AlphaZero的黑箱打開了!DeepMind論文登上PNAS
國際象棋一直是 AI 的試驗場。70 年前,艾倫·圖靈猜想可以制造一臺能夠自我學習并不斷從自身經驗中獲得改進的下棋機器。上世紀出現的「深藍」第一次擊敗人類,但它依賴專家編碼人類的國際象棋知識,而誕生于 2017 年的 AlphaZero 作為一種神經網絡驅動的強化學習機器實現了圖靈的猜想。
AlphaZero 無需使用任何人工設計的啟發式算法,也不需要觀看人類下棋,而是完全通過自我對弈進行訓練。
那么,它真的學習了人類關于國際象棋的概念嗎?這是一個神經網絡的可解釋性問題。
對此,AlphaZero 的作者 Demis Hassabis 與 DeepMind 的同事以及谷歌大腦的研究員合作了一項研究,在 AlphaZero 的神經網絡中找到了人類國際象棋概念的證據,展示了網絡在訓練過程中獲得這些概念的時間和位置,還發現了 AlphaZero 與人類不同的下棋風格。論文近期發表于 PNAS。

論文地址:https://www.pnas.org/doi/epdf/10.1073/pnas.2206625119
AlphaZero 在訓練中獲得人類象棋概念
AlphaZero 的網絡架構包含一個骨干網絡殘差網絡(ResNet)和單獨的 Policy Head、Value Head,ResNet 由一系列由網絡塊和跳躍連接(skip connection)的層構成。
在訓練迭代方面,AlphaZero 從具有隨機初始化參數的神經網絡開始,反復與自身對弈,學習對棋子位置的評估,根據在此過程中生成的數據進行多次訓練。
為了確定 AlphaZero 網絡在多大程度上表征了人類所擁有的國際象棋概念,這項研究使用了稀疏線性探測方法,將網絡在訓練過程中參數的變化映射為人類可理解概念的變化。
首先將概念定義為如圖 1 中橙色所示的用戶定義函數。廣義線性函數 g 作為一個探針被訓練用于近似一個國際象棋概念 c。近似值 g 的質量表示層(線性)對概念進行編碼的程度。對于給定概念,對每個網絡中所有層的訓練過程中產生的網絡序列重復該過程。

圖 1:在 AlphaZero 網絡(藍色)中探索人類編碼的國際象棋概念。
比如,可以用一個函數來確定我方或地方是否有「主教」 (?) :

當然,還有很多比這個例子更復雜的象棋概念,比如對于棋子的機動性(mobility),可以編寫一個函數來比較我方和敵方移動棋子時的得分。
在本實驗中,概念函數是已經預先指定的,封裝了國際象棋這一特定領域的知識。
接下來是對探針進行訓練。研究人員將 ChessBase 數據集中 10 的 5 次方個自然出現的象棋位置作為訓練集,從深度為 d 的網絡激活訓練一個稀疏回歸探針 g,來預測給定概念 c 的值。
通過比較 AlphaZero 自學習周期中不同訓練步驟的網絡,以及每個網絡中不同層的不同概念探針的分數,就可以提取網絡學習到某個概念的時間和位置。
最終得到每個概念的 what-when-where 圖,對「被計算的概念是什么」、「該計算在網絡的哪個位置發生」、「概念在網絡訓練的什么時間出現」這三個指標進行可視化。如圖2。

圖2:從 A 到 B 的概念分別是「對總分的評估」、「我方被將軍了嗎」、「對威脅的評估」、「我方能吃掉敵方的皇后嗎」、「敵方這一步棋會將死我方嗎」、「對子力分數的評估」、「子力分數」、「我方有王城兵嗎」。
可以看到,C 圖中,隨著 AlphaZero 變得更強,「threats」概念的函數和 AlphaZero 的表征(可由線性探針檢測到)變得越來越不相關。
這樣的 what-when-where 圖包括探測方法比較所需的兩個基線,一是輸入回歸,在第 0 層顯示,二是來自具有隨機權重的網絡激活的回歸,在訓練步驟 0 處顯示。上圖的結果可以得出結論,回歸精度的變化完全由網絡表征的變化來決定。
此外,許多 what-when-where 圖的結果都顯示了一個相同的模式,即整個網絡的回歸精度一直都很低,直到大約 32k 步時才開始隨著網絡深度的增加而迅速提高,隨后穩定下來并在后面的層中保持不變。所以,所有與概念相關的計算都在網絡的相對早期發生,而之后的殘差塊要么執行移動選擇,要么計算給定概念集之外的特征。
而且,隨著訓練的進行,許多人類定義的概念都可以從 AlphaZero 的表征中預測到,且預測準確率很高。
對于更高級的概念,研究人員發現 AlphaZero 掌握它們的位置存在差異。首先在 2k 訓練步驟時與零顯著不同的概念是「material」和「space」;更復雜的概念如「king_safety」、「threats」、「mobility」,則是在 8k 訓練步驟時顯著得變為非零,且在 32k 訓練步驟之后才有實質增長。這個結果與圖 2 中 what-when-where 圖顯示的 急劇上升的點一致。
急劇上升的點一致。
另外,大多數 what-when-where 圖的一個顯著特征是網絡的回歸精度在開始階段增長迅速,隨后達到平穩狀態或下降。這表明目前從 AlphaZero 身上所發現的概念集還只是檢測了網絡的較早層,要了解后面的層,需要新的概念檢測技術。
AlphaZero 的開局策略與人類不同
在觀察到 AlphaZero 學習了人類國際象棋概念后,研究人員進一步針對開局策略探討了 AlphaZero 對于象棋戰術的理解,因為開局的選擇也隱含了棋手對于相關概念的理解。

