譯者 | 朱先忠
審校 | 重樓
簡介
ChatGPT是一種GPT(生成式預訓練轉換器)機器學習(ML)工具,如今它讓整個世界為之驚訝。它驚人的功能給普通用戶、專業人士、研究人員,甚至它自己的創造者留下了深刻印象。此外,它能夠成為一個加速一般任務完成進度的機器學習模型,并在特定領域的情況下表現出色,這一能力給人留下深刻的印象。我是一名研究人員,ChatGPT進行情緒分析(SA)的強大能力也讓我非常感興趣。
情緒分析是一種非常廣泛的自然語言處理(NLP)。它有多種應用,因此可以應用于多個領域(如金融、娛樂、心理學等)。不過,有些領域使用的是特定的術語(例如金融領域)。因此,通用領域ML模型是否能夠像特定領域模型一樣強大,仍然是NLP中一個懸而未決的研究問題。
如果你問ChatGPT這個研究問題(這是本文的標題),那么它會給你一個謙遜的答案(繼續,試試看)。但是,我親愛的讀者,我通常不愿在這方面掃你的興;不過,你不知道這個ChatGPT的答案有多謙虛……
盡管如此,作為一名人工智能研究人員、行業專業人士和業余愛好者,我習慣于細調通用領域NLP機器學習工具(例如GloVe),以用于特定領域的任務。之所以會出現這種情況,是因為對于大多數領域來說,找到一種開箱即用的、不經微調就能做得足夠好的解決方案并不常見。本文中,我將向你展示這種情況以后將不再成為常態。
在本文中,我通過討論以下主題將ChatGPT與特定領域的ML模型進行比較:
- SemEval 2017任務5——一種特定領域的挑戰
- 使用ChatGPT API實戰性代碼來標記一個數據集
- 與再現性細節比較的結論和結果
- 結論和結果討論
- 擴展思索:如何在應用場景中進行比較
注1:本文給出的只是一個簡單的動手實驗,將有助于對于文章主題的了解,而不是一份詳盡的科學調查。
注2:除非另有說明,否則所有圖片均由作者提供。
1.SemEval 2017任務5——一種特定領域的挑戰
SemEval(語義評估)是一個著名的NLP研討會,研究團隊在情感分析、文本相似性和問答任務方面進行科學競爭。組織者提供由注釋者(領域專家)和語言學家創建的文本數據和黃金標準數據集,以評估每項任務的最先進解決方案。
特別是,SemEval 2017年的任務5要求研究人員對金融微博和新聞頭條進行情緒分析,評分為-1(最負面)到1(最正面)。我們將使用當年SemEval的黃金標準數據集來測試ChatGPT在特定領域任務中的性能。子任務2數據集(新聞標題)使用兩組句子(每個句子最多30個單詞):訓練集(1142個句子)和測試集(491個句子)。
考慮到這些數據集合,情緒得分和文本句子的數據分布如下所示。下圖顯示了訓練集和測試集中的雙峰分布。此外,該圖表明數據集中積極的句子多于消極的句子。
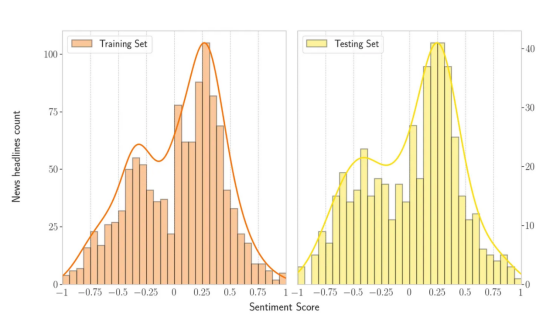
SemEval 2017任務5子任務2(新聞標題):考慮訓練(左邊——1142個句子)和測試(右邊——491個句子)集的數據分布情緒得分。
對于這個子任務,獲勝的研究團隊(即在測試集中排名最好的團隊)將他們的ML架構命名為Fortia FBK。受此次比賽發現的啟發,我和一些同事寫了一篇研究文章(評估金融文本中基于回歸的情緒分析技術),在文章中我們實現了Fortia FBK版本,并評估了改進該架構的方法。
此外,我們還調查了使該體系結構成為制勝體系結構的因素。因此,我們對這一獲勝架構(即Fortia FBK)的實現(源碼在這里:https://bit.ly/3kzau8G)用于與ChatGPT進行比較。所采用的架構(CNN+GloVe+Vader)如下所示:
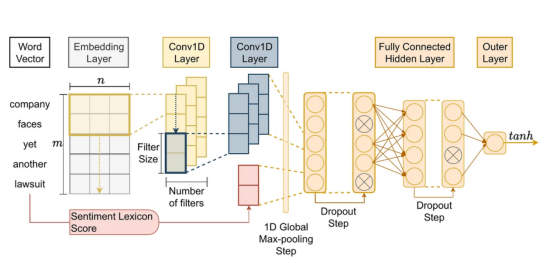
