
from tensorflow import keras?
from sklearn.model_selection import train_test_split?
from sklearn.metrics import classification_report, confusion_matrix?
model = keras.Sequential()?
model.add(keras.layers.Dense(256, activatinotallow='relu', input_shape=(1024,)))?
model.add(keras.layers.Dropout(0.2))?
model.add(keras.layers.Dense(128, activatinotallow='relu'))?
model.add(keras.layers.Dense(1, activatinotallow='sigmoid'))?
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])?
history = model.fit(X_train, y_train, epochs=11, validation_data=(X_test, y_test))?
test_loss, test_acc = model.evaluate(X_test, y_test)?
print('Test accuracy:', test_acc)?
y_pred = model.predict(X_test)?
print(classification_report(y_test,y_pred.round()))?
print(confusion_matrix(y_test,y_pred.round()))?
在此,使用了具有兩個隱藏層和校正線性單元(ReLU)激活函數的神經網絡。輸出層包含一個具有S形激活函數的神經元,使網絡能夠對積極或消極情緒進行二元預測。二元交叉熵損失函數與S形激活配對以訓練模型。此外,Dropout被用于幫助防止過度擬合和改進模型的泛化。我用各種不同的超參數進行了測試,發現這種配置最適合這個問題。?
通過以下函數,我們可以可視化模型的訓練。?
import matplotlib.pyplot as plt?
def plot_accuracy(history):?
plt.plot(history.history['accuracy'])?
plt.plot(history.history['val_accuracy'])?
plt.title('Model Accuracy')?
plt.xlabel('Epoch')?
plt.ylabel('Accuracy')?
plt.legend(['Train', 'Validation'], loc='upper left')?
plt.show()?
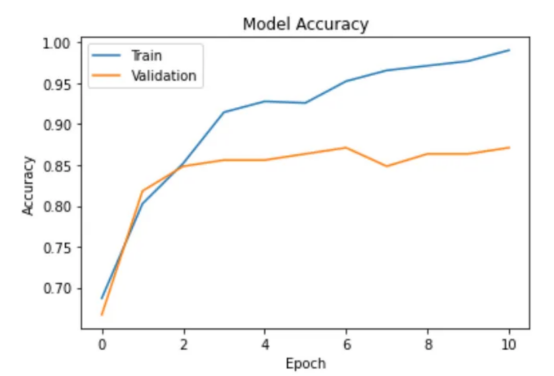
圖6:示例訓練輸出?
Transformers?
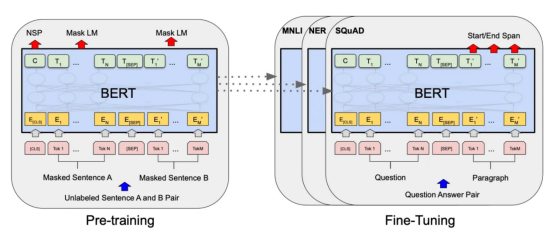
圖7:BERT大型語言模型的預訓練和微調過程。(BERT原始論文地址:https://arxiv.org/pdf/1810.04805v2.pdf)?
微調Transformers是自然語言處理中的一種流行技術,涉及調整預先訓練的變換器模型以適應特定任務。Transformers,如BERT、GPT-2和RoBERTa,在大量文本數據上進行了預訓練,能夠學習語言中的復雜模式和關系。然而,為了在特定任務(如情緒分析或文本分類)上表現良好,需要根據任務特定數據對這些模型進行微調。?
對于這些類型的模型,不需要我們之前創建的向量表示,因為它們直接處理標記(直接從文本中提取)。在馬其頓語的情緒分析任務中,我使用了bert-base-multilingual-uncased,這是BERT模型的多語言版本。?
??HuggingFace??使微調Transformers成為一項非常簡單的任務。首先,需要將數據加載到Transformers數據集中。然后將文本標記化,最后訓練模型。
from sklearn.model_selection import train_test_split?
from datasets import load_dataset?
from transformers import TrainingArguments, Trainer?
from sklearn.metrics import classification_report, confusion_matrix?
