K折交叉驗證與GridSearch網格搜索
大家好,我是志斌~
今天跟大家分享一下如何用GridSearch網格搜索和K折交叉認證對決策樹模型進行參數調優。
上一篇文章給大家介紹了決策樹模型的搭建和實戰,當時只用到了一個參數max_depth,但是模型實際上還有其他影響參數,如criterion(特征選擇標準)、class_weight(類別權重)等參數。如果我們想要更精確的結果,那么勢必要對模型參數進行調整,找到最優參數,來構建模型。
1.K折交叉驗證
K折交叉驗證實際上是將一個數據集分成K份,每次選K-1份為訓練集,用剩下的一份為測試集,然后取K個模型的平均測試結果作為最終的模型效果。如下圖所示:
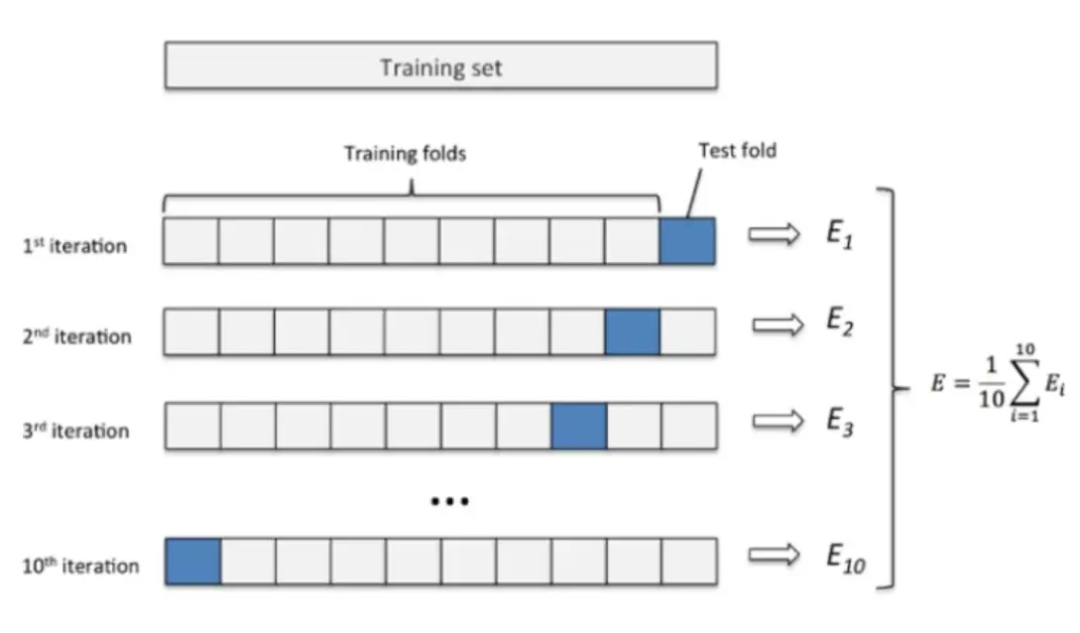
K值的選取跟數據集的大小有關,數據集較小則增大K值,數據集較大則減小K值。實現代碼如下:
from sklearn.model_selection import cross_val_score
acc = cross_val_score(model,X,Y,cv=5)
2.GridSearch網格搜索
GridSearch網格搜索是一種窮舉搜索的參數調優方法,它會遍歷所有的候選參數,并評估每個模型的有效性和準確性,選取最好的參數作為最終結果。
參數調優分為單參數調優和多參數調優,志斌分別給大家舉例介紹一下。
(1)單參數調優
我們以單參數max_depth參數為例,來演示單參數調優,代碼如下:
from sklearn.model_selection import GridSearchCV
param = {'max_depth':[1,3,5,7,9]}
grid_search = GridSearchCV(model,param,scoring='roc_auc',cv=5)grid_search.fit(X_train,Y_train)
輸出參數的最優結果:
grid_search.best_params_
得到max_depth參數的最優結果為:

我們用上面獲得的參數最優值重新搭建模型,來查看AUC值是否得到了提高,代碼如下:
model = DecisionTreeClassifier(max_depth=7)
model.fit(X_train,Y_train)
y_pred_proba = model.predict_proba(X_test)
from sklearn.metrics import roc_auc_score
