













換一個(gè)角度看 B+ 樹(shù)
本文轉(zhuǎn)載自微信公眾號(hào)「小林coding」,作者小林coding 。轉(zhuǎn)載本文請(qǐng)聯(lián)系小林coding公眾號(hào)。
大家好,我是小林。
大家背八股文的時(shí)候,都知道 MySQL 里 InnoDB 存儲(chǔ)引擎是采用 B+ 樹(shù)來(lái)組織數(shù)據(jù)的。
這點(diǎn)沒(méi)錯(cuò),但是大家知道 B+ 樹(shù)里的節(jié)點(diǎn)里存放的是什么呢?查詢數(shù)據(jù)的過(guò)程又是怎樣的?
這次,我們從數(shù)據(jù)頁(yè)的角度看 B+ 樹(shù),看看每個(gè)節(jié)點(diǎn)長(zhǎng)啥樣。
InnoDB 是如何存儲(chǔ)數(shù)據(jù)的?
MySQL 支持多種存儲(chǔ)引擎,不同的存儲(chǔ)引擎,存儲(chǔ)數(shù)據(jù)的方式也是不同的,我們最常使用的是 InnoDB 存儲(chǔ)引擎,所以就跟大家圖解下InnoDB 是如何存儲(chǔ)數(shù)據(jù)的。
記錄是按照行來(lái)存儲(chǔ)的,但是數(shù)據(jù)庫(kù)的讀取并不以「行」為單位,否則一次讀取(也就是一次 I/O 操作)只能處理一行數(shù)據(jù),效率會(huì)非常低。
因此,InnoDB 的數(shù)據(jù)是按「數(shù)據(jù)頁(yè)」為單位來(lái)讀寫(xiě)的,也就是說(shuō),當(dāng)需要讀一條記錄的時(shí)候,并不是將這個(gè)記錄本身從磁盤(pán)讀出來(lái),而是以頁(yè)為單位,將其整體讀入內(nèi)存。
數(shù)據(jù)庫(kù)的 I/O 操作的最小單位是頁(yè),InnoDB 數(shù)據(jù)頁(yè)的默認(rèn)大小是 16KB,意味著數(shù)據(jù)庫(kù)每次讀寫(xiě)都是以 16KB 為單位的,一次最少?gòu)拇疟P(pán)中讀取 16K 的內(nèi)容到內(nèi)存中,一次最少把內(nèi)存中的 16K 內(nèi)容刷新到磁盤(pán)中。
數(shù)據(jù)頁(yè)包括七個(gè)部分,結(jié)構(gòu)如下圖:

這 7 個(gè)部分的作用如下圖:

在 File Header 中有兩個(gè)指針,分別指向上一個(gè)數(shù)據(jù)頁(yè)和下一個(gè)數(shù)據(jù)頁(yè),連接起來(lái)的頁(yè)相當(dāng)于一個(gè)雙向的鏈表,如下圖所示:
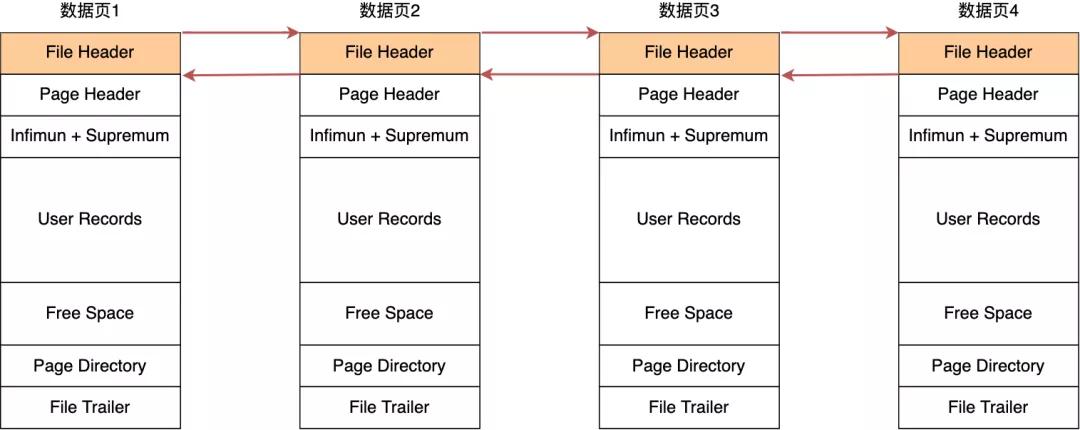
采用鏈表的結(jié)構(gòu)是讓數(shù)據(jù)頁(yè)之間不需要是物理上的連續(xù)的,而是邏輯上的連續(xù)。
數(shù)據(jù)頁(yè)的主要作用是存儲(chǔ)記錄,也就是數(shù)據(jù)庫(kù)的數(shù)據(jù),所以重點(diǎn)說(shuō)一下數(shù)據(jù)頁(yè)中的 User Records 是怎么組織數(shù)據(jù)的。
數(shù)據(jù)頁(yè)中的記錄按照「主鍵」順序組成單向鏈表,單向鏈表的特點(diǎn)就是插入、刪除非常方便,但是檢索效率不高,最差的情況下需要遍歷鏈表上的所有節(jié)點(diǎn)才能完成檢索。
因此,數(shù)據(jù)頁(yè)中有一個(gè)頁(yè)目錄,起到記錄的索引作用,就像我們書(shū)那樣,針對(duì)書(shū)中內(nèi)容的每個(gè)章節(jié)設(shè)立了一個(gè)目錄,想看某個(gè)章節(jié)的時(shí)候,可以查看目錄,快速找到對(duì)應(yīng)的章節(jié)的頁(yè)數(shù),而數(shù)據(jù)頁(yè)中的頁(yè)目錄就是為了能快速找到記錄。
那 InnoDB 是如何給記錄創(chuàng)建頁(yè)目錄的呢?頁(yè)目錄與記錄的關(guān)系如下圖:
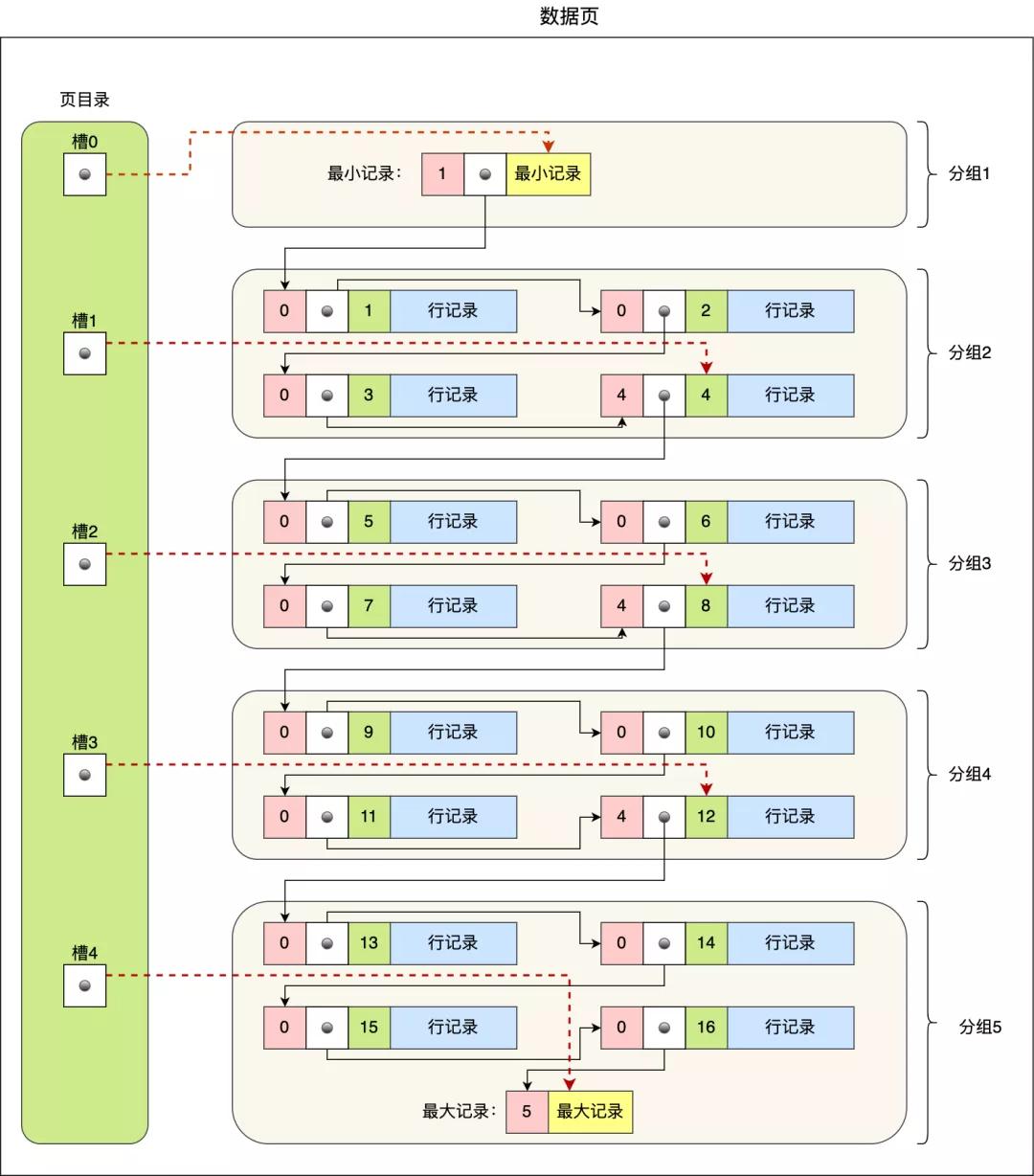
頁(yè)目錄創(chuàng)建的過(guò)程如下:
- 將所有的記錄劃分成幾個(gè)組,這些記錄包括最小記錄和最大記錄,但不包括標(biāo)記為“已刪除”的記錄;
- 每個(gè)記錄組的最后一條記錄就是組內(nèi)最大的那條記錄,并且最后一條記錄的頭信息中會(huì)存儲(chǔ)該組一共有多少條記錄,作為 n_owned 字段(上圖中粉紅色字段)
- 頁(yè)目錄用來(lái)存儲(chǔ)每組最后一條記錄的地址偏移量,這些地址偏移量會(huì)按照先后順序存儲(chǔ)起來(lái),每組的地址偏移量也被稱之為槽(slot),每個(gè)槽相當(dāng)于指針指向了不同組的最后一個(gè)記錄。
從圖可以看到,頁(yè)目錄就是由多個(gè)槽組成的,槽相當(dāng)于分組記錄的索引。然后,因?yàn)橛涗浭前凑铡钢麈I值」從小到大排序的,所以我們通過(guò)槽查找記錄時(shí),可以使用二分法快速定位要查詢的記錄在哪個(gè)槽(哪個(gè)記錄分組),定位到槽后,再遍歷槽內(nèi)的所有記錄,找到對(duì)應(yīng)的記錄,無(wú)需從最小記錄開(kāi)始遍歷整個(gè)頁(yè)中的記錄鏈表。
以上面那張圖舉個(gè)例子,5 個(gè)槽的編號(hào)分別為 0,1,2,3,4,我想查找主鍵為 11 的用戶記錄:
- 先二分得出槽中間位是 (0+4)/2=2 ,2號(hào)槽里最大的記錄為 8。因?yàn)?11 > 8,所以需要從 2 號(hào)槽后繼續(xù)搜索記錄;
- 再使用二分搜索出 2 號(hào)和 4 槽的中間位是 (2+4)/2= 3,3 號(hào)槽里最大的記錄為 12。因?yàn)?11 < 12,所以主鍵為 11 的記錄在 3 號(hào)槽里;
- 再?gòu)?3 號(hào)槽指向的主鍵值為 9 記錄開(kāi)始向下搜索 2 次,定位到主鍵為 11 的記錄,取出該條記錄的信息即為我們想要查找的內(nèi)容。
看到第三步的時(shí)候,可能有的同學(xué)會(huì)疑問(wèn),如果某個(gè)槽內(nèi)的記錄很多,然后因?yàn)橛涗浂际菃蜗蜴湵泶饋?lái)的,那這樣在槽內(nèi)查找某個(gè)記錄的時(shí)間復(fù)雜度不就是 O(n) 了嗎?
這點(diǎn)不用擔(dān)心,InnoDB 對(duì)每個(gè)分組中的記錄條數(shù)都是有規(guī)定的,槽內(nèi)的記錄就只有幾條:
- 第一個(gè)分組中的記錄只能有 1 條記錄;
- 最后一個(gè)分組中的記錄條數(shù)范圍只能在 1-8 條之間;
- 剩下的分組中記錄條數(shù)范圍只能在 4-8 條之間。
B+ 樹(shù)是如何進(jìn)行查詢的?
上面我們都是在說(shuō)一個(gè)數(shù)據(jù)頁(yè)中的記錄檢索,因?yàn)橐粋€(gè)數(shù)據(jù)頁(yè)中的記錄是有限的,且主鍵值是有序的,所以通過(guò)對(duì)所有記錄進(jìn)行分組,然后將組號(hào)(槽號(hào))存儲(chǔ)到頁(yè)目錄,使其起到索引作用,通過(guò)二分查找的方法快速檢索到記錄在哪個(gè)分組,來(lái)降低檢索的時(shí)間復(fù)雜度。
但是,當(dāng)我們需要存儲(chǔ)大量的記錄時(shí),就需要多個(gè)數(shù)據(jù)頁(yè),這時(shí)我們就需要考慮如何建立合適的索引,才能方便定位記錄所在的頁(yè)。
為了解決這個(gè)問(wèn)題,InnoDB 采用了 B+ 樹(shù)作為索引。磁盤(pán)的 I/O 操作次數(shù)對(duì)索引的使用效率至關(guān)重要,因此在構(gòu)造索引的時(shí)候,我們更傾向于采用“矮胖”的 B+ 樹(shù)數(shù)據(jù)結(jié)構(gòu),這樣所需要進(jìn)行的磁盤(pán) I/O 次數(shù)更少,而且 B+ 樹(shù) 更適合進(jìn)行關(guān)鍵字的范圍查詢。
更詳細(xì)的為什么采用 B+ 樹(shù)作為索引的原因可以看我之前寫(xiě)的這篇:「索引為什么能提高查詢性能?」
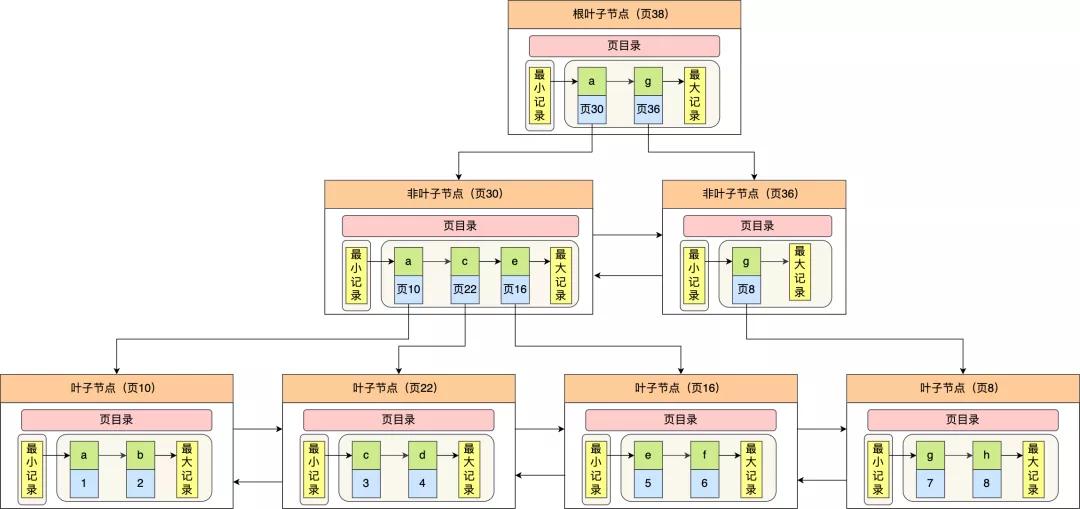
InnoDB 里的 B+ 樹(shù)中的每個(gè)節(jié)點(diǎn)都是一個(gè)數(shù)據(jù)頁(yè),結(jié)構(gòu)示意圖如下:
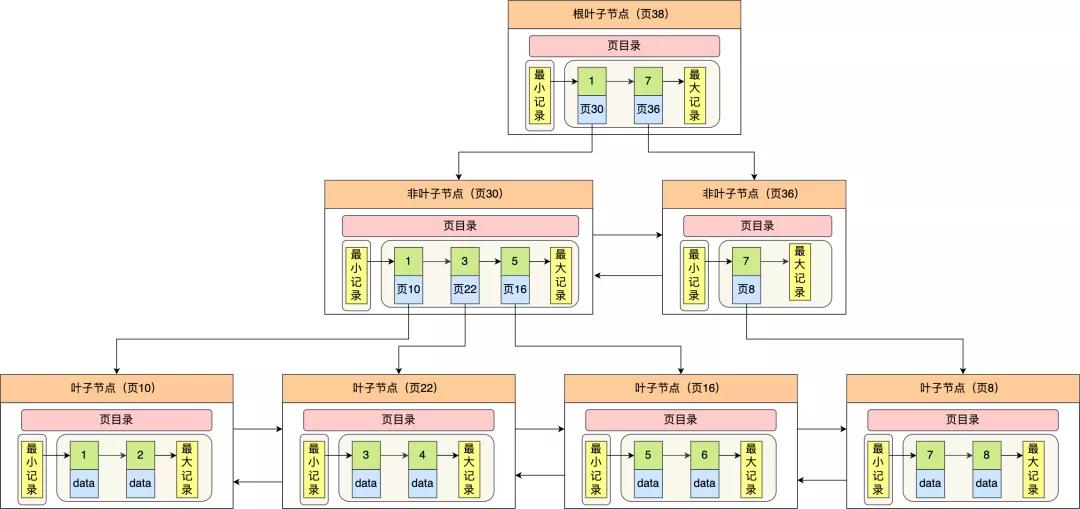
通過(guò)上圖,我們看出 B+ 樹(shù)的特點(diǎn):
- 只有葉子節(jié)點(diǎn)(最底層的節(jié)點(diǎn))才存放了數(shù)據(jù),非葉子節(jié)點(diǎn)(其他上層節(jié))僅用來(lái)存放目錄項(xiàng)作為索引。
- 非葉子節(jié)點(diǎn)分為不同層次,通過(guò)分層來(lái)降低每一層的搜索量;
- 所有節(jié)點(diǎn)按照索引鍵大小排序,構(gòu)成一個(gè)雙向鏈表,便于范圍查詢;
我們?cè)倏纯?B+ 樹(shù)如何實(shí)現(xiàn)快速查找主鍵為 6 的記錄,以上圖為例子:
- 從根節(jié)點(diǎn)開(kāi)始,通過(guò)二分法快速定位到符合頁(yè)內(nèi)范圍包含查詢值的頁(yè),因?yàn)椴樵兊闹麈I值為 6,在[1, 7)范圍之間,所以到頁(yè) 30 中查找更詳細(xì)的目錄項(xiàng);
- 在非葉子節(jié)點(diǎn)(頁(yè)30)中,繼續(xù)通過(guò)二分法快速定位到符合頁(yè)內(nèi)范圍包含查詢值的頁(yè),主鍵值大于 5,所以就到葉子節(jié)點(diǎn)(頁(yè)16)查找記錄;
- 接著,在葉子節(jié)點(diǎn)(頁(yè)16)中,通過(guò)槽查找記錄時(shí),使用二分法快速定位要查詢的記錄在哪個(gè)槽(哪個(gè)記錄分組),定位到槽后,再遍歷槽內(nèi)的所有記錄,找到主鍵為 6 的記錄。
可以看到,在定位記錄所在哪一個(gè)頁(yè)時(shí),也是通過(guò)二分法快速定位到包含該記錄的頁(yè)。定位到該頁(yè)后,又會(huì)在該頁(yè)內(nèi)進(jìn)行二分法快速定位記錄所在的分組(槽號(hào)),最后在分組內(nèi)進(jìn)行遍歷查找。
聚集索引和二級(jí)索引
另外,索引又可以分成聚集索引和非聚集索引(二級(jí)索引),它們區(qū)別就在于葉子節(jié)點(diǎn)存放的是什么數(shù)據(jù):
- 聚集索引的葉子節(jié)點(diǎn)存放的是實(shí)際數(shù)據(jù),所有完整的用戶記錄都存放在聚集索引的葉子節(jié)點(diǎn);
- 二級(jí)索引的葉子節(jié)點(diǎn)存放的是主鍵值,而不是實(shí)際數(shù)據(jù)。
因?yàn)楸淼臄?shù)據(jù)都是存放在聚集索引的葉子節(jié)點(diǎn)里,所以 InnoDB 存儲(chǔ)引擎一定會(huì)為表創(chuàng)建一個(gè)聚集索引,且由于數(shù)據(jù)在物理上只會(huì)保存一份,所以聚簇索引只能有一個(gè)。
InnoDB 在創(chuàng)建聚簇索引時(shí),會(huì)根據(jù)不同的場(chǎng)景選擇不同的列作為索引:
- 如果有主鍵,默認(rèn)會(huì)使用主鍵作為聚簇索引的索引鍵;
- 如果沒(méi)有主鍵,就選擇第一個(gè)不包含 NULL 值的唯一列作為聚簇索引的索引鍵;
- 在上面兩個(gè)都沒(méi)有的情況下,InnoDB 將自動(dòng)生成一個(gè)隱式自增 id 列作為聚簇索引的索引鍵;
一張表只能有一個(gè)聚簇索引,那為了實(shí)現(xiàn)非主鍵字段的快速搜索,就引出了二級(jí)索引(非聚簇索引/輔助索引),它也是利用了 B+ 樹(shù)的數(shù)據(jù)結(jié)構(gòu),但是二級(jí)索引的葉子節(jié)點(diǎn)存放的是主鍵值,不是實(shí)際數(shù)據(jù)。
二級(jí)索引的 B+ 樹(shù)如下圖,數(shù)據(jù)部分為主鍵值:
因此,如果某個(gè)查詢語(yǔ)句使用了二級(jí)索引,但是查詢的數(shù)據(jù)不是主鍵值,這時(shí)在二級(jí)索引找到主鍵值后,需要去聚簇索引中獲得數(shù)據(jù)行,這個(gè)過(guò)程就叫作「回表」,也就是說(shuō)要查兩個(gè) B+ 樹(shù)才能查到數(shù)據(jù)。不過(guò),當(dāng)查詢的數(shù)據(jù)是主鍵值時(shí),因?yàn)橹辉诙?jí)索引就能查詢到,不用再去聚簇索引查,這個(gè)過(guò)程就叫作「索引覆蓋」,也就是只需要查一個(gè) B+ 樹(shù)就能找到數(shù)據(jù)。
總結(jié)
InnoDB 的數(shù)據(jù)是按「數(shù)據(jù)頁(yè)」為單位來(lái)讀寫(xiě)的,默認(rèn)數(shù)據(jù)頁(yè)大小為 16 KB。每個(gè)數(shù)據(jù)頁(yè)之間通過(guò)雙向鏈表的形式組織起來(lái),物理上不連續(xù),但是邏輯上連續(xù)。
數(shù)據(jù)頁(yè)內(nèi)包含用戶記錄,每個(gè)記錄之間用單項(xiàng)鏈表的方式組織起來(lái),為了加快在數(shù)據(jù)頁(yè)內(nèi)高效查詢記錄,設(shè)計(jì)了一個(gè)頁(yè)目錄,頁(yè)目錄存儲(chǔ)各個(gè)槽(分組),且主鍵值是有序的,于是可以通過(guò)二分查找法的方式進(jìn)行檢索從而提高效率。
為了高效查詢記錄所在的數(shù)據(jù)頁(yè),InnoDB 采用 b+ 樹(shù)作為索引,每個(gè)節(jié)點(diǎn)都是一個(gè)數(shù)據(jù)頁(yè)。
如果葉子節(jié)點(diǎn)存儲(chǔ)的是實(shí)際數(shù)據(jù)的就是聚簇索引,一個(gè)表只能有一個(gè)聚簇索引;如果葉子節(jié)點(diǎn)存儲(chǔ)的不是實(shí)際數(shù)據(jù),而是主鍵值則就是二級(jí)索引,一個(gè)表中可以有多個(gè)二級(jí)索引。
在使用二級(jí)索引進(jìn)行查找數(shù)據(jù)時(shí),如果查詢的數(shù)據(jù)能在二級(jí)索引找到,那么就是「索引覆蓋」操作,如果查詢的數(shù)據(jù)不在二級(jí)索引里,就需要先在二級(jí)索引找到主鍵值,需要去聚簇索引中獲得數(shù)據(jù)行,這個(gè)過(guò)程就叫作「回表」。
關(guān)于索引的內(nèi)容還有很多,比如索引失效、索引優(yōu)化等等,這些內(nèi)容我下次在講啦!


