金融新聞領域的特定領域情緒分析ML模型,對應于研究文章“評估金融文本中基于回歸的情緒分析技術”的開發架構。來源:作者碩士學位論文(Lima Paiva,F.C.,“在智能交易的強化學習中同化情緒分析”)。
2.使用ChatGPT API標記數據集
使用ChatGPT API的基本思路早已經在Medium網站上討論過,用于合成數據。此外,您可以在ChatGPT API代碼示例部分中找到情感標簽示例(請注意,使用該API并不是免費的)。對于這個代碼示例,請考慮使用SemEval的2017任務黃金標準數據集,您可以在鏈接https://bitbucket.org/ssix-project/semeval-2017-task-5-subtask-2/src/master/處獲得該數據集。
接下來,要使用API一次標記多個句子,請使用如下這樣的代碼,其中我用黃金標準數據集的數據框中的句子準備一個完整的提示符,其中包含要標記的句子和情緒所指的目標公司。
def prepare_long_prompt(df):
initial_txt = "Classify the sentiment in these sentences between brackets regarding only the company specified in double-quotes. The response should be in one line with format company name in normal case followed by upper cased sentiment category in sequence separated by a semicolon:\n\n"
prompt = "\"" + df['company'] + "\"" + " [" + df['title'] + ")]"
return initial_txt + '\n'.join(prompt.tolist())然后,調用text-davinci-003引擎(GPT-3版本)的API。在這里,我對代碼進行了一些調整,考慮到提示中的最大總字符數加上答案,最多必須是4097個字符。
def call_chatgpt_api(prompt):
#獲取允許用于響應的最大令牌數量:基于api最大值為4097并考慮到提示文本的長度。
prompt_length = len(prompt)
max_tokens = 4097 - prompt_length
# 這個除以10的規則只是一個經驗估計,不是一個精確的規則
if max_tokens < (prompt_length / 10):
raise ValueError(f'Max allowed token for response is dangerously low {max_tokens} and might not be enough, try reducing the prompt size')
response = openai.Completion.create(
model="text-davinci-003",
prompt=prompt,
temperature=0,
max_tokens=max_tokens,
top_p=1,
frequency_penalty=0,
presence_penalty=0
)
return response.choices[0]['text']
long_prompt = prepare_long_prompt(df)
call_chatgpt_api(long_prompt)最終,在黃金標準數據集中對總共1633個句子(訓練+測試集)執行此操作,您將得到以下ChatGPT API標記的結果。

SemEval 2017任務5子任務2(新聞標題)黃金標準數據集示例:使用ChatGPT API標記情緒。
2.1.ChatGPT及其API的規模問題
與其他任何API一樣,ChatGPT的API應用也存在如下一些典型的要求:
- 需要調節的請求速率限制
- 25000個令牌的請求限制(即子字單元或字節對編碼)
- 每個請求的最大長度為4096個令牌(包括提示+響應)
- 0.0200/1K代幣的成本(注意:我完成所有任務后,花費從未超過2美元)
然而,這些只是處理大多數API時的典型需求。此外,請記住,在這個特定領域的問題中,每個句子都通過一個目標實體(即公司)來表達情感。因此,我不得不反復調整關鍵詞,最終我才設計了一個提示模式,可以同時標記幾個句子的情感,并使之后的處理結果變得容易。此外,還有其他限制影響了我之前展示的提示和代碼。具體來說,我發現在多個句子中使用此文本API存在問題(>1000)。
- 再現性:只需對提示進行很少的更改(例如,添加或刪除句子中的逗號或點),ChatGPT對情緒的情緒評估就可能會發生顯著變化。
- 一致性:如果你沒有明確指定模式響應,ChatGPT將變得非常有創意(即使你選擇了一個非常低的隨機性參數),從而導致很難處理結果。此外,即使指定了模式,它也可能輸出不一致的輸出格式。
- 不匹配:盡管它可以非常準確地識別你想在一句話中評估情緒的目標實體(例如公司),但在進行大規模評估時,它可能會混淆結果——例如,假設你輸入10句話,其中第一句對應一家目標公司。盡管如此,其中一些公司還是出現在其他句子中或被重復出現。在這種情況下,ChatGPT可以使目標和句子情感不匹配,改變情感標簽的順序或提供少于10個標簽。
- 偏見:目前,ChatGPT偏見的問題是眾所周知的。還有一些關于如何改善這個問題的想法。然而,在此之前,請注意您正在學習使用有偏見的API。
所有這些問題都意味著,正確使用(有偏見的)API需要一條學習曲線。它需要一些微調才能得到我需要的東西。有時我不得不做很多試驗,直到我以最低的一致性達到預期的結果。
在理想的情況下,你應該同時發送盡可能多的句子,原因有兩個。首先,你想盡快拿到你的標簽。其次,提示在成本耗費中被視為令牌,因此更少的請求意味著更少的成本花費。然而,我們遇到了每個請求有4096個令牌的限制。此外,考慮到我提到的問題,還存在另一個值得注意的API限制。那就是,一次過多的句子會增加不匹配和不一致的幾率。因此,你應該不斷增加和減少句子的數量,直到你找到一致性和成本的最佳點。如果你做得不好,你將在后處理結果階段受到影響。
總之,如果你有數千個句子要處理,從一批六個句子和不超過10個提示開始,檢查回答的可靠性。然后,慢慢增加數量以驗證容量和質量,直到找到適合您任務的最佳提示和成本耗費。
3.結論和比較結果
3.1.比較細節
在ChatGPT的GPT-3版本中,它無法將情感歸因于使用數值的文本句子(無論我嘗試了多少)。然而,專家們在這個特殊的黃金標準數據集中將數字分數歸因于句子情感。
因此,為了進行一次可行的比較,我必須:
- 將數據集得分分類為“正”、“中性”或“負”標簽。
- 對特定領域的ML模型生成的分數也執行同樣的操作。
- 定義一系列可能的閾值(步長為0.001),用于確定一個類別的起點和終點。然后,給定閾值TH,高于+TH的分數被認為是積極情緒,低于-TH的分數是消極情緒,介于兩者之間的分數是中性情緒。
- 在閾值范圍內進行迭代,并評估兩個模型在每個點的準確性。
- 考慮到特定領域模型在訓練集中具有不公平的優勢,按集合(即訓練或測試)調查它們的性能。
其中,上述步驟3的代碼如下所示。復制整個比較過程的完整代碼位于鏈接https://drive.google.com/drive/folders/1_FpNvcGjnl8N2Z_Az3FGGWQ4QxmutmgG?usp=share_link處。
def get_df_plot(df, th_sequence):
temp_list = []
for th in th_sequence:
converted_gold_arr = np.where((df['sentiment'] <= th) & (df['sentiment'] >= -th), 0, np.sign(df['sentiment']))
converted_model_arr = np.where((df['cnn-pred-sent'] <= th) & (df['cnn-pred-sent'] >= -th), 0, np.sign(df['cnn-pred-sent']))
df['sent_cat_value'] = converted_gold_arr.astype(np.int64)
df['cnn_pred_sent_cat_value'] = converted_model_arr.astype(np.int64)
corr_gold_chatgpt = df['chatgpt_sent_value'].corr(df['sent_cat_value'])
corr_gold_cnn = df['chatgpt_sent_value'].corr(df['cnn_pred_sent_cat_value'])
acc_gold_chatgpt = (df['chatgpt_sent_value']==df['sent_cat_value']).mean()
acc_gold_cnn = (df['chatgpt_sent_value']==df['cnn_pred_sent_cat_value']).mean()
temp_list.append([th, corr_gold_chatgpt, corr_gold_cnn, acc_gold_chatgpt, acc_gold_cnn])
return pd.DataFrame(data=temp_list, columns=['th', 'corr_gold_chatgpt', 'corr_gold_cnn', 'acc_gold_chatgpt', 'acc_gold_cnn'])
th_sequence = np.arange(0, 1.000001, 0.001)
df_plot = get_df_plot(df.copy(), th_sequence)3.2.結論:ChatGPT不僅可以獲勝,而且可以打破競爭
最終結果顯示在下圖中,其中顯示了在對數字黃金標準數據集進行分類時,隨著閾值(x軸)的調整,兩個模型的精度(y軸)是如何變化的。此外,訓練集和測試集分別位于左側和右側。
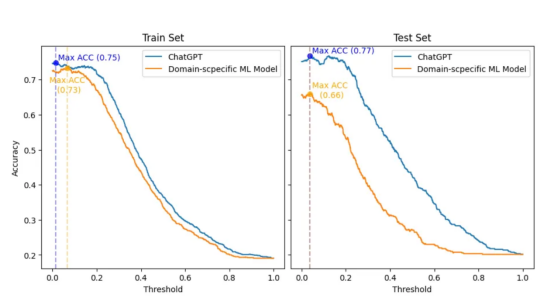
ChatGPT和領域特定ML模型之間的比較,該模型分別考慮了訓練(左側)和測試(右側)集。該計算過程評估了精度(y軸)相對于閾值(x軸)的變化,用于對兩個模型的數字黃金標準數據集進行分類。
首先,我必須承認:我沒想到會有如此驚人的結果。因此,為了對ChatGPT公平起見,我復制了最初的SemEval 2017比賽設置,其中領域特定的ML模型將與訓練集一起構建。然后,實際的排名和比較將只在測試集上進行。
然而,即使在訓練集中,在最有利的情況下(閾值為0.066,而ChatGPT為0.014),領域特異性ML模型的精度也最多比ChatGPT的最佳精度(0.73相對于0.75)低2pp。此外,在訓練和測試集中,ChatGPT在所有閾值上的精度都優于領域特異性模型。
有趣的是,兩種模型的最佳閾值(0.038和0.037)在測試集中極其接近。在這個閾值下,ChatGPT的準確率比領域特定模型高出11pp(0.66比077)。此外,與領域特定模型相比,ChatGPT在閾值變化方面表現出更好的一致性。因此,可以看出,ChatGPT的準確性下降幅度要小得多。
在簡歷中,ChatGPT在準確性上大大優于領域特定ML模型。此外,從這里得到的想法是:ChatGPT可以針對特定任務進行微調。因此,想象一下ChatGPT會變得多么好。
3.3.調查ChatGPT情緒標簽
我一直打算通過舉例說明ChatGPT不準確的地方,并將其與領域特定模型進行比較,來進行更微觀的調查。然而,由于ChatGPT的進展比預期的要好得多,所以我只得選擇繼續調查它錯過了正確情緒的情況。
最初,我進行了與以前類似的評估,但現在立即使用完整的黃金標準數據集。接下來,我選擇了閾值(0.016),用于將黃金標準數值轉換為產生ChatGPT最佳精度(0.75)的正、中性和負標簽。然后,我制作了一個混淆矩陣,其繪制結果如下:
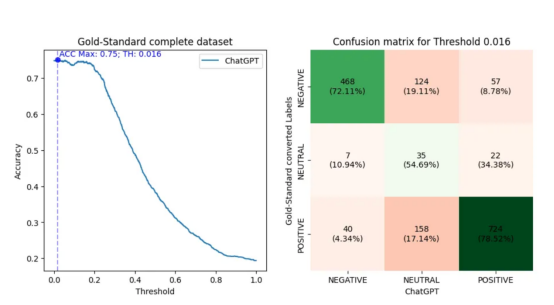
在圖形左側給出的是一條折線圖,用于評估ChatGPT的準確性(y軸)相對于對數字黃金標準完整數據集進行分類的閾值(x軸)是如何變化的。在圖形右側給出的是正、中性和負標簽對應的混淆矩陣,這里假設導致最大ChatGPT性能的閾值為0.016。此外,混淆矩陣還包含根據轉換后的標簽ChatGPT的命中和未命中的百分比。
回想一下,我在前一節中展示了積極得分比消極得分多的數據句子的分布。在混淆矩陣中,觀察到考慮0.016的閾值,有922個(56.39%)陽性句子,649個(39.69%)陰性句子,64個(3.91%)中性句子。
此外,請注意,使用中性標簽時,ChatGPT的準確性較低。這是意料之中的事,因為這些標簽更容易受到閾值限制的影響。有趣的是,ChatGPT傾向于將這些中性句子中的大多數歸類為陽性。然而,由于較少的句子被認為是中性的,這種現象可能與數據集中較大的積極情緒得分有關。
另一方面,當考慮其他標簽時,ChatGPT顯示出正確識別陽性類別比陰性類別多6個百分點的能力(78.52%對72.11%)。在這種情況下,我不確定這與每個分數譜段的句子數量有關。首先,因為每個類別類型的句子要多得多。其次,觀察ChatGPT的未命中次數,這些未命中次數流向相反方向的標簽(從正到負,反之亦然)。同樣,ChatGPT在負面類別中犯了更多這樣的錯誤,數量要少得多。因此,ChatGPT似乎對否定句比對肯定句更感困擾。
3.4.與人類專家的一些具體案例以及比較
我選擇了幾個在黃金標準(人類分數)和ChatGPT之間具有最顯著特殊性的句子。然后,我使用之前建立的相同閾值將數字分數轉換為情緒標簽(0.016)。此外,據報道,ChatGPT的表現優于人類。因此,我調查了這些差異,并給出了我的裁決,我發現無論是人類還是ChatGPT都更準確。
此外,至少從2018年開始,美國國防高級研究計劃局(DARPA)就深入研究了為人工智能決策帶來可解釋性的重要性。引人注目的是,ChatPGT展現了這樣一種能力:它可以解釋自己的決定。這種能力幫助我做出了裁決。下表顯示了此檢查結果。
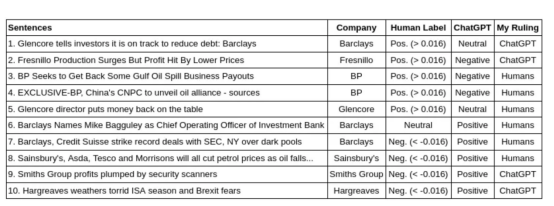
該表顯示了黃金標準標簽(使用0.016閾值從人類專家的分數轉換而來)和ChatGPT之間不匹配的句子示例。此外,我給出了我最同意的裁決。
從我做出有利于人類專家裁決的案例開始。在第3句和第4句的情況下,ChatGPT應該意識到,收回支出和公司聯盟在金融領域通常被認為是有益的。然而,在第7句的情況下,我要求它解釋其決定,以下是ChatGPT的英文回答:
The positive sentiment towards Barclays is conveyed by the word “record,” which implies a significant accomplishment for the company in successfully resolving legal issues with regulatory bodies.
中文意思是:“記錄”一詞表達了對巴克萊銀行的積極情緒,這意味著該公司在成功解決與監管機構的法律問題方面取得了重大成就。
就這句話而言,ChatGPT并不理解,盡管達成創紀錄的交易通常是好的,但美國證券交易委員會是一個監管機構。因此,與美國證券交易委員會達成創紀錄的交易意味著巴克萊和瑞士信貸必須支付創紀錄的罰款。
接下來是第5句和第8句,這些都是非常艱難的判罰。這讓我更明確一點,人類的評估是正確的。然而,事實上,ChatGPT根本猜不到這些。在第5句中,需要及時了解當時的情況,才能理解這句話代表了一個好的結果。對于第8句,需要知道油價下跌與特定目標公司的股價下跌相關。
然后,對于第6句,這是一個情緒得分為零的情況下所能得到的最中性的句子,ChatGPT對其決定英文解釋如下:
The sentence is positive as it is announcing the appointment of a new Chief Operating Officer of Investment Bank, which is a good news for the company.
中文意思是:這句話很積極,因為它宣布任命投資銀行新任首席運營官,這對公司來說是個好消息。
然而,這是一個籠統的、不太有見地的回應,并不能證明為什么ChatGPT認為任命這位高管是好的。因此,在這種情況下,我同意人類專家的意見。
有趣的是,我在第1、2、9和10句中對ChatGPT做出了有利的裁決。此外,仔細觀察,人類專家應該更多地關注目標公司或整體信息。這在第1句中尤其具有象征意義,專家們應該認識到,盡管Glencore公司的情緒是積極的,但目標公司是剛剛撰寫報告的巴克萊銀行。從這個意義上說,ChatGPT更好地識別了這些句子中的情感目標和含義。
4.結論和結果討論
如下表所示,實現這樣的性能需要大量的財政和人力資源。
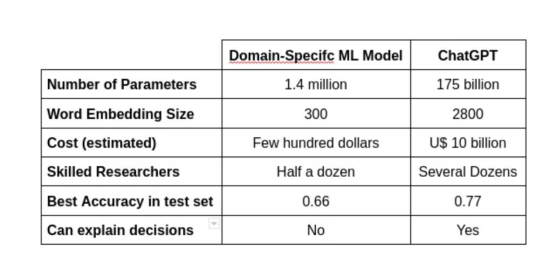
模型各方面的比較,如參數的數量、使用的單詞嵌入大小、成本、構建它的研究人員數量、測試集中的最佳準確性,以及它的決定是否可以解釋。
從這個意義上說,盡管ChatGPT的性能優于特定領域的模型,但最終的比較需要針對特定領域的任務對ChatGPT進行微調。這樣做將有助于解決微調性能的收益是否超過努力成本的問題。
此外,文本模型中最重要的因素之一是單詞嵌入的大小。這項技術自SemEval 2017版以來一直在發展。因此,這一部分中的一些更新可以顯著提高特定領域模型的結果。
另一方面,隨著生成文本模型和LLM的流行,一些開源版本可能有助于組裝一個有趣的未來比較。此外,ChatGPT等LLM解釋其決策的能力是一項杰出的、可以說是出乎意料的成就,可以徹底改變該領域。
5.擴展考慮:如何在應用場景中進行這種比較
不同領域的情緒分析是一項獨立的科學研究。盡管如此,將情緒分析的結果應用于適當的場景可能是另一個科學問題。此外,當我們考慮金融領域的句子時,將情感特征添加到應用智能系統中會很方便。這正是一些研究人員一直在做的事情,我也在進行實驗。
2021年,我和一些同事發表了一篇關于如何在應用場景中使用情緒分析的研究文章。在第二屆ACM金融人工智能國際會議(ICAIF’21)上發表的這篇文章中,我們提出了一種將市場情緒納入強化學習架構的有效方法。這個鏈接提供了實現該體系結構的源代碼,下面顯示了其整體設計的一部分。
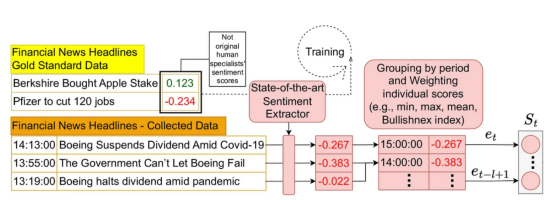
我們所構建的架構示例的一部分,說明如何將市場情緒納入應用場景的強化學習架構中。資料來源:《智能交易系統:一種情緒感知強化學習方法》。第二屆ACM金融人工智能國際會議論文集(ICAIF’21)。作者信息:Lima Paiva, F. C.; Felizardo, L. K.; Bianchi, R. A. d. C. B.; Costa, A. H. R.
該體系結構設計用于處理像黃金標準數據集中那樣的數字情感分數。盡管如此,還是有一些技術(例如,Bullishanex指數)可以將分類情緒轉換為適當的數值,這是由ChatGPT生成的。應用這樣的轉換可以在這樣的體系結構中使用ChatGPT標記的情感。此外,這是在這種情況下你可以做什么的一個例子,也是我打算在未來的分析中做的。
5.1.我研究領域的其他論文(自然語言處理、強化學習有關)
- Lima Paiva, F. C.; Felizardo, L. K.; Bianchi, R. A. d. C. B.; Costa, A. H. R. Intelligent Trading Systems: A Sentiment-Aware Reinforcement Learning Approach. Proceedings of the Second ACM International Conference on AI in Finance (ICAIF ‘21).
- Felizardo, L. K.; Lima Paiva, F. C.; de Vita Graves, C.; Matsumoto, E. Y.; Costa, A. H. R.; Del-Moral-Hernandez, E.; Brandimarte, P. Outperforming algorithmic trading reinforcement learning systems: A supervised approach to the cryptocurrency market. Expert Systems with Applications (2022), v. 202, p. 117259.
- Felizardo, L. K.; Lima Paiva, F. C.; Costa, A. H. R.; Del-Moral-Hernandez, E. Reinforcement Learning Applied to Trading Systems: A Survey. arXiv, 2022.
本文中所使用的資源
主要引用文獻
- Khadjeh Nassirtoussi, A., Aghabozorgi, S., Ying Wah, T., and Ngo, D. C. L. Text mining for market prediction: A systematic review. Expert Systems with Applications (2014), 41(16):7653–7670.
- Loughran, T. and Mcdonald, B. When Is a Liability Not a Liability ? Textual Analysis , Dictionaries , and 10-Ks. Journal of Finance (2011), 66(1):35–65.
- Hamilton, W. L., Clark, K., Leskovec, J., and Jurafsky, D. Inducing domain-specific sentiment lexicons from unlabeled corpora. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 595–605.
- Cortis, K.; Freitas, A.; Daudert, T.; Huerlimann, M.; Zarrouk, M.; Handschuh, S.; Davis, B. SemEval-2017 Task 5: Fine-Grained Sentiment Analysis on Financial Microblogs and News. Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017).
- Davis, B., Cortis, K., Vasiliu, L., Koumpis, A., Mcdermott, R., and Handschuh, S. Social Sentiment Indices Powered by X-Scores. ALLDATA, The Second Inter-national Conference on Big Data, Small Data, Linked Data and Open Data (2016).
- Ferreira, Taynan; Lima Paiva, F. C.; Silva, Roberto da; Paula, Angel de; Costa, Anna; Cugnasca, Carlos. Assessing Regression-Based Sentiment Analysis Techniques in Financial Texts. 16th National Meeting on Artificial and Computational Intelligence (ENIAC), 2019.
譯者介紹
朱先忠,51CTO社區編輯,51CTO專家博客、講師,濰坊一所高校計算機教師,自由編程界老兵一枚。
原文標題:Can ChatGPT Compete with Domain-Specific Sentiment Analysis Machine Learning Models?,作者:Francisco Caio Lima Paiva