# 創建由數據集加載的訓練和測試集的csv文件?
df.rename(columns={"sentiment": "label"}, inplace=True)?
train, test = train_test_split(df, test_size=0.2)?
pd.DataFrame(train).to_csv('train.csv',index=False)?
pd.DataFrame(test).to_csv('test.csv',index=False)?
#加載數據集?
dataset = load_dataset("csv", data_files={"train": "train.csv", "test": "test.csv"})?
# 標記文本?
tokenizer = AutoTokenizer.from_pretrained('bert-base-multilingual-uncased')?
encoded_dataset = dataset.map(lambda t: tokenizer(t['comment_cyrillic'], truncatinotallow=True), batched=True,load_from_cache_file=False)?
# 加載預訓練的模型?
model = AutoModelForSequenceClassification.from_pretrained('bert-base-multilingual-uncased',num_labels =2)?
#微調模型?
arg = TrainingArguments(?
"mbert-sentiment-mk",?
learning_rate=5e-5,?
num_train_epochs=5,?
per_device_eval_batch_size=8,?
per_device_train_batch_size=8,?
seed=42,?
push_to_hub=True?
)?
trainer = Trainer(?
model=model,?
args=arg,?
tokenizer=tokenizer,?
train_dataset=encoded_dataset['train'],?
eval_dataset=encoded_dataset['test']?
)?
trainer.train()?
# 取得預測結果?
predictions = trainer.predict(encoded_dataset["test"])?
preds = np.argmax(predictions.predictions, axis=-1)?
# 評估?
print(classification_report(predictions.label_ids,preds))?
print(confusion_matrix(predictions.label_ids,preds))?
因此,我們成功地調整了BERT進行情緒分析。?
實驗結果與討論?
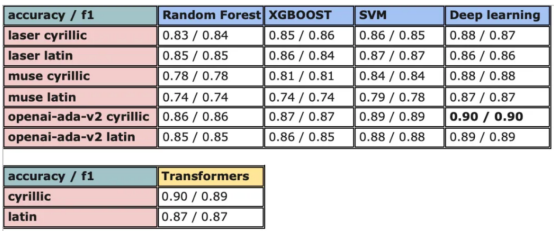
圖8:所有模型的結果大對比?
實驗證明,馬其頓餐廳評論的情緒分析結果是很有希望的,從上圖中可見,其中有幾個模型獲得了很高的準確性和F1分數。實驗表明,深度學習模型和變換器的性能優于傳統的機器學習模型,如隨機森林和支持向量機,盡管相差不大。使用新OpenAI嵌入的Transformers和深度神經網絡成功打破了0.9精度的障礙。?
OpenAI嵌入模型textembedding-ada-002成功地極大提高了從經典ML模型獲得的結果,尤其是在支持向量機上。本研究中的最佳結果是在深度學習模型上嵌入西里爾文文本。?
一般來說,拉丁語文本的表現比西里爾語文本差。盡管我最初假設這些模型的性能會更好,但考慮到拉丁語中類似單詞在其他斯拉夫語言中的流行,以及嵌入模型是基于這些數據訓練的事實,這些發現并不支持這一假設。?
未來的工作?
在未來的工作中,收集更多的數據以進一步訓練和測試模型是非常有價值的,尤其是在審查主題和來源更為多樣化的情況下。此外,嘗試將元數據(例如審閱者的年齡、性別、位置)或時間信息(例如審閱時間)等更多特征納入模型可能會提高其準確性。最后,將分析擴展到其他不太常用的語言,并將模型的性能與馬其頓評論中訓練的模型進行比較,這也將是很有意思的。?
結論?
這篇文章展示了各種流行機器學習模型和嵌入技術對馬其頓餐廳評論情感分析的有效性。探索并比較了幾種經典的機器學習模型,如隨機森林和SVM,以及包括神經網絡和Transformers在內的現代深度學習技術。結果表明,采用最新OpenAI嵌入的微調Transformers模型和深度學習模型優于其他方法,驗證準確率高達90%。?
譯者介紹?
朱先忠,51CTO社區編輯,51CTO專家博客、講師,濰坊一所高校計算機教師,自由編程界老兵一枚。?
原文標題:??From Decision Trees to Transformers: Comparing Sentiment Analysis Models for Macedonian Restaurant Reviews??,作者:Danilo Najkov