研究人員觀察到,AlphaZero 與人類的開局策略并不相同:隨著時間的推移,AlphaZero 縮小了選擇范圍,而人類則是擴大選擇范圍。
如圖 3A 是人類對白棋的第一步偏好的歷史演變,早期階段,流行將 e4 作為第一步棋,后來的開局策略則變得更平衡、更靈活。
圖 3B 則是 AlphaZero 的開局策略隨訓練步驟的演變。可以看到,AlphaZero 的開局總是平等地權衡所有選擇,然后逐漸縮小選擇范圍。

圖 3:隨著訓練步驟和時間的推移,AlphaZero 和人類對第一步的偏好比較。
這與人類知識的演變形成鮮明對比,人類知識從 e4 開始逐漸擴展,而 AlphaZero 在訓練的后期階段明顯偏向于 d4。不過,這種偏好不需要過度解釋,因為自我對弈訓練是基于快速游戲,為了促進探索增加了許多隨機性。
造成這種差異的原因尚不清楚,但它反映了人類與人工神經網絡之間的根本差異。一個可能的因素,或許是關于人類象棋的歷史數據更強調大師玩家的集體知識,而 AlphaZero 的數據包括了初學者級別下棋和單一進化策略。
那么,當 AlphaZero 的神經網絡經過多次訓練后,是否會出對某些開局策略顯示出穩定的偏好?
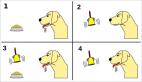
研究結果是,許多情況下,這種偏好在不同訓練中并不穩定,AlphaZero 的開局策略非常多樣。比如在經典的Ruy Lopez 開局(俗稱「西班牙開局」)中,AlphaZero 在早期有選擇黑色的偏好,并遵循典型的下法,即 1.e4 e5,2.Nf3 Nc6,3.Bb5。

圖 4:Ruy Lopez 開局
而在不同的訓練中,AlphaZero 會逐漸收斂到 3.f6 和 3.a6 中的一個。此外,AlphaZero 模型的不同版本都各自顯示出對一個動作的強烈偏好,且這種偏好在訓練早期就得以建立。
這進一步證明,國際象棋的成功下法多種多樣,這種多樣性不僅存在于人與機器之間,也存在于 AlphaZero 的不同訓練迭代中。
AlphaZero 掌握知識的過程
那么,以上關于開局策略的研究結果,與 AlphaZero 對概念的理解有什么關聯呢?
這項研究發現,在各種概念的 what-when-where 圖中有一個明顯的拐點,與開局偏好的顯著變化正好相吻合,尤其是 material 和 mobility的概念似乎與開局策略直接相關。
material 概念主要是在訓練步驟 10k 和 30k 之間學習的,piece mobility 的概念也在同一時期逐步融入到 AlphaZero 的 value head 中。對棋子的 material 價值的基本理解應該先于對棋子 mobility 的理解。然后 AlphaZero 將這一理論納入到 25k 到 60k 訓練步驟之間開局偏好中。
作者進一步分析了 AlphaZero 網絡關于國際象棋的知識的演變過程:首先發現棋力;接著是短時間窗口內基礎知識的爆炸式增長,主要是與 mobility 相關的一些概念;最后是改進階段,神經網絡的開局策略在數十萬個訓練步驟中得到完善。雖然整體學習的時間很長,但特定的基礎能力會在相對較短的時間內迅速出現。
前國際象棋世界冠軍 Vladimir Kramnik 也被請來為這一結論提供佐證,他的觀察與上述過程一致。
最后總結一下,這項工作證明了 AlphaZero 網絡所學習的棋盤表示能夠重建許多人類國際象棋概念,并詳細說明了網絡所學習的概念內容、在訓練時間中學習概念的時間以及計算概念的網絡位置。而且,AlphaZero 的下棋風格與人類并不相同。
既然我們以人類定義的國際象棋概念來理解神經網絡,那么下一個問題將會是:神經網絡能夠學習人類知識以外的東西嗎?