score = roc_auc_score(Y_test.values,y_pred_proba[:,1])
得到的AUC值為:
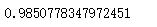
比之前的0.958有所上升,看來模型的準確度有所上升。
(2)多參數調優
決策樹模型有下圖這些參數:
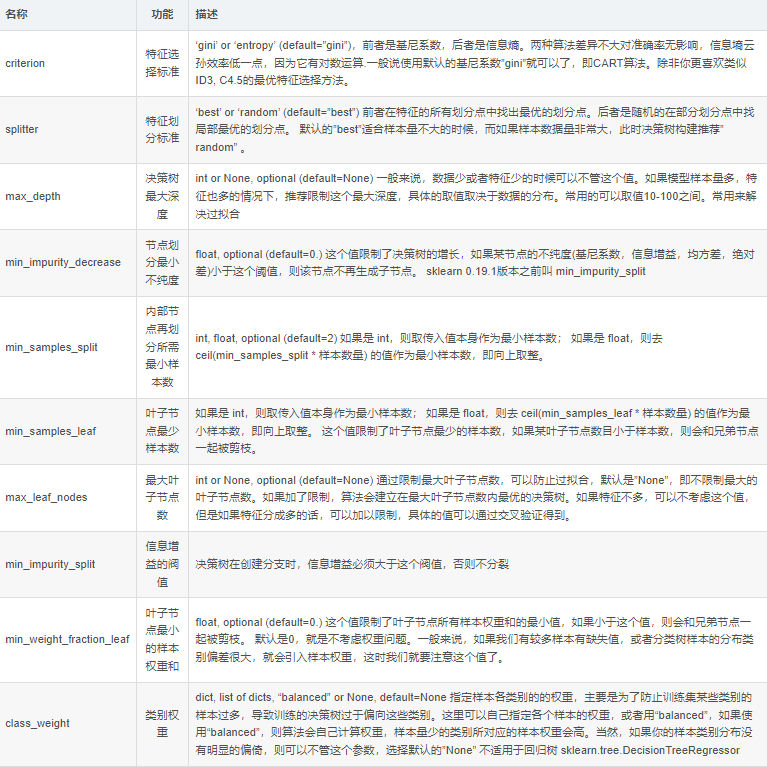
這些參數都會影響我們搭建的決策樹模型的準確性,這里我們以max_depth(最大深度)、criterion(特征選擇標準)、min_samples_split(子節點向下分裂所需最小樣本數),這三個參數為例,來進行多參數調優,代碼如下:
from sklearn.model_selection import GridSearchCV
params = {'max_depth':[5,7,9,11,13],'criterion':['gini','entropy'],'min_samples_split':[5,7,9,11,13,15]}
model = DecisionTreeClassifier()
grid_search = GridSearchCV(model,params,scoring='roc_auc',cv=5)
grid_search.fit(X_train,Y_train)
輸出參數的最優值:
grid_search.best_params_
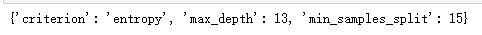
我們用上面獲得的參數最優值重新搭建模型,來查看AUC值是否得到了提高,代碼如下:
model = DecisionTreeClassifier(criterion='entropy',max_depth=13,min_samples_split=15)
model.fit(X_train,Y_train)
y_pred_proba = model.predict_proba(X_test)
from sklearn.metrics import roc_auc_score
score = roc_auc_score(Y_test.values,y_pred_proba[:,1])
得到的AUC值為:
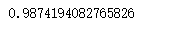
比之前的0.985有所提高,看來模型得到進一步